
You are welcome to browse through our recent and current research results (alphabetical order). A broad and non-exhaustive list of the team’s research topics may be found on our homepage. Some of this research is directly linked to recently submitted or accepted publications that can be found here. Please also refer to our complete list of publications.
Research

Accounting for Room Acoustics in Audio-Visual Multi-Speaker Tracking
Yutong Ban, Xiaofei Li, Xavier Alameda-Pineda, Laurent Girin and Radu Horaud IEEE International Conference on Acoustics, Speech, and Signal Processing, May 2018, Calgary, Canada PDF | Abstract | | Results | Acknowledgements Abstract. Multiple speaker tracking is a crucial task for many applications. In real-world scenario, the complementarity between auditory and visual data opens the …
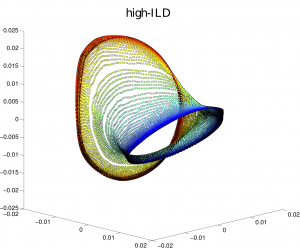
Acoustic Space Learning on Binaural Manifolds
Acoustic Space Learning for Sound-Source Separation and Localization on Binaural Manifolds 2016 IJNS Award for Outstanding Contributions to Neural Systems Antoine Deleforge, Florence Forbes, and Radu Horaud International Journal of Neural Systems, 25 (1), 2015 PDF on arXiv | BibTeX | HAL | Additional papers | Matlab Code | Dataset | Videos and more Abstract In this paper we …
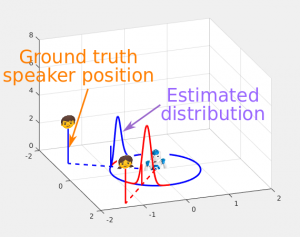
Audio Source Tracking with the von Mises Distribution
Tracking Multiple Audio Sources with the von Mises Distribution and Variational Expectation Maximization Yutong Ban, Xavier Alameda-Pineda, Christine Evers (Imperial College) and Radu Horaud IEEE Signal Processing Letters 26(6), 798 – 802, 2019 | pdf | pdf of supplemental material | code | video Abstract. In this work we address the problem of simultaneously tracking several audio …
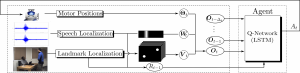
Audio-Visual Gaze Control
Neural Network Based Reinforcement Learning for Audio-Visual Gaze Control in Human-Robot Interaction Stéphane Lathuilière, Benoit Massé, Pablo Mesejo, and Radu Horaud Pattern Recognition Letters, 2018 | arXiv | HAL | Video (scroll down) This paper introduces a novel neural network-based reinforcement learning approach for robot gaze control. Our approach enables a robot to learn and to adapt …

Audio-Visual Multi-Speaker Tracking via Variational Inference
Variational Bayesian Inference for Audio-Visual Tracking of Multiple Speakers Yutong Ban, Xavier Alameda-Pineda, Laurent Girin, and Radu Horaud IEEE Transactions on Pattern Analysis and Machine Intelligence (Early access) arXiv (full paper with appendixes) | Results | Acknowledgements Abstract. In this paper we address the problem of tracking multiple speakers via the fusion of visual …
Audio-Visual Speaker Detection, Localization and Interaction with NAO
Publications | Videos | The NAO Robot Abstract. In this research we address the problem of audio-visual speaker detection. We introduce an online system working on the humanoid robot NAO. The scene is perceived with two cameras and two microphones. A multimodal Gaussian Mixture Model fuses the information extracted from the auditory and visual sensors. The system …

Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion
IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(5), pages 1086-1099, 2018 special issue on Learning with Shared Information for Computer Vision and Multimedia Analysis Israel D. Gebru Sileye Ba Xiaofei Li Radu P. Horaud [PDF on arXiv] [IEEE Xplore] [HAL] [DATASET] [BibTeX][Videos] Abstract. Speaker diarization consists of assigning speech signals to …
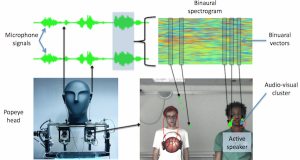
Audio-Visual Speaker Localization Via Weighted Clustering
Abstract. In this paper we address the problem of detecting and locating speakers using audiovisual data. We address this problem in the framework of clustering. We propose a novel weighted clustering method based on a finite mixture model which explores the idea of non-uniform weighting of observations. Weighted-data clustering techniques have already been proposed, but …

