The scientific ambition of RobotLearn is to train robots to acquire the capacity to look, listen, learn, move and speak in a socially acceptable manner. This is being achieved via a fine tuning between scientific findings, development of practical algorithms and associated software packages, and thorough experimental validation. RobotLearn team members plan to endow robotic platforms with the ability to perform physically-unconstrained and open-domain multi-person interaction and communication. The roadmap of RobotLearn is twofold: (i) to build on the recent achievements of the Perception team, in particular, machine learning techniques for the temporal and spatial alignment of audio and visual data, variational Bayesian methods for unimodal and multimodal tracking of humans, and deep learning architectures for audio and audio-visual speech enhancement, and (ii) to explore novel scientific research opportunities at the crossroads of discriminative and generative deep learning architectures, Bayesian learning and inference, computer vision, audio/speech signal processing, spoken dialog systems, and robotics. The paramount applicative domain of RobotLearn is the development of multimodal and multi-party interactive methodologies and technologies for social (companion) robots. RobotLearn is a Research Team at the Inria Center of Université Grenoble Alpes, and is associated with Laboratoire Jean Kuntzman.
You can easily check:
- our publications list,
- the list of open positions in the team,
- the ongoing projects.
Recent contributions
- Univariate Radial Basis Function Layers: Brain-inspired Deep Neural Layers for Low-Dimensional Inputs
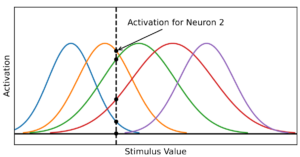
by Daniel Jost, Basavasagar Patil, Xavier Alameda-Pineda, and Chris Reinke
Abstract: Deep Neural Networks (DNNs) became the standard tool for function approximation with most of the introduced architectures being developed for high-dimensional input data. However, many real-world problems have low-dimensional inputs for which the standard Multi-Layer Perceptron (MLP) are a common choice. An investigation into specialized architectures is missing. We propose a novel DNN input layer called the Univariate Radial Basis Function (U-RBF) Layer as an alternative. Similar to sensory neurons in the brain, the U-RBF Layer processes each individual input dimension with a population of neurons whose activations depend on different preferred input values. We verify its effectiveness compared to MLPs and other state-of-the-art methods in low-dimensional function regression tasks. The results show that the U-RBF Layer is especially advantageous when the target function ...
- Autoregressive GAN for Semantic Unconditional Head Motion Generation
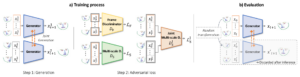
by Louis Airale, Xavier Alameda-Pineda, Stéphane Lathuilière, and Dominique Vaufreydaz
ACM Transactions on Multimedia Tools and Applications
Abstract: We address the task of unconditional head motion generation to animate still human faces in a low-dimensional semantic space. Deviating from talking head generation conditioned on audio that seldom emphasizes realistic head motions, we devise a GAN-based architecture that allows obtaining rich head motion sequences while avoiding known caveats associated with GANs.Namely, the autoregressive generation of incremental outputs ensures smooth trajectories, while a multi-scale discriminator on input pairs drives generation toward better handling of high and low-frequency signals and less mode collapse. We demonstrate experimentally the relevance of the proposed architecture and compare it with models that showed state-of-the-art performances on similar tasks.
- A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning
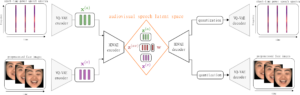
by Samir Sadok, Simon Leglaive, Laurent Girin, Xavier Alameda-Pineda, and Renaud Séguier
Neural Networks
Abstract: In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the modalities from those that are specific to each modality. A static latent variable is also introduced to encode the information that is constant over time within an audiovisual speech sequence. The model is trained in an unsupervised manner on an audiovisual emotional speech dataset, in two stages. In the first stage, a vector quantized VAE (VQ-VAE) is learned independently for each modality, without temporal modeling. The second stage consists of learning the MDVAE model on the intermediate representation of the VQ-VAEs before quantization. The disentanglement between static versus dynamic and modality-specific ...
