

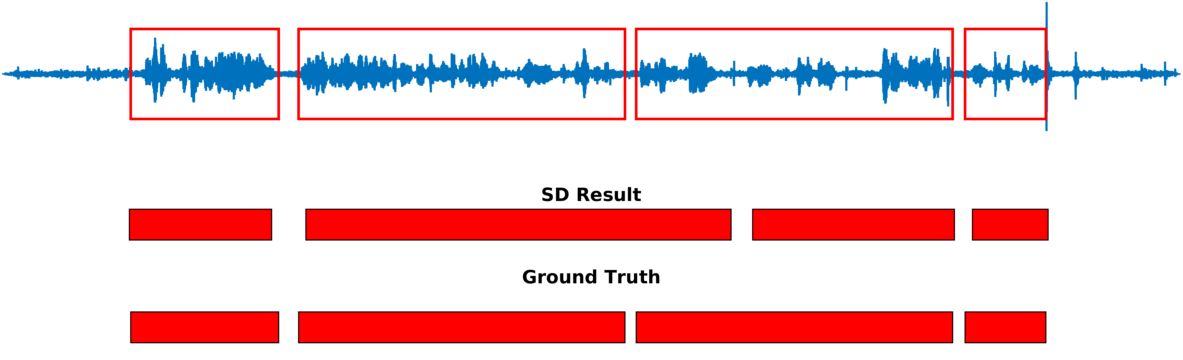
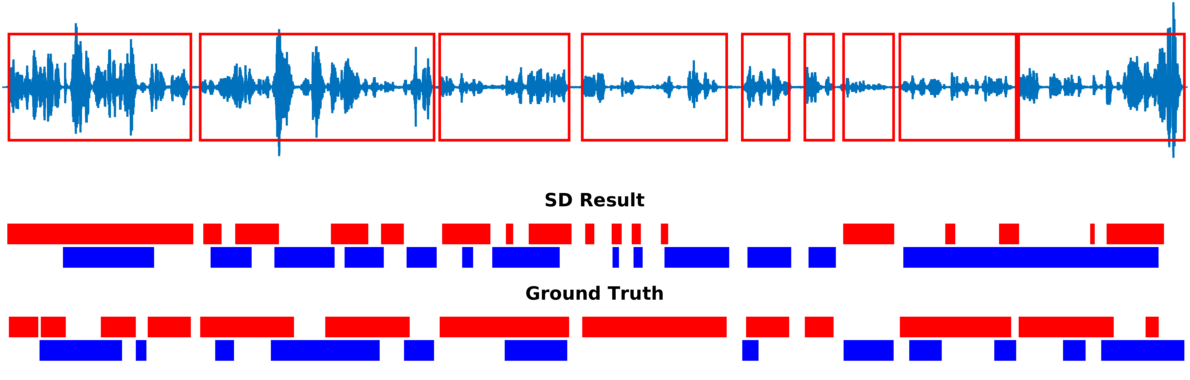
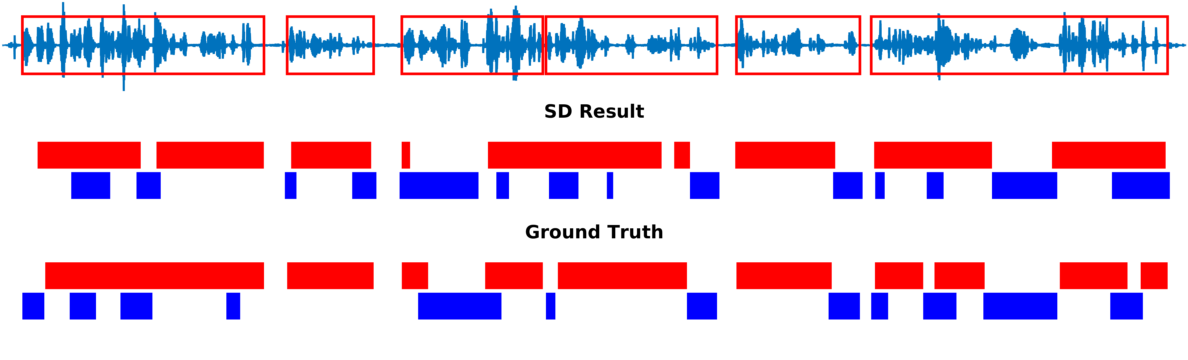
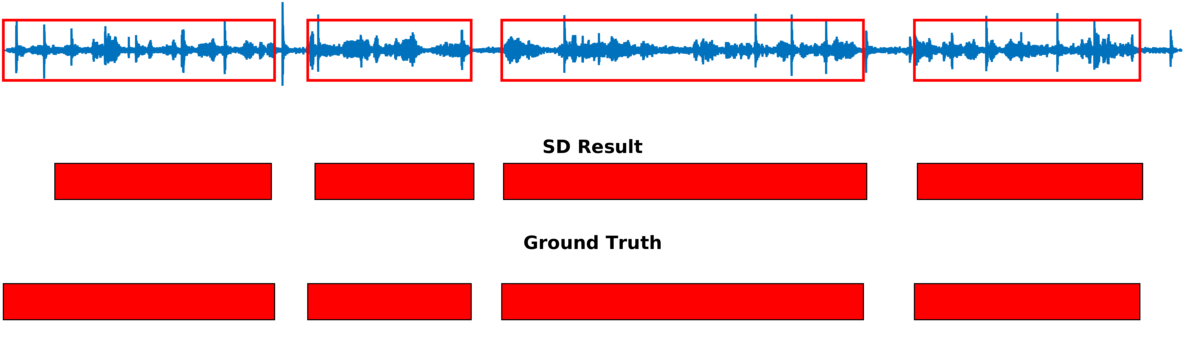
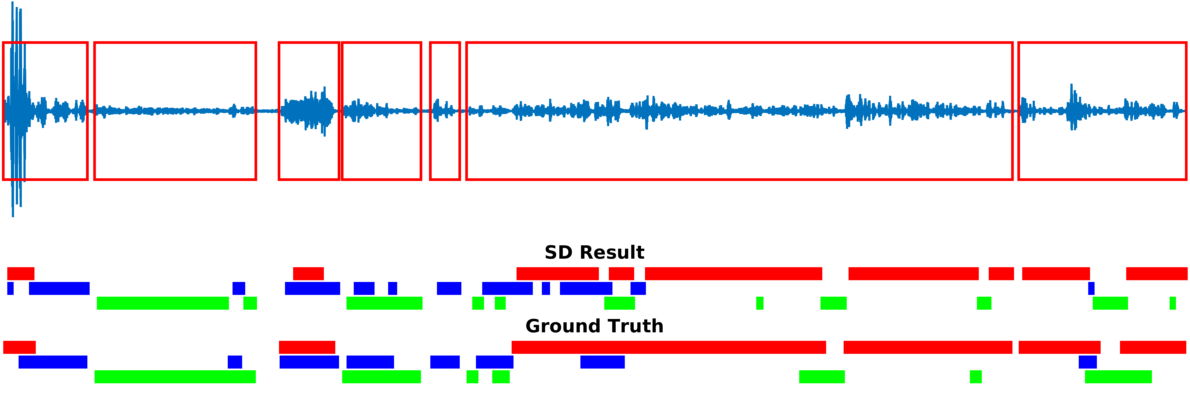