Audio-visual Speech-Turn Detection and Tracking
Israel D. Gebru, Sileye Ba, Georgios Evangelidis and Radu Horaud International Conference on Latent Variable Analysis and Independent Component Analysis, 2015 (pdf) Speaker diarization is an important component of multi-party dialog systems in order to assign speech-signal segments among participants. Diarization may well be viewed as the problem of detecting and tracking speech turns. It …
Audio-Visual Tracking by Density Approximation
Audio-Visual Tracking by Density Approximation in a Sequential Bayesian Filtering Framework Israel D. Gebru Christine Evers* Patrick A. Naylor* Radu P. Horaud IEEE Workshop on Hands-free Speech Communication and Microphone Arrays Best Paper Award *Imperial College London [PDF] [Slides] [BibTeX] [Code] [Video] Abstract This paper proposes a novel audio-visual tracking approach that exploits constructively …
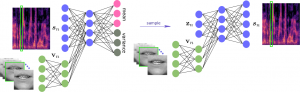
Audio-visual VAE for Speech Enhancement
Audio-visual Speech Enhancement Using Conditional Variational Auto-Encoder Mostafa Sadeghi, Simon Leglaive, Xavier Alameda-Pineda, Laurent Girin, Radu Horaud IEEE/ACM Transactions on Audio, Speech, and Language Processing, volume 28, 2020, 1788-1800 | IEEEXplore | arXiv| Python code Abstract. Variational auto-encoders (VAEs) are deep generative latent variable models that can be used for learning the distribution of complex …

Binaural Hearing for Robots (MOOC by Radu Horaud)
Robots have gradually moved from factory floors to populated areas. Therefore, there is a crucial need to endow robots with perceptual and interaction skills, enabling them to communicate with people in the most natural way. With auditory signals distinctively characterizing physical environments and speech being the most effective means of communication among people, robots must …
Comprehensive Analysis of Deep Regression
Stéphane Lathuilère, Pablo Mesejo, Xavier Alameda-Pineda, and Radu Horaud IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019. Paper available on arXiv. Abstract: Deep learning revolutionized data science, and recently its popularity has grown exponentially, as did the amount of papers employing deep networks. Vision tasks, such as human pose estimation, did not escape from this …
Continuous Action Recognition
Continuous Action Recognition Based on Sequence Alignment Kaustubh Kulkarni, Georgios Evangelidis, Jan Cech and Radu Horaud International Journal of Computer Vision (online) vol. 112, issue 1, March 2015, pp. 90-114 PDF on arXiv | BibTeX: | PDF from HAL | Matlab code | Additional Papers | Videos Abstract: Continuous action recognition is more challenging than isolated recognition because classification and segmentation must be simultaneously carried …
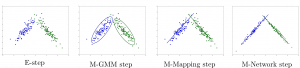
Deep Mixture of Linear Inverse Regressions
Deep Mixture of Linear Inverse Regressions Applied to Head-Pose Estimation Stéphane Lathuilière, Rémi Juge, Pablo Mesejo, Rafael Munoz-Salinas, and Radu Horaud IEEE Conference on Computer Vision and Pattern Recognition, July 2017 [ pdf ] [ code ] [ BibTeX ] Abstract: Convolutional Neural Networks (ConvNets) have become the state-of-the-art for many classification and regression …

Depth (TOF) and Stereo Fusion
Fusion of Range and Stereo Data for High-resolution Scene-modeling IEEE Transactions on Pattern Analysis and Machine Intelligence, vol.37, No.11, 2015, pp. 2178-2192 (IEEE Xplore) G. Evangelidis, M. Hansard, and R. Horaud Abstract This paper addresses the problem of range-stereo fusion, for the construction of high-resolution depth maps. In particular, we combine low-resolution depth data with …
EM Algorithms for Joint Source Separation and Diarisation of Speech
IEEE International Conference on Acoustics, Speech and Signal Processing, 2017 IEEE Workshop on Applications of Signal Processing to Audio Acoustics, 2017 D. Kounades-Bastian, L. Girin, X. Alameda-Pineda, S. Gannot, R. Horaud In this page you can find two EM algorithms for simultaneous separation and diarision of multichannel convolutive audio mixtures. The algorithm on Icassp 2017 …
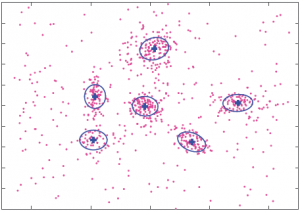
EM Algorithms for Weigthed-Data Clustering with Application to Audio-Visual Scene Analysis
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) Volume 38, number 12, pages 2402 – 2415, December 2016 Israel D. Gebru Xavier Alameda-Pineda Florence Forbes Radu P. Horaud [ PDF on arXiv ] [ PDF on IEEE Xplore ] [ BibTex ] [ CODE & DATASET ] [ …