- Mixture of Dynamical Variational Autoencoders for Multi-Source Trajectory Modeling and Separation
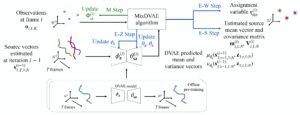
by Xiaoyu Lin, Laurent Girin and Xavier Alameda-Pineda
Transactions on Machine Learning Research
Abstract: In this paper, we propose a latent-variable generative model called mixture of dynamical variational autoencoders (MixDVAE) to model the dynamics of a system composed of multiple moving sources. A DVAE model is pre-trained on a single-source dataset to capture the source dynamics. Then, multiple instances of the pre-trained DVAE model are integrated into a multi-source mixture model with a discrete observation-to-source assignment latent variable. The posterior distributions of both the discrete observation-to-source assignment variable and the continuous DVAE variables representing the sources’ content/position are estimated using the variational expectation-maximization algorithm, leading to multi-source trajectories estimation. We illustrate the versatility of the proposed MixDVAE model on two tasks: a computer vision task, namely multi-object tracking, and an audio processing task, namely single-channel audio source separation. ...
- Unsupervised Performance Analysis of 3D Face Alignment with a Statistically Robust Confidence Test

by Mostafa Sadeghi, Xavier Alameda-Pineda and Radu Horaud
Neurocomputing, volume 564, January 2024
Abstract: We address the problem of analyzing the performance of 3D face alignment (3DFA), or facial landmark localization. Performance analysis is usually based on annotated datasets. Nevertheless, in the particular case of 3DFA, the annotation process is rarely error-free, which strongly biases the analysis. Alternatively, we investigate unsupervised performance analysis (UPA). The core ingredient of the proposed methodology is the robust estimation of the rigid transformation between predicted landmarks and model landmarks. We show that the rigid mapping thus computed is affected neither by non-rigid facial deformations, due to variabilities in expression and in identity, nor by landmark localization errors, due to various perturbations. The guiding idea is to apply the estimated rotation, translation and scale in order to bring the ...- Motion-DVAE: Unsupervised learning for fast human motion denoising

by Guénolé Fiche, Simon Leglaive, Xavier Alameda-Pineda, and Renaud Séguier
ACM SIGGRAPH Conference on Motion, Interaction and Games
Abstract: Pose and motion priors are crucial for recovering realistic and accurate human motion from noisy observations. Substantial progress has been made on pose and shape estimation from images, and recent works showed impressive results using priors to refine frame-wise predictions. However, a lot of motion priors only model transitions between consecutive poses and are used in time-consuming optimization procedures, which is problematic for many applications requiring real-time motion capture. We introduce Motion-DVAE, a motion prior to capture the short-term dependencies of human motion. As part of the dynamical variational autoencoder (DVAE) models family, Motion-DVAE combines the generative capability of VAE models and the temporal modeling of recurrent architectures. Together with Motion-DVAE, we introduce an unsupervised learned denoising method unifying regression- and optimization-based approaches ...
- On the Effectiveness of LayerNorm Tuning for Continual Learning in Vision Transformers
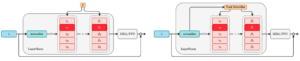
by Thomas De Min, Massimiliano Mancini, Karteek Alahari, Xavier Alameda-Pineda, and Elisa Ricci
ICCV 2023 Workshops
Abstract: State-of-the-art rehearsal-free continual learning methods exploit the peculiarities of Vision Transformers to learn task-specific prompts, drastically reducing catastrophic forgetting. However, there is a tradeoff between the number of learned parameters and the performance, making such models computationally expensive. In this work, we aim to reduce this cost while maintaining competitive performance. We achieve this by revisiting and extending a simple transfer learning idea: learning task-specific normalization layers. Specifically, we tune the scale and bias parameters of LayerNorm for each continual learning task, selecting them at inference time based on the similarity between task-specific keys and the output of the pre-trained model. To make the classifier robust to incorrect selection of parameters during inference, we introduce a two-stage training procedure, where we first optimize the task-specific ...
- A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
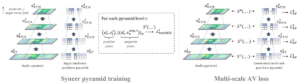
by Louis Airale, Dominique Vaufreydaz, and Xavier Alameda-Pineda
Abstract: Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress. However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected. In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips. In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales. Our generator operates in the facial landmark domain, ...
- Unsupervised speech enhancement with deep dynamical generative speech and noise models

by Xiaoyu Lin, Simon Leglaive, Laurent Girin, and Xavier Alameda-Pineda
Interspeech 2023
Abstract: This work builds on previous work on unsupervised speech enhancement using a dynamical variational autoencoder (DVAE) as the clean speech model and non-negative matrix factorization (NMF) as the noise model. We propose to replace the NMF noise model with a deep dynamical generative model (DDGM) depending either on the DVAE latent variables, on the noisy observations, or both. This DDGM can be trained in three configurations: noise-agnostic, noise-dependent, and noise adaptation after noise-dependent training. Experimental results show that the proposed method achieves competitive performance compared to state-of-the-art unsupervised speech enhancement methods, while the noise-dependent training configuration yields a much more time-efficient inference process.