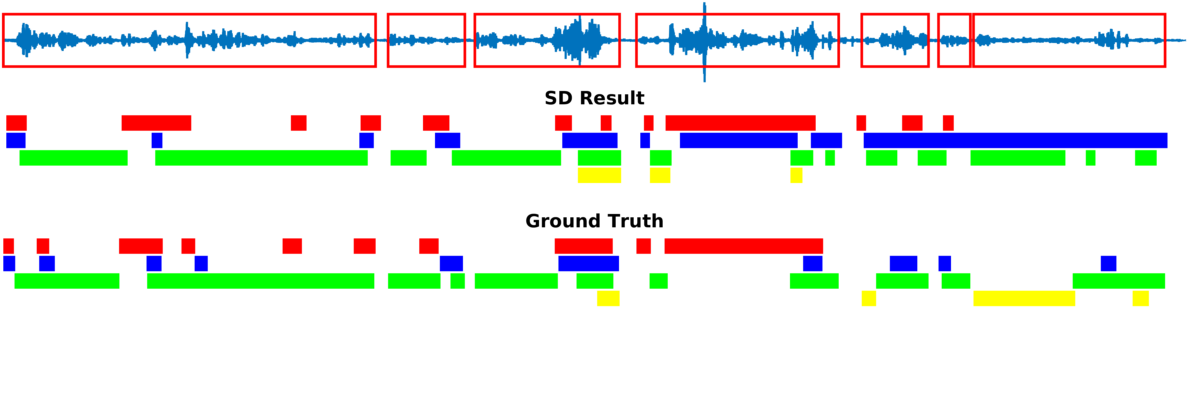
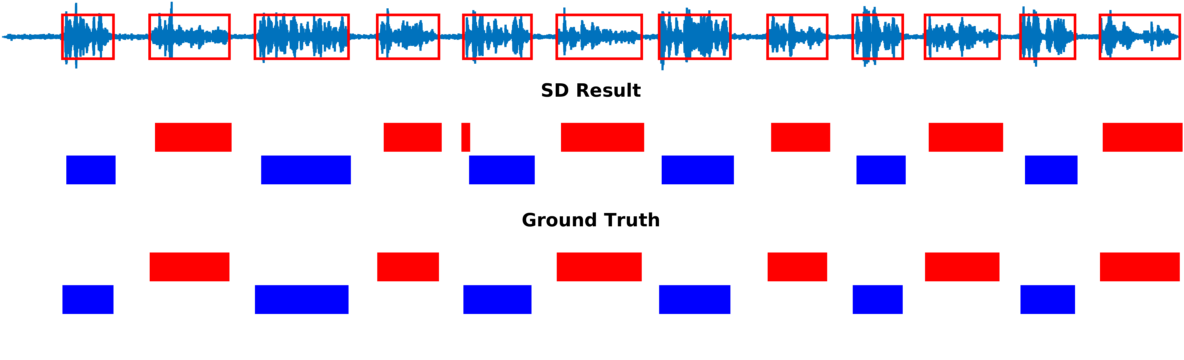
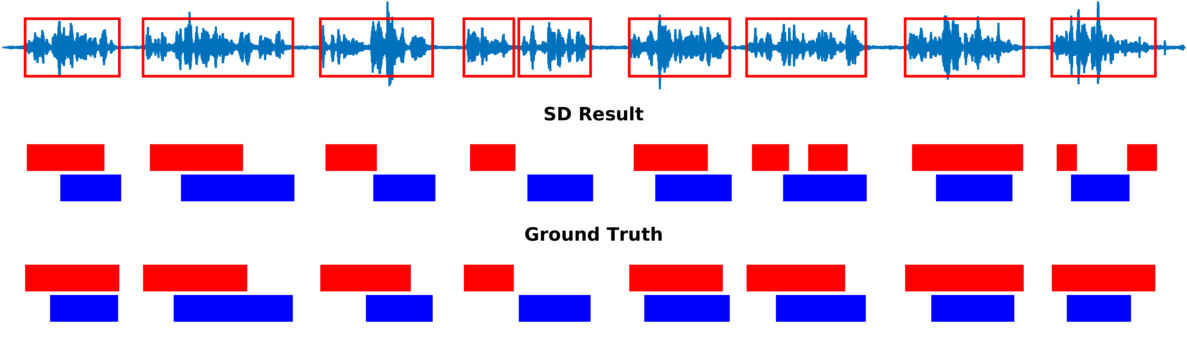
Multiple-person tracking (first row), speech activity is marked with red boxes overlapped onto the raw microphone signal (second row), speaker diarization (SD) obtained with the proposed method (third row), and ground truth diarization (fourth row).