Extended Gaze Following
Extended Gaze Following: Detecting Objects in Videos Beyond the Camera Field of View Benoit Massé, Stéphane Lathuilière, Pablo Mesejo, Radu Horaud IEEE International Conference on Automatic Face and Gesture Recognition, May 2019, Lille, France Pdf on HAL | supplementary material | Abstract. In this paper, we address the problems of detecting objects of interest in …

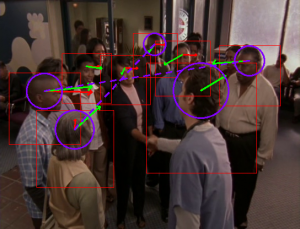
Eye Gaze and Visual Focus
Tracking Gaze and Visual Focus of Attention of People Involved in Social Interaction Benoit Massé, Silèye Ba and Radu Horaud IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(11), 2711-2724, 2018 | IEEEXplore | arXiv | HAL | Code | Demo | Datasets The visual focus of attention (VFOA) has been recognized as a prominent conversational …

Finding Audio-Visual Events in Informal Social Gatherings
by Xavier Alameda-Pineda, Vasil Khalidov, Florence Forbes and Radu Horaud IEEE/ACM International Conference on Multimodal Interaction, 2011 Outstanding Paper Award Abstract In this paper we address the problem of detecting and localizing objects that can be both seen and heard, e.g., people. This may be solved within the framework of data clustering. We propose a new …
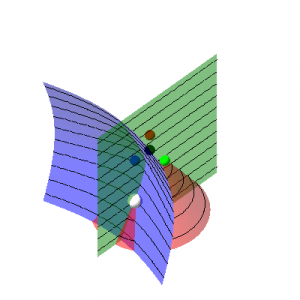
Geometric Sound Source Localization
A Geometric Approach to Sound Source Localization from Time-Delay Estimates Xavier Alameda-Pineda and Radu Horaud IEEE/ACM Transactions on Audio, Speech and Language Processing, 22(6), pages 1082-1095, June 2014 PDF on arXiv | BibTeX | HAL | Matlab toolbox | Additional Papers | Online multimedia Abstract: We address the problem of sound-source localization from time-delay estimates using arbitrarily-shaped non-coplanar microphone arrays. A novel …

Head Pose Estimation
Head Pose Estimation via Probabilistic High-Dimensional Regression Best Student Paper Award (2nd place) V. Drouard, S. Ba, G. Evangelidis, A. Deleforge, and R. Horaud IEEE International Conference on Image Processing (ICIP’15) Extended version published in IEEE Transactions on Image Processing, available on HAL Also, please visit our High-dimensional regression webpage IEEE Publication | HAL Publication …
Head-Pose Tracking
Switching Linear Inverse-Regression Model for Tracking Head Pose V. Drouard, S. Ba, and R. Horaud IEEE Winter Conference on Application of Computer Vision (WACV’17) IEEE Publication | HAL Publication | Abstract | BibTex | Results | Matlab code | Acknowledgement Abstract We propose to estimate the head-pose angles (pitch, yaw, and roll) by simultaneously predicting the …
High-Dimensional Regression
High-Dimensional Regression with Gaussian Mixtures and Partially-Latent Response Variables Statistics and Computing, Springer, 2015, vol. 25, number 5, pages 893-911 Antoine Deleforge, Florence Forbes and Radu Horaud Abstract | arXiv | HAL| Springer | Supplementary materials | Slides | Citation and Bibtex Associated software packages: Matlab toolbox | R code | Python/Keras package Abstract: The problem of approximating high-dimensional data with a …

