
Speech enhancement with variational autoencoders and alpha-stable distributions
Simon Leglaive, Umut Şimşekli, Antoine Liutkus, Laurent Girin, Radu Horaud
IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Brighton, UK, 2019
Article | Bibtex | Poster | Code | Audio examples | Acknowledgement
|
This paper focuses on single-channel semi-supervised speech enhancement. We learn a speaker-independent deep generative speech model using the framework of variational autoencoders. The noise model remains unsupervised because we do not assume prior knowledge of the noisy recording environment. In this context, our contribution is to propose a noise model based on alpha-stable distributions, instead of the more conventional Gaussian non-negative matrix factorization approach found in previous studies. We develop a Monte Carlo expectation-maximization algorithm for estimating the model parameters at test time. Experimental results show the superiority of the proposed approach both in terms of perceptual quality and intelligibility of the enhanced speech signal. |
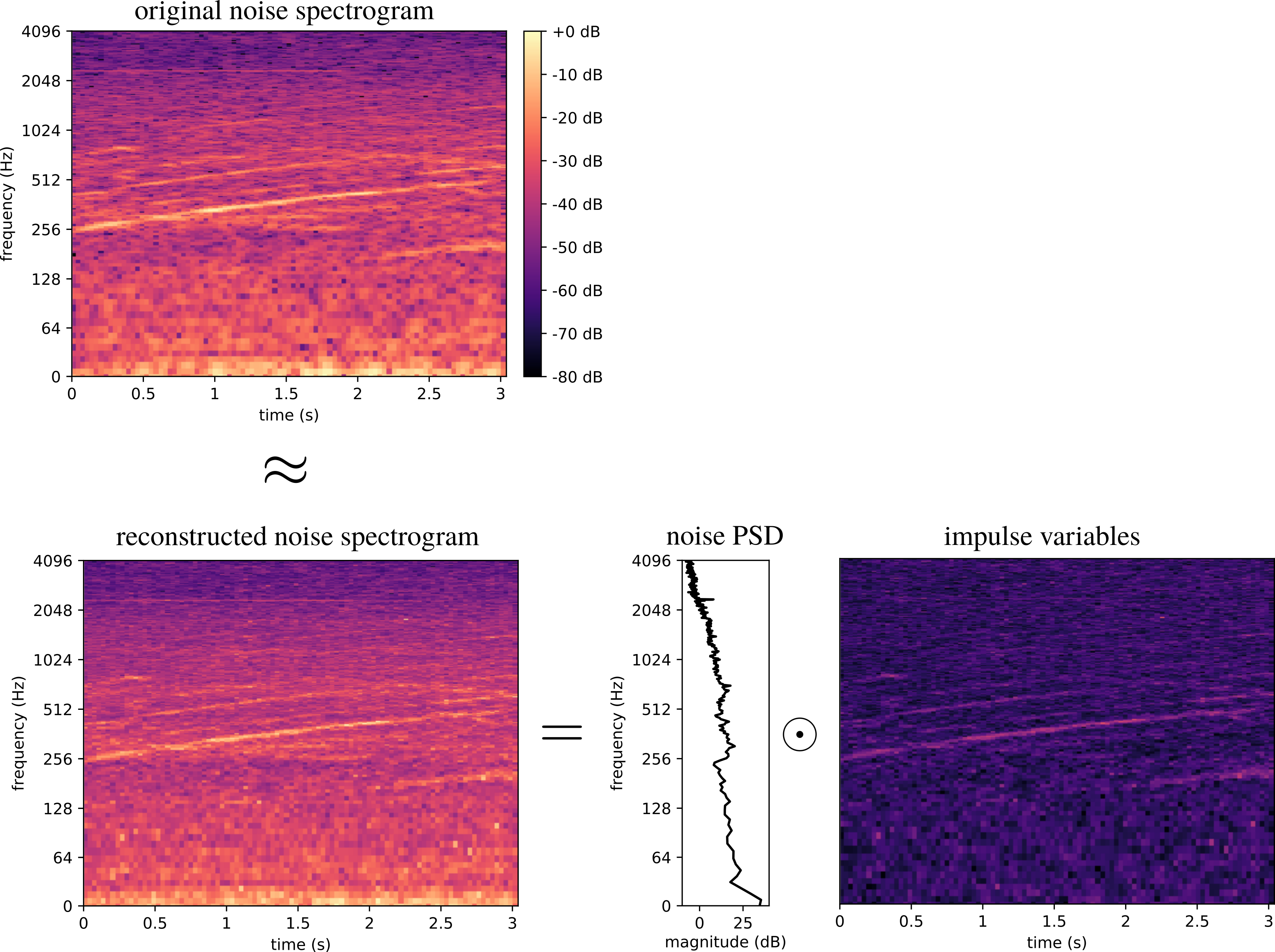 |
The proposed speech enhancement method is compared with [1]. The main difference between the two methods is the unsupervised noise model. The reference method [1] is based on a Gaussian noise model with a non-negative matrix factorization (NMF) parametrization of the variance. In the proposed method, we studied the use of an alpha-stable noise model (without NMF). Both methods rely on a supervised speech model based on variational autoencoders. For further details, please refer to our paper.
Noisy speech signals were created at a 0 dB signal-to-noise ratio. We used the TIMIT and DEMAND datasets.
[1] S.Leglaive, L. Girin, and R. Horaud. “A variance modeling framework based on variational autoencoders for speech enhancement”, in Proc. of the IEEE International Workshop on Machine Learning for Signal Processing (MLSP), 2018.
| Environment | Noisy speech | Clean speech | Enhanced speech with the reference method [1] | Enhanced speech with the proposed method |
| Subway |
|
|
|
|
| Subway |
|
|
|
|
| Kitchen |
|
|
|
|
| Cafeteria |
|
|
|
|
| Town square |
|
|
|
|
| Sports field |
|
|
|
|
| Traffic intersection |
|
|
|
|
This work was supported by the ERC Advanced Grant VHIA #340113.