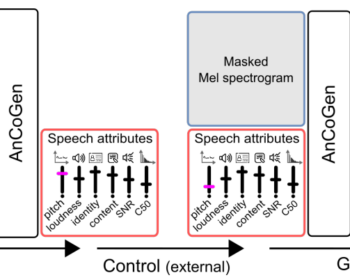
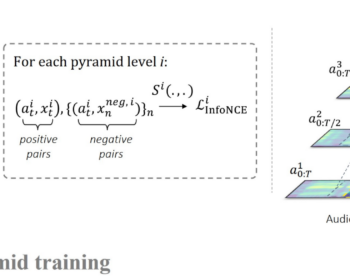Diffusion-based Unsupervised Audio-visual Speech Enhancement
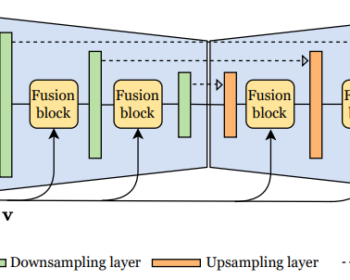
by Jean-Eudes Ayilo, Mostafa Sadeghi, Romain Serizel, Xavier Alameda-Pineda IEEE International Conference on Audio, Speech, and Signal Processing [ paper ] [ code ] Abstract: —This paper proposes a new unsupervised audiovisual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF)…