How To Train Your Deep Multi-Object Tracker
How To Train Your Deep Multi-Object Tracker IEEE Computer Vision and Pattern Recognition Yihong Xu1, Aljoša Ošep2, Yutong Ban1,3 , Radu Horaud1 Laura Leal-Taixé2 , Xavier Alameda-Pineda1 1Inria, LJK, Univ. Grenoble Alpes, France 2Technical University of Munich, Germany 3Distributed Robotics Lab, CSAIL, MIT, USA arxiv | pdf | HAL | code @inproceedings{xu:hal-02534894, TITLE = {How …
Inverse Gamma Source Variance Prior Model for Audio Source Separation
IEEE International Conference on Acoustics, Speech and Signal Processing, 2017 D. Kounades-Bastian, L. Girin, X. Alameda-Pineda, S. Gannot, R. Horaud Abstract In this paper we present a new statistical model for the power spectral density (PSD) of an audio signal and its application to multichannel audio source separation (MASS). The source signal is modeled with …

Joint Registration of Multiple Point Sets
A Generative Model for the Joint Registration of Multiple Point Sets Evangelidis, D. Kounades-Bastian, R. Horaud, E. Psarakis ECCV 2014 Joint Alignment of Multiple Point Sets with Batch and Incremental Expectation-Maximization G. Evangelidis, R. Horaud PAMI 2018 (to appear) Abstract (PAMI version) This paper addresses the problem of registering multiple point sets. Solutions to this …

Learning Piecewise-linear Dynamical Systems
Variational Inference and Learning of Piecewise-linear Dynamical Systems Xavier Alameda-Pineda, Vincent Drouard, and Radu Horaud Submitted to IEEE Transactions on Neural Networks and Learning Systems (arXiv) Abstract. Modeling the temporal behavior of data is of primordial importance in many scientific and engineering fields. Baseline methods assume that both the dynamic and observation equations follow linear-Gaussian …
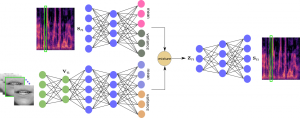
Mixture of Inference Networks for Audio-visual Speech Enhancement
Mixture of Inference Networks for VAE-based Audio-visual Speech Enhancement Mostafa Sadeghi and Xavier Alameda-Pineda Paper | Audio examples | Acknowledgement Abstract In this paper, we are interested in unsupervised (unknown noise) speech enhancement using latent variable generative models. We propose to learn a generative model for clean speech spectrogram based on a variational autoencoder (VAE) where a …
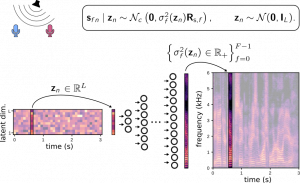
Multichannel speech enhancement with VAE and NMF
Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization Simon Leglaive, Laurent Girin, Radu Horaud IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Brighton, UK, 2019 Article | Bibtex | Slides | Code | Audio examples | Acknowledgement Abstract In this paper we address speaker-independent multichannel speech enhancement in unknown noisy environments. Our work is …
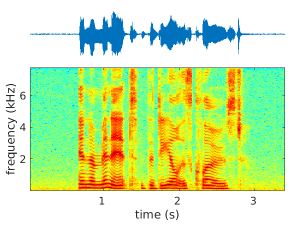
Narrow-band Deep Filtering for Multichannel Speech Enhancement
