



A Benchmark of Dynamical Variational Autoencoders applied to Speech Spectrogram Modeling
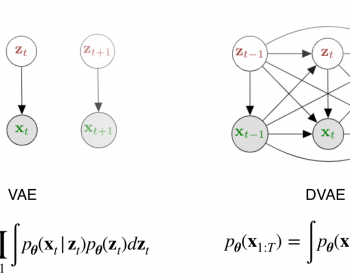
by Xiaoyu Bie, Laurent Girin, Simon Leglaive, Thomas Hueber and Xavier Alameda-Pineda Interspeech’21, Brno, Czech Republic [paper][slides][code][bibtex] Abstract. The Variational Autoencoder (VAE) is a powerful deep generative model that is now extensively used to represent high-dimensional complex data via a low-dimensional latent space learned in an unsupervised manner. In the…