
Learning Visual Voice Activity Detection with an Automatically Annotated Dataset
Sylvain Guy, Stéphane Lathuilière, Pablo Mesejo and Radu Horaud
International Conference on Pattern Recognition, January 2021, Milano, Italy

Abstract. Visual voice activity detection (V-VAD) uses visual features to predict whether a person is speaking or not. V-VAD is useful whenever audio VAD (A-VAD) is inefficient, either because the acoustic signal is difficult to analyze or because it is simply missing. We propose two deep architectures for V-VAD, one based on facial landmarks and one based on optical flow. Moreover, available datasets, used for learning and for testing V-VAD, lack content variability. We introduce a novel methodology to automatically create and annotate very large datasets in-the-wild – WildVVAD – based on combining A-VAD with face detection. A thorough empirical evaluation shows the advantage of training the proposed deep V-VAD models with this dataset.
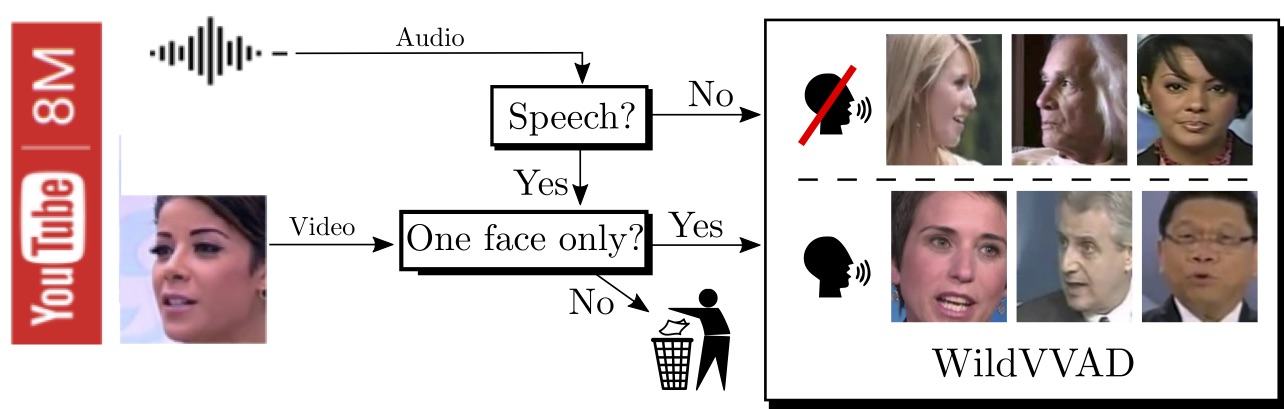
Dataset. The automatically generated and annotated WildVVAD dataset is publicly available. It contains 12,000 video clips of approximately two seconds:
- Speaking videos: http://perception.inrialpes.fr/Free_Access_Data/WVVAD/speaking_videos.zip
- Silent videos: http://perception.inrialpes.fr/Free_Access_Data/WVVAD/silent_videos.zip