Xiaofei Li and Radu Horaud, Submitted to IEEE Transactions on Audio, Speech and Language Processing. Short version presented at IEEE WASPAA, October 2019, New Paltz, NY, USA. [Submitted pdf] [WASPAA pdf] [WASPAA slides] [code][audio examples] Abstract. In this paper we address the problem of multichannel speech enhancement in the short-time Fourier transform (STFT) domain and in the framework …
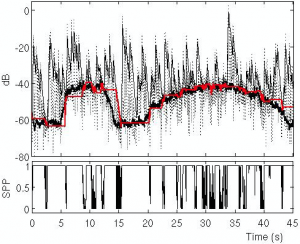
Noise Power Spectral Density Estimation
Non-stationary Noise Power Spectral Density Estimation Based on Regional Statistics Xiaofei Li, Laurent Girin, Sharon Gannot and Radu Horaud The 41th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016. [HAL] [ pdf ] [ Matlab code ] Abstract Estimating the noise power spectral density (PSD) is essential for single channel speech enhancement …
ODA-Track: Online Deep Appearance for Robotic Multiple Person Tracking
Experimental setting: The following results aims to provide a qualitative evaluation of the performance of our proposed method. The left panel reports the set of detection provided by the face detector (in blue), the middle panel the tracking results (in green) produced with color histogram-based appearance model, and on the right the results produced by …
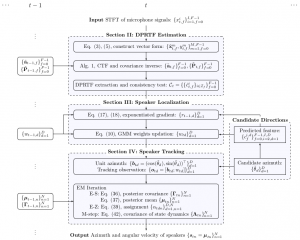
Online Localization and Tracking of Multiple Moving Speakers
Online Localization and Tracking of Multiple Moving Speakers in Reverberant Environments Xiaofei Li*, Yutong Ban*, Laurent Girin, Xavier Alameda-Pineda and Radu Horaud IEEE Journal of Selected Topics in Signal Processing, 2019, 13 (1), pp.88-103. | pdf from arXiv | IEEEXplore | code | dataset Abstract. We address the problem of online localization and tracking of multiple …
Online Speech Enhancement
Online Monaural Speech Enhancement using Delayed Subband LSTM Xiaofei LI, Westlake University, China, and Radu Horaud Paper submitted to INTERSPEECH 2020, Shangai, China | Speech enhancement examples from the DNS challenge Abstract. This paper proposes a delayed subband LSTM network for online monaural (single-channel) speech enhancement. The proposed method is developed in the short time Fourier …
Online Variational Bayesian Tracking (OBVT)
On-line Variational Bayesian Model for Multi-Person Tracking from Cluttered Scenes Sileye Ba, Yutong Ban, Xavier Alameda-PIneda, Alessio Xompero, and Radu Horaud Official benchmark results of the MOT Challenge 2016 Abstract. Object tracking is an ubiquitous problem in computer vision with many applications in human-machine and human-robot interaction, augmented reality, driving assistance, surveillance, etc. Although thoroughly …
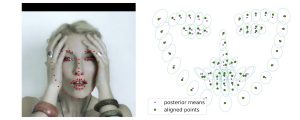
Performance Analysis of 3D Face Alignment with a Statistically Robust Confidence Test
Mostafa Sadeghi, Xavier Alameda-Pineda and Radu Horaud Paper submitted to IEEE Transactions on Image Processing Code and Data Abstract. We address the problem of analyzing the performance of 3D face alignment (3DFA) algorithms. Traditionally, performance analysis relies on carefully annotated datasets. Here, these annotations correspond to the 3D coordinates of a set of pre-defined facial …