- Semi-supervised learning made simple with self-supervised clustering

by Enrico Fini, Pietro Astolfi, Karteek Alahari, Xavier Alameda-Pineda, Julien Mairal, Moin Nabi, and Elisa Ricci
IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023
Abstract: Self-supervised learning models have been shown to learn rich visual representations without requiring human annotations. However, in many real-world scenarios, labels are partially available, motivating a recent line of work on semi-supervised methods inspired by self-supervised principles. In this paper, we propose a conceptually simple yet empirically powerful approach to turn clustering-based self-supervised methods such as SwAV or DINO into semi-supervised learners. More precisely, we introduce a multi-task framework merging a supervised objective using ground-truth labels and a self-supervised objective relying on clustering assignments with a single cross-entropy loss. This approach may be interpreted as imposing the cluster centroids to be class prototypes. Despite its simplicity, we provide empirical evidence that our approach is highly effective ...
- Speech Modeling with a Hierarchical Transformer Dynamical VAE
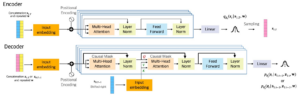
by Xiaoyu Lin, Xiaoyu Bie, Simon Leglaive, Laurent Girin, and Xavier Alameda-Pineda
IEEE International Conference on Acoustics, Speech and Signal Processing 2023
Abstract: The dynamical variational autoencoders (DVAEs) are a family of latent-variable deep generative models that extends the VAE to model a sequence of observed data and a corresponding sequence of latent vectors. In almost all the DVAEs of the literature, the temporal dependencies within each sequence and across the two sequences are modeled with recurrent neural networks. In this paper, we propose to model speech signals with the Hierarchical Transformer DVAE (HiT-DVAE), which is a DVAE with two levels of latent variable (sequence-wise and frame-wise) and in which the temporal dependencies are implemented with the Transformer architecture. We show that HiT-DVAE outperforms several other DVAEs for speech spectrogram modeling, while enabling a simpler training procedure, revealing its high potential for ...
- Back to MLP: A Simple Baseline for Human Motion Prediction
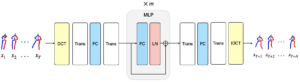
by Wen Guo*, Yuming Du*, Xi Shen, Vincent Lepetit, Xavier Alameda-Pineda, and Francesc Moreno-Noguer
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2023, Waikoloa, Hawaii
Abstract. This paper tackles the problem of human motion prediction, consisting in forecasting future body poses from historically observed sequences. State-of-the-art approaches provide good results, however, they rely on deep learning architectures of arbitrary complexity, such as Recurrent Neural Networks (RNN), Transformers, or Graph Convolutional Networks (GCN), typically requiring multiple training stages and more than 2 million parameters. In this paper, we show that, after combining with a series of standard practices, such as applying Discrete Cosine Transform (DCT), predicting residual displacement of joints, and optimizing velocity as an auxiliary loss, a light-weight network based on multi-layer perceptrons (MLPs) with only 0.14 million parameters can surpass the state-of-the-art performance. An exhaustive evaluation on ...
- Learning and controlling the source-filter representation of speech with a variational autoencoder
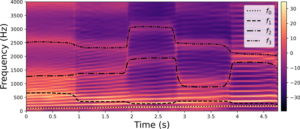
by Samir Sadok, Simon Leglaive, Laurent Girin, Xavier Alameda-Pineda, Renaud Séguier
SpeechCom, 2023
Abstract: Understanding and controlling latent representations in deep generative models is a challenging yet important problem for analyzing, transforming and generating various types of data. In speech processing, inspiring from the anatomical mechanisms of phonation, the source-filter model considers that speech signals are produced from a few independent and physically meaningful continuous latent factors, among which the fundamental frequency and the formants are of primary importance. In this work, we show that the source-filter model of speech production naturally arises in the latent space of a variational autoencoder (VAE) trained in an unsupervised fashion on a dataset of natural speech signals. Using only a few seconds of labeled speech signals generated with an artificial speech synthesizer, we experimentally demonstrate that the fundamental frequency ...
