
AVDIAR: A Dataset for Audio-Visual Diarization
Publicly available dataset in conjunction with paper “Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion“
The AVDIAR dataset is only available for non-commercial use
Introduction
AVDIAR (Audio-Visual Diarization) is a dataset dedicated to the audio-visual analysis of conversational scenes. Publicly available datasets in this field are limited to structured social settings such as round-table meetings and smart-room recordings, where audio-visual cues associated with seated participants can be reliably acquired through the use of a camera network and of a microphone array. The motivation behind the AVDIAR dataset is to enable audio-visual scene analysis of unstructured informal meetings and gatherings. We collected scenarios covering examples of interactions between a group of people engaged in a informal conversations. The scenarios involve participants that are either static and speak or move and speak, in front of a camera-microphone setup placed on a dummy head. In an attempt to record natural human-human interactions, all scenarios were unscripted and participants were allowed to enter, wander around, leave the scene at any time and interrupt each other while speaking. The recordings were performed in a standard reverberant environment.
We recorded 23 sequences over a period of 15 days and with sequence duration ranging from ten seconds to three minutes (~27 minutes in total). We carefully annotated each frame with bounding boxes of faces and of upper-body positions, as well as their identity and speaking activity over the entire sequence duration. The acquisition setup, sequence annotation protocol and content are detailed in [comming soon]. For further information please contact us.

If you use this dataset or any part of it, please cite the following journal paper:
@article{gebru2018audio,
TITLE={Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion},
AUTHOR={Gebru, Israel D. and Ba, Sil{\`e}ye and Li, Xiaofei and Horaud, Radu},
JOURNAL={IEEE Transactions on Pattern Analysis and Machine Intelligence},
VOLUME = {40},
NUMBER = {5},
PAGES = {1086-1099}
YEAR = {2018},
DOI={10.1109/TPAMI.2017.2648793},
}
Recording Setup
The recording setup consists of an acoustic dummy head, six microphones and two color cameras. A tripod is used to rigidly mount the acoustic dummy head and the two cameras. The six microphones are placed on the dummy head, two of them are plugged into the left and right ears, and the other four are on each side of the head. The tripod height is adjusted at eye height of an average person, 1.5 m. This setup is shown on the figure above.
The microphones plugged into the ears are from Sennheiser Triaxial MKE 2002, and the other four are Soundman OKM II Classic Solo microphones. They are all linked to a desktop computer via a Behringer ADA8000 Ultragain Pro-8 digital external sound card with signal sampling rate of 48kHz.
Each color camera is a PointGrey Grasshopper3 unit equipped with a Sony Pregius IMX174 CMOS sensor of size 1.2′′ × 1′′ and a Kowa 6 mm wide-angle lens with a horizontal × vertical field of view of 97◦ × 80◦. The cameras deliver images with a resolution of 1920 × 1200 color pixels at 25 FPS. The cameras were mounted parallel to each other and of 20 cm apart, hence the cameras deliver stereoscopic images that are almost representative of a human-eye view of the scene. The cameras are connected to a single PC and are finely synchronized by an external trigger controlled by software. The audio-visual synchronization was done by using time-stamps delivered by the computer’s internal clock.
With this setup, we recorded 23 different sequences. Twelve different participants were recorded and up to five people are present in each sequence. Each recorded scenario involves speaking participants that are either static or move in front of the camera-microphone unit at a distance varying between 1.0 m and 3.5 m. For the sake of varying the acoustic conditions, we used three different rooms. For each room, both stereo calibration and audio-visual calibration were performed. These calibration files are provided.
Annotations
We provide visual, audio and audio-visual annotations. They are described as follows:
- The visual annotations describe people locations and trajectories. The location of a person is described in the form of a 2D bounding box in each image. We annotated both the head and upper-body bounding boxes of each visible person.The video trajectory of each person is identified by a number which is the same through the entire sequence.
- The audio annotations describe the speech/non-speech status of each person. The speech/non-speech annotation is performed manually by marking the starting and ending times of speech utterances. However, it is very challenging to annotate very short utterances, e.g., back-channel utterances such as “uh-huh”, “oh”, etc. We put extra effort to annotate such short utterances whenever possible, i.e., as long as they are clearly distinguishable in the audio mix and can be heard aloud. In general, we imposed a minimum speech duration of 0.2 seconds and hence any utterance less than 0.2 second is simply ignored and automatically taken as a non-speech segment.
- The audio-visual annotations describe the active speaker identities and locations. For each speech segment a set of target speaker identities is assigned referring back to the people identities defined as part of the visual annotation. The head bounding-box center of the active speaker corresponds to the speech direction of arrival.
The annotation files are provided in file formats commonly used in benchmark testbeds, e.g., CSV files for visual annotations as used in MOT Challenge and NIST RTTM files for audio, and audio-visual annotations.
Data Download
The table below lists the recorded scenarios forming the AVDIAR dataset. In order to easy identify the sequence and its content a systematic name coding is used. The name of each sequence is unique and contains a compact description of its content. For example ”SeqNN-xP-SyMz” has four parts:
- “SeqNN” is the unique identifier of this sequence.