Person Re-Identification with Conditional Adversarial Network
CANU-ReID: A Conditional Adversarial Network for Unsupervised person Re-IDentification Guillaume Delorme1 , Yihong Xu1, Stéphane Lathuilière2, Radu Horaud1, Xavier Alameda-Pineda1 1Inria, LJK, Univ. Grenoble Alpes France 2LTCI, Télécom Paris, IP Paris, France International Conference on Pattern Recognition, Milano, Italy, January 2021 arXiv | HAL | poster | slides | code Abstract: Unsupervised person …

Plane-extraction from depth-data
Plane-extraction from depth-data using a Gaussian mixture regression model Richard Marriott, Alexander Pashevich, and Radu Horaud Pattern Recognition Letters, volume 110, pages 44-50, July 2018 | arXiv | HAL | BibTeX |Matlab code Abstract: We propose a novel algorithm for unsupervised extraction of piecewise planar models from depth data. Among other applications, such models are …
Point Registration with Expectation-Maximization
Rigid and Articulated Point Registration with Expectation Conditional Maximization Radu Horaud, Florence Forbes, Manuel Yguel, Guillaume Dewaele, and Jian Zhang IEEE Transactions on Pattern Analysis and Machine Intelligence, 33 (3), 587-602, March 2011 Abstract | code | pdf from HAL | IEEEXplore | Bibtex | Video of a toy example Abstract. This paper addresses the …
Recognition of Group Activities in Videos
Recognition of Group Activities in Videos Based on Single- and Two-Person Descriptors Stéphane Lathuilière, Georgios Evangelidis, Radu Horaud IEEE Winter Conference on Application of Computer Vision (WACV’17) IEEE Publication | HAL Publication | Abstract | BibTex | Results | Acknowledgement Abstract Group activity recognition from videos is a very challenging problem that has barely been addressed. …
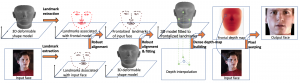
Robust Face Frontalization
Face Frontalization Based on Robustly Fitting a Deformable Shape Model to 3D Landmarks Zhiqi Kang, Mostafa Sadeghi, and Radu Horaud Submitted to IEEE Transactions on Multimedia (arXiv) Abstract. Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution of this paper is a robust face alignment method that enables pixel-to-pixel warping. …
Scene Flow Estimation
Scene Flow Estimation by Growing Correspondence Seeds Jan Cech, Jordi Sanchez-Rieira, and Radu Horaud IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3129-3136, 2011 Abstract | Code | HAL | IEEEXplore | Bibtex | Video | Papers Software package as a Matlab toolbox (source code of binaries) available from Jan Cech’s website or here. Abstract. A simple seed growing algorithm for estimating …
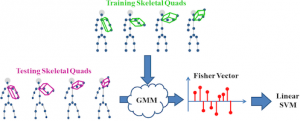
Skeletal Quads
Human Action and Gesture Recognition Using Joint Quadruples Description | Publications | Code G. Evangelidis, G. Singh, R. Horaud Description Recent advances on human motion analysis have made the extraction of human skeleton structure feasible, even from single depth images. This structure has been proven quite informative for discriminating actions in a recognition scenario. In …
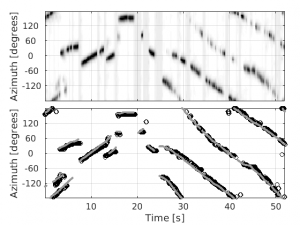
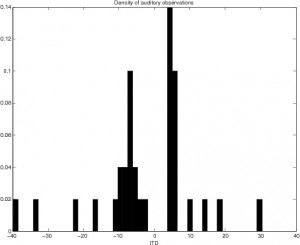
Speaker Localization in Reverberant Environments
Xiaofei Li, Laurent Girin, Sharon Gannot and Radu Horaud Abstract | Papers | Examples | Slides Abstract. We address the problem of localization of single and multiple speech sources in reverberant and noisy rooms. The interchannel response (two microphones) corresponding to the direct-path propagation of an audio source is a function of the source direction. In practice, …
Speech Dereverberation
Multichannel Online Dereverberation based on Spectral Magnitude Inverse Filtering Xiaofei Li, Laurent Girin, Sharon Gannot, Radu Horaud IEEE/ACM Transactions on Audio, Speech and Language Processing, 27 (9), pp. 1365 – 1377, 2019. [pdf] [matlab code] Abstract. This paper addresses the problem of multichannel online dereverberation. The proposed method is performed in the short-time Fourier transform …

Speech enhancement with VAE and alpha-stable distributions
Speech enhancement with variational autoencoders and alpha-stable distributions Simon Leglaive, Umut Şimşekli, Antoine Liutkus, Laurent Girin, Radu Horaud IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Brighton, UK, 2019 Article | Bibtex | Poster | Code | Audio examples | Acknowledgement Abstract This paper focuses on single-channel semi-supervised speech enhancement. We learn a speaker-independent deep generative speech model using the …

Supervised Sound-Source Localization
Co-Localization of Audio Sources in Images Using Binaural Features and Locally-Linear Regression Antoine Deleforge, Radu Horaud, Yoav Y. Schechner and Laurent Girin. IEEE/ACM Transactions on Audio, Speech and Language Processing, 23(4), 718-731, April 2015 Abstract | Videos | Dataset | Matlab code | pdf from HAL | IEEE Xplore | Bibtex Setup: Two microphones plugged into the …