- Variational meta-reinforcement learning for social robotics
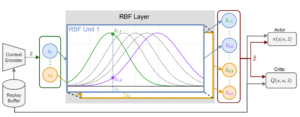
by Anand Ballou, Xavier Alameda-Pineda, and Chris Reinke
Applied Intelligence
Abstract: With the increasing presence of robots in our everyday environments, improving their social skills is of utmost importance. Nonetheless, social robotics still faces many challenges. One bottleneck is that robotic behaviors often need to be adapted, as social norms depend strongly on the environment. For example, a robot should navigate more carefully around patients in a hospital than around workers in an office. In this work, we investigate meta-reinforcement learning (metaRL) as a potential solution. Here, robot behaviors are learned via reinforcement learning, where a reward function needs to be chosen so that the robot learns an appropriate behavior for a given environment. We propose to use a variational meta-RL procedure that quickly adapts the robots’ behavior to new reward functions. As a result, in a new environment, different reward functions ...
- Successor Feature Representations

by Chris Reinke and Xavier Alameda-Pineda
Transactions on Machine Learning Research
Abstract. Transfer in Reinforcement Learning aims to improve learning performance on target tasks using knowledge from experienced source tasks. Successor features (SF) are a prominent transfer mechanism in domains where the reward function changes between tasks. They reevaluate the expected return of previously learned policies in a new target task and to transfer their knowledge. A limiting factor of the SF framework is its assumption that rewards linearly decompose into successor features and a reward weight vector. We propose a novel SF mechanism, ξ-learning, based on learning the cumulative discounted probability of successor features. Crucially, ξ-learning allows to reevaluate the expected return of policies for general reward functions. We introduce two ξ-learning variations, prove its convergence, and provide a guarantee on its transfer performance. Experimental evaluations based ...
- Expression-preserving face frontalization improves visually assisted speech processing
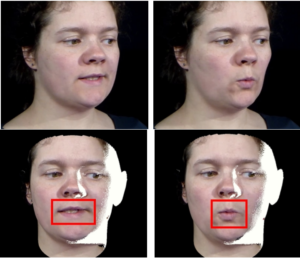
by Zhiqi Kang, Mostafa Sadeghi, Radu Horaud and Xavier Alameda-Pineda
International Journal of Computer Vision, 2023, 131 (5), pp.1122-1140


Abstract. Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution of this paper is a frontalization methodology that preserves non-rigid facial deformations in order to boost the performance of visually assisted speech communication. The method alternates between the estimation of (i) the rigid transformation (scale, rotation,
- DAUMOT: Domain Adaptation for Unsupervised Multiple Object Tracking
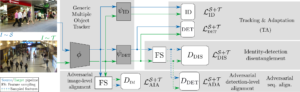
By Guillaume Delorme*, Yihong Xu*, Luis G. Camara, Elisa Ricci, Radu Horaud, Xavier Alameda Pineda
Abstract:
Existing works on multiple object tracking (MOT) are developed under the traditional supervised learning setting, where the training and test data are drawn from the same distribution. This hinders the development of MOT in real-world applications since collecting and annotating a tracking dataset for each deployment scenario is often very time-consuming or even unrealistic. Motivated by this limitation, we investigate MOT in unsupervised settings and introduce DAUMOT, a general MOT training framework designed to adapt an existing pre-trained MOT method to a target dataset without annotations. DAUMOT alternates between tracking and adaptation. During tracking, a model pre-trained on source data is used to track on the target dataset and to generate pseudo-labels. During adaptation, both the source labels and the target pseudo-labels are used to update ...