Abstract. Speaker diarization consists of assigning speech signals to speakers engaged in dialog. An audio-visual spatiotemporal diarization model is proposed. The model is well suited for challenging scenarios that consist of several participants engaged in multi-party dialog while they move around and turn their heads towards the other participants rather than facing the cameras and the microphones. Multiple-person visual tracking is combined with multiple speech-source localization in order to tackle the person-to-speech association problem. The latter is solved within a novel audio-visual fusion method on the following grounds: binaural spectral features are first extracted from a microphone pair, then a supervised audio-visual alignment technique maps these features onto an image, and finally a semisupervised clustering method assigns binaural spectral features to visible persons. The main advantage of this method over previous work is that it processes in a principled way speech signals uttered simultaneously by multiple persons. The diarization itself is cast into a latent-variable temporal graphical model that infers speaker identities and speech turns, based on the output of the audio-visual association process available at each time slice, and on the dynamics of the diarization variable itself. The proposed formulation yields an efficient exact inference procedure. A novel dataset, that contains audio-visual training data as well as a number of scenarios involving several participants engaged in formal and informal dialog, is introduced. The proposed method is thoroughly tested and benchmarked with respect to several state-of-the art diarization algorithms.
BibTeX
@article{gebru2018audiovisual,
TITLE={Audio-Visual Speaker Diarization Based on Spatiotemporal {Bayesian} Fusion},
AUTHOR={Gebru, Israel D. and Ba, Sil{\`e}ye and Li, Xiaofei and Horaud, Radu},
JOURNAL={IEEE Transactions on Pattern Analysis and Machine Intelligence},
VOLUME = {40},
NUMBER = {5},
PAGES = {1086-1099},
YEAR = {2018},
DOI={10.1109/TPAMI.2017.2648793},
}
Dataset
The AVDIAR dataset can be downloaded from here.
Videos and Results
Below are some of our results on AVDIAR dataset. The digit displayed on top of a person head represents the “person identity” as maintained by a visual tracker. The probability that a person speaks is shown as a heat map overlaid on the person’s face. The hot colors represent the most probable speaker. The figures on the right show:
- the raw audio signal delivered by the left microphone and the speech activity region is marked with red rectangles.
- SD Result: speaker diarization result illustrated with a color diagram: each color corresponds to the speaking activity of a different person.
- Ground Truth: annotated ground-truth diarization.
|
Seq01-1P-S0M1 |
|
 |
|
|
Seq20-2P-S1M1 |
|
 |
|
|
Seq21-2P-S1M1 |
|
 |
|
|
Seq22-1P-S0M1 |
|
 |
|
|
Seq27-3P-S2M1 |
|
 |
|
|
Seq32-4P-S1M1 |
|
 |
|
|
Seq37-2P-S0M0 |
|
 |
|
|
Seq40-2P-S1M0 |
|
 |
|
|
Seq44-2P-S2M0 |
|
 |
|
Related publications
[1] Gebru, I. D., Ba, S., Evangelidis, G., & Horaud, R., Audio-Visual Speech-Turn Detection and Tracking. In Latent Variable Analysis and Signal Separation, LVA/ICA 2015. Research Page
[2] Gebru, I. D., Ba, S., Evangelidis, G., & Horaud, R., Tracking the Active Speaker Based on a Joint Audio-Visual Observation Model. In ICCV 2015 workshop on 3D Reconstruction and Understanding with Video and Sound, 2015. Research Page
[3] Gebru, I. D., Alameda-Pineda, X., Horaud, R., & Forbes, F., Audio-visual speaker localization via weighted clustering. In IEEE International Workshop on Machine Learning for Signal Processing, MLSP 2014. Research Page
[4] Gebru, I. D., Alameda-Pineda, X., Forbes, F., & Horaud, R., EM algorithms for weighted-data clustering with application to audio-visual scene analysis. TPAMI Jan 2016. Research Page
Acknowledgements
This research has received funding from the EU-FP7 STREP project EARS (#609465) and ERC Advanced Grant VHIA (#340113).