
Robust Unsupervised Audio-visual Speech Enhancement Using a Mixture of Variational Autoencoders
Mostafa Sadeghi and Xavier Alameda-Pineda
Abstract. Recently, an audio-visual speech generative model based on variational autoencoder (VAE) has been proposed, which is combined with a non-negative matrix factorization (NMF) model for noise variance to perform unsupervised speech enhancement. Although this method shows much better performance compared to audio-only VAE, it is not robust against video occlusions. This is because the associated model is trained on clean and frontal video frames. In this paper, we propose a robust unsupervised audio-visual speech enhancement method based on a VAE mixture model for clean speech spectra. This mixture model consists of a pre-trained audio-only VAE, to be used by occluded video frames, and a pre-trained audio-visual VAE, to be used by clean video frames. We present a variational expectation-maximization method to estimate the parameters of the model. Experiments show the promising performance of the proposed method.
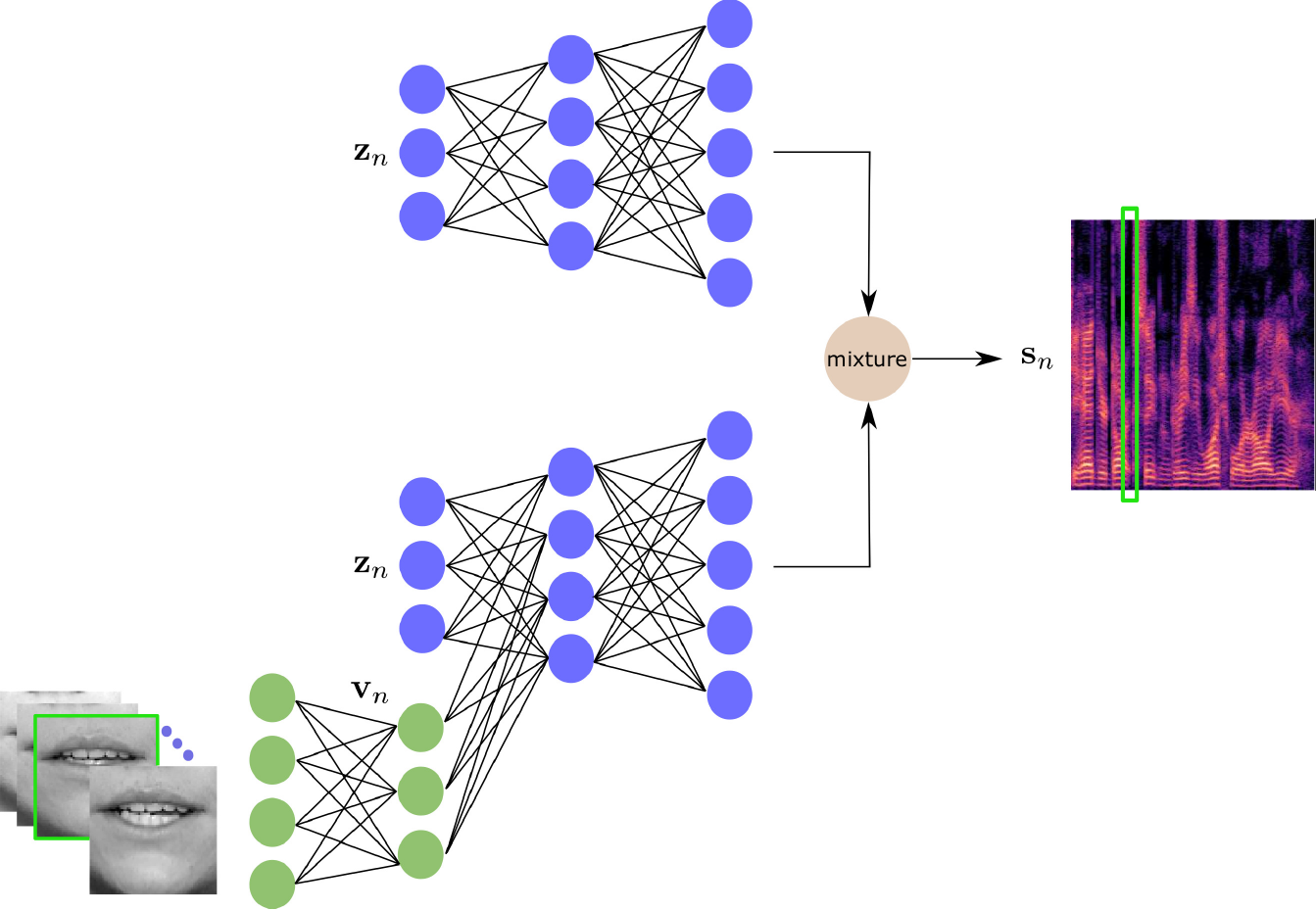
The proposed mixture generative modeling for clean speech. This consists of an audio-only model (the above branch) and an audio-visual model (the bottom branch). The mixture then determines which generative model to use for each speech spectrogram time frame. This is done in an unsupervised way.
Paper
The paper can be downloaded from here.
Supporting document
The supporting document, detailing the variational derivations, can be found here.