Switching VAEs
Switching Variational Auto-Encoders for Noise-Agnostic Audio-visual Speech Enhancement Mostafa Sadeghi and Xavier Alameda-Pineda Paper Abstract Recently, audio-visual speech enhancement has been tackled in the unsupervised settings based on variational auto-encoders (VAEs), where during training only clean data is used to train a generative model for speech, which at test time is combined with a noise …
Three-Dimensional Sensors
Depth Cameras and Associated Computer Vision Methods Radu Horaud (INRIA), Miles Hansard (QMUL), and Georgios Evangelidis (DAQRI) The emergence of three-dimensional sensors, e.g., Microsoft Kinect v1 and v2, Asus Xtion Pro Live (structered-light sensors), Mesa Imaging SR4000, or Velodyne HDL-64 laser range finder, to cite just a few, have introduced a revolution in the …
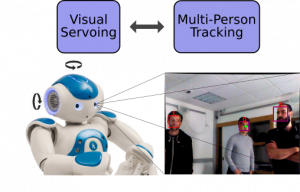
Tracking and Visual Servoing
Tracking a Varying Number of People with a Visually-Controlled Robotic Head Y.Ban, X. Alameda-Pineda, F. Badeig, S. Ba, and R. Horaud IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’17) Novel Technology Paper Award Finalist PDF | Abstract | | Slides | Results | Acknowledgements Abstract Multi-person tracking (MOT) using a robot platform is of …
Tracking the Active Speaker Based on Joint Audio-Visual Observation
IEEE International Conference on Computer Vision Workshops, Dec 2015 Israel D. Gebru Sileye Ba Georgios Evangelidis Radu P. Horaud [ PDF ] [ BibTex ] [ VIDEO ] [ DATASET ] Abstract Any multi-party conversation system benefits from speaker diarization, that is, the assignment of speech signals among …
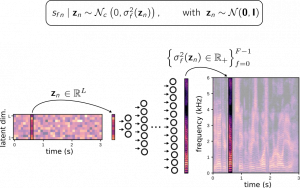
VAE for Audio-visual Speech Separation
Deep Variational Generative Models for Audio-visual Speech Separation Viet-Nhat Nguyen, Mostafa Sadeghi, Elisa Ricci, and Xavier Alameda-Pineda Paper | Audio examples Abstract In this paper, we are interested in audio-visual speech separation given a single-channel audio recording as well as visual information (lips movements) associated with each speaker. We propose an unsupervised technique based on audio-visual …
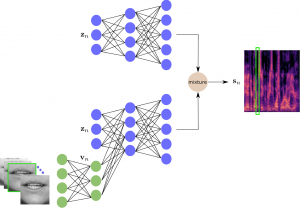
VAE mixture for robust speech enhancement
Robust Unsupervised Audio-visual Speech Enhancement Using a Mixture of Variational Autoencoders Mostafa Sadeghi and Xavier Alameda-Pineda Abstract. Recently, an audio-visual speech generative model based on variational autoencoder (VAE) has been proposed, which is combined with a non-negative matrix factorization (NMF) model for noise variance to perform unsupervised speech enhancement. Although this method shows much better …
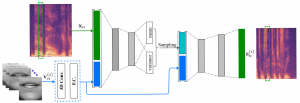
Variance Modeling Based on VAEs for Speech Enhancement
A variance modeling framework based on variational autoencoders for speech enhancement Simon Leglaive, Laurent Girin, Radu Horaud IEEE International Workshop on Machine Learning for Signal Processing (MLSP), Aalborg, Denmark, September 2018 Article | Supporting document | Bibtex | Slides | Code | Audio examples | Acknowledgement Abstract In this paper we address the problem of enhancing speech signals in noisy mixtures using a source …
Variational EM for the Separation of Time-Varying Convolutive Mixtures
IEEE/ACM Transactions on Audio, Speech and Language Processing D. Kounades-Bastian, L. Girin, X. Alameda-Pineda, S. Gannot, R. Horaud Abstract This paper addresses the problem of separating audio sources from time-varying convolutive mixtures. We propose a probabilistic framework based on the local complex-Gaussian model combined with non-negative matrix factorization. The time-varying mixing filters are modeled by …
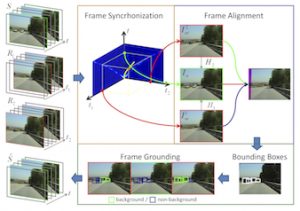
Video Grounding
From Video Matching to Video Grounding G. Evangelidis, F. Diego, R. Horaud Abstract This paper addresses the background estimation problem for videos captured by moving cameras, referred to as video grounding. It essentially aims at reconstructing a video, as if it would be without foreground objects, e.g. cars or people. What differentiates video grounding from …
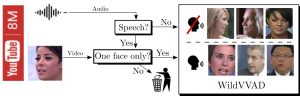
Visual Voice Activity Detection
Learning Visual Voice Activity Detection with an Automatically Annotated Dataset Sylvain Guy, Stéphane Lathuilière, Pablo Mesejo and Radu Horaud International Conference on Pattern Recognition, January 2021, Milano, Italy Paper | | Dataset Abstract. Visual voice activity detection (V-VAD) uses visual features to predict whether a person is speaking or not. V-VAD is useful whenever audio VAD …