- “xP” describes over all x number of different persons were recorded but not necessarily all visible at the same time.
- “Sy”, y ∈ { 0, 1, 2 } describes the auditory scene, 0 means there is no speech overlap, 1 means very little speech overlaps and 2 means often people speak at the same time and thus there are often long speech turn overlaps.
- ”Mz”, z ∈ { 0, 1 } describes the visual scene, 0 means no or minor occlusion between participants and often the participants are static and face the camera and 1 means people wander around the scene and there are frequent occlusions.
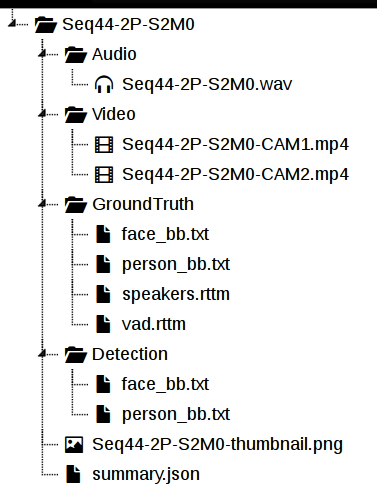
Each sequence is provided in a separate zip file (or folder) and contains:
- A 6-channel audio file in wav format.
- Two video files (one for each camera) encoded in mp4 format with 720×450 pixel resolution. If you require the video files in original resolution, please contact us.
- The ground-truth files as described in the annotation section.
- Face detector [1] and upper-body detector [2] outputs.
- A JSON file containing information about stereo calibration and audio-visual training data.
As an example, the file structure for the sequence Seq44-2P-S2M0 is shown on the figure on the right.
[ Download stereo calibration data ]
[ Download audio-visual training data]
[Download all the audio-visual sequences]
| Sequence Name | Preview | Download Link |
|---|---|---|
|
Seq01-1P-S0M1 |
Download | |
|
|
||
|
Seq02-1P-S0M1 |
Download | |
|
|
||
|
Seq03-1P-S0M1 |
Download | |
|
|
||
|
Seq04-1P-S0M1 |
Download | |
|
|
||
|
Seq05-2P-S1M0 |
Download | |
|
|
||
|
Seq06-2P-S1M0 |
Download | |
|
|
||
|
Seq07-2P-S1M0 |
Download | |
|
|
||
|
Seq08-3P-S1M1 |
Download | |
|
|
||
|
Seq09-3P-S1M1 |
Download | |
|
|
||
|
Seq10-3P-S1M1 |
Download | |
|
|
||
|
Seq12-3P-S1M1 |
Download | |
|
|
||
|
Seq13-4P-S2M1 |
Download | |
|
|
||
|
Seq17-2P-S1M1 |
Download | |
|
|
||
|
Seq18-2P-S1M1 |
Download | |
|
|
||
|
Seq19-2P-S1M1 |
Download | |
|
|
||
|
Seq20-2P-S1M1 |
Download | |
|
|
||
|
Seq21-2P-S1M1 |
Download | |
|
|
||
|
Seq22-1P-S0M1 |
Download | |
|
|
||
|
Seq27-3P-S1M1 |
Download | |
|
|
||
|
Seq28-3P-S1M1 |
Download | |
|
|
||
|
Seq29-3P-S1M0 |
Download | |
|
|
||
|
Seq30-3P-S1M1 |
Download | |
|
|
||
|
Seq32-4P-S1M1 |
Download | |
|
|
||
|
Seq37-2P-S0M0 |
Download | |
|
|
||
|
Seq40-2P-S2M0 |
Download | |
|
|
||
|
Seq43-2P-S0M0 |
Download | |
|
|
||
|
Seq44-2P-S2M0 |
Download | |
References
[1] X. Zhu, & D. Ramanan., “Face detection, pose estimation and landmark localization in the wild”, CVPR 2012.
[2] Lubomir B., Subhransu M., Thomas B., & Jitendra M., “Detecting People Using Mutually Consistent Poselet Activations”, ECCV 2010
[3] I. Gebru and S. Ba and X. Li and R. Horaud, “Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion”, TPAMI Dec 2016
Some of Our Related Works
[A] Gebru, I. D., Ba, S., Evangelidis, G., & Horaud, R., “Audio-Visual Speech-Turn Detection and Tracking”. LVA/ICA 2015. Research Page
[B] Gebru, I. D., Ba, S., Evangelidis, G., & Horaud, R., “Tracking the Active Speaker Based on a Joint Audio-Visual Observation Model”. ICCV 2015. Research Page
[C] Gebru, I. D., Alameda-Pineda, X., Horaud, R., & Forbes, F., “Audio-visual speaker localization via weighted clustering”. MLSP 2014. Research Page
[D] Gebru, I. D., Alameda-Pineda, X., Forbes, F., & Horaud, R., “EM algorithms for weighted-data clustering with application to audio-visual scene analysis”. TPAMI Jan 2016. Research Page
Acknowledgements
This research has received funding from the EU-FP7 STREP project EARS (#609465) and ERC Advanced Grant VHIA (#340113).