
Semi-supervised multichannel speech enhancement with variational autoencoders and non-negative matrix factorization
Simon Leglaive, Laurent Girin, Radu Horaud
IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Brighton, UK, 2019
Article | Bibtex | Slides | Code | Audio examples | Acknowledgement
| In this paper we address speaker-independent multichannel speech enhancement in unknown noisy environments. Our work is based on a well-established multichannel local Gaussian modeling framework. We propose to use a neural network for modeling the speech spectro-temporal content. The parameters of this supervised model are learned using the framework of variational autoencoders. The noisy recording environment is supposed to be unknown, so the noise spectro-temporal modeling remains unsupervised and is based on non-negative matrix factorization (NMF). We develop a Monte Carlo expectation-maximization algorithm and we experimentally show that the proposed approach outperforms its NMF-based counterpart, where speech is modeled using supervised NMF. | 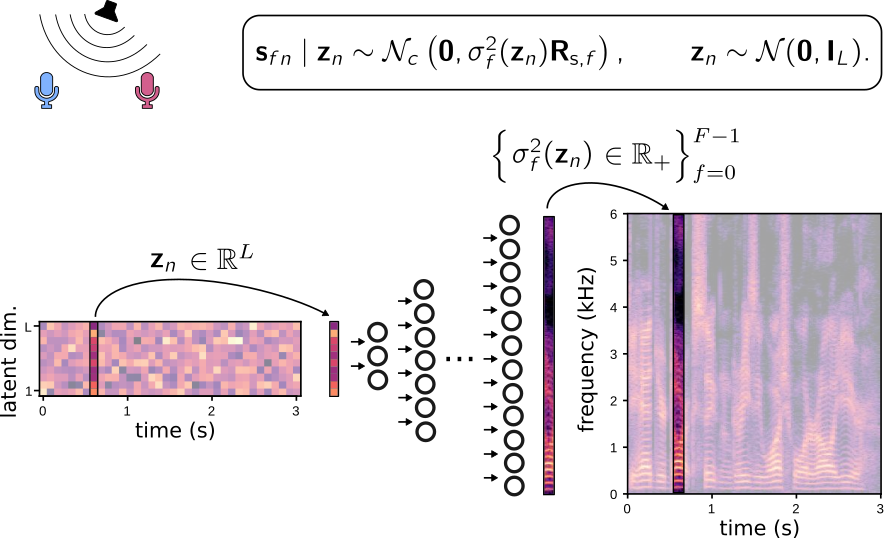 |
The proposed multichannel speech enhancement method is compared with [1]. The noise model for both methods is unsupervised and relies on non-negative matrix factorization (NMF). Its parameters are estimated “on the fly” from the noisy mixture signal only. The speech model for the method [1] is also based on NMF, but in a supervised setting where the dictionary matrix is learned from a training dataset of clean speech signals. The proposed method also exploits a supervised speech model, but it is based on variational autoencoders (see our paper for further details).
The rank of the speech model for [2] and the latent-space dimension for the proposed method are both chosen such that they lead to the best results in terms of median STOI measure.
Noisy speech signals were created at a 0 dB signal-to-noise ratio. We used the TIMIT and DEMAND datasets.
[1] H. Sawada, H. Kameoka, S. Araki, and N. Ueda. “Multichannel extensions of non-negative matrix factorization with complex-valued data”, in IEEE Transactions on Audio, Speech and Language Processing, vol. 21, no. 5, 2013.
| Environment | Noisy speech | Clean speech | Enhanced speech with the baseline method [1] | Enhanced speech with the proposed method |
| Subway |
|
|
|
|
| River |
|
|
|
|
| Meeting |
|
|
|
|
| Restaurant |
|
|
|
|
| Subway station |
|
|
|
|
| Subway station |
|
|
|
|
| Traffic intersection |
|
|
|
|
| Traffic intersection |
|
|
|
|
| Bus |
|
|
|
|
| Car |
|
|
|
|
Bonus experiment on music
In this experiment, we use the above-mentioned methods to separate singing voice from the accompaniment in a piece of stereo music. The song is “Ana” by Vieux Farka Toure and comes from the MTG MASS dataset. The accompaniment is here considered as noise. Note that the speech models for both the baseline [1] and the proposed methods were trained on speaking and not singing voice. This example illustrates the interest of semi-supervised speech enhancement approaches: they do not suffer from generalization issues regarding the noise types. On the contrary, a fully-supervised method will likely have difficulties for generalizing to this singing voice separation task if music was not part of the training noise dataset (see here an example illustrating this generalization issue with a fully-supervised method).
For the baseline method, the rank of the supervised NMF speech model is set to 32 (for this singing voice separation example, this rank led to better results than with a smaller one). For the proposed method, the dimension of the latent space is also set to 32. For both methods, the rank of the unsupervised NMF noise model is set to 10.
| Mixture: |
|
| Original | Baseline method | Proposed method | |
| Singing voice |
|
|
|
| Accompaniment |
|
|
|
This work was supported by the ERC Advanced Grant VHIA #340113.