- Continual Attentive Fusion for Incremental Learning in Semantic Segmentation
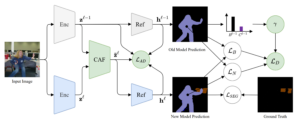
Guanglei Yang, Enrico Fini, Dan Xu, Paolo Rota, Mingli Ding, Hao Tang, Xavier Alameda-Pineda, Elisa Ricci
IEEE Transactions on MultimediaAbstract. Over the past years, semantic segmentation, similar to many other tasks in computer vision, has benefited from the progress in deep neural networks, resulting in significantly improved performance. However, deep architectures trained with gradient-based techniques suffer from catastrophic forgetting, which is the tendency to forget previously learned knowledge while learning new tasks. Aiming at devising strategies to counteract this effect, incremental learning approaches have gained popularity over the past years. However, the first incremental learning methods for semantic segmentation appeared only recently. While effective, these approaches do not account for a crucial aspect in pixel-level dense prediction problems, i.e., the role of attention
mechanisms. To fill this gap, in this paper, we introduce a novel attentive feature distillation approach to mitigate catastrophic forgetting while accounting for semantic spatial- and channellevel ...- A Proposal-based Paradigm for Self-supervised Sound Source Localization in Videos
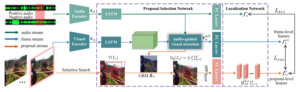
Hanyu Xuan, Zhiliang Wu, Jian Yang, Yan Yan, Xavier Alameda-Pineda
IEEE/CVF International Conference on Computer Vision (CVPR) 2022, New Orleans, USAbstract. Humans can easily recognize where and how the sound is produced via watching a scene and listening to corresponding audio cues. To achieve such cross-modal perception on machines, existing methods only use the maps generated by interpolation operations to localize the sound source. As semantic object-level localization is more attractive for potential practical applications, we argue that these existing map-based approaches only provide a coarse-grained and indirect description of the sound source. In this paper, we advocate a novel proposal-based paradigm that can directly perform semantic object-level localization, without
any manual annotations. We incorporate the global response map as an unsupervised spatial constraint to weight the proposals according to how well they cover the estimated global shape of the sound source. As a result, our proposal-based ...- Continual Models are Self-Supervised Learners
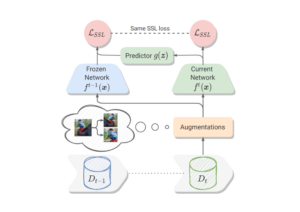
by Enrico Fini, Victor G. Turrisi da Costa, Xavier Alameda-Pineda, Elisa Ricci, Karteek Alahari, Julien Mairal
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022, New Orleans, USAAbstract. Self-supervised models have been shown to produce comparable or better visual representations than their supervised counterparts when trained offline on unlabeled data at scale. However, their efficacy is catastrophically reduced in a Continual Learning (CL) scenario where data is presented to the model sequentially. In this paper, we show that self-supervised loss functions can be seamlessly converted into distillation mechanisms for CL by adding a predictor network that maps the current state of the representations to their past state. This enables us to devise a framework for Continual self-supervised visual representation Learning that (i) significantly improves the quality of the learned representations, (ii) is compatible with several
state-of-the-art self-supervised objectives, and (iii) needs little to no hyperparameter tuning. We demonstrate the effectiveness of our approach empirically ...- Multi Person Extreme Motion Prediction

by Wen Guo*, Xiaoyu Bie*, Xavier Alameda-Pineda and Francesc Moreno-Noguer
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022, New Orleans, USA
Abstract. Human motion prediction aims to forecast future poses given a sequence of past 3D skeletons. While this problem has recently received increasing attention, it has mostly been tackled by single humans in isolation. In this paper, we explore this problem when dealing with humans performing collaborative tasks, we seek to predict the future motion of two interacted persons given two sequences of their past skeletons.
We propose a novel cross-interaction attention mechanism that exploits historical information of both persons and learns to predict cross dependencies between the two pose sequences. Since no dataset to train such interactive situations is available, we collected ExPI (Extreme Pose Interaction), a new lab-based person interaction dataset of ...- Unsupervised Multiple-Object Tracking with a Dynamical Variational Autoencoder
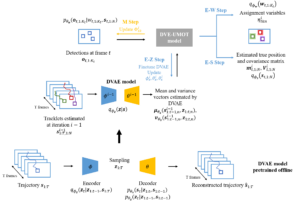
by Xiaoyu Lin, Laurent Girin and Xavier Alameda-Pineda
Introduction
Multi-object tracking (MOT), or multi-target tracking, is a fundamental and very general pattern recognition task. Given an input time-series, the aim of MOT is to recover the trajectories of an unknown number of sources, that might appear and disappear at any point in time. There are four main challenges associated to MOT, namely: (i) extracting source observations (also called detections) at every time frame, (ii) modeling the dynamics of the sources’ movements, (iii) associating observations to sources consistently over time, and (iv) accounting for birth and death of source trajectories.
In computer vision, the tracking-by-detection paradigm has become extremely popular in the recent years. In this context, more and more powerful detection algorithms brought a significant increase of performance. Including motion information also improves the tracking performance. Among the tracking approaches based on motion models, ...
- The impact of removing head movements on audio-visual speech enhancement
by Zhiqi Kang, Mostafa Sadeghi, Radu Horaud, Xavier Alameda-Pineda, Jacob Donley, Anurag Kumar
ICASSP’22, SingaporeAbstract. This paper investigates the impact of head movements on audio-visual speech enhancement (AVSE). Although being a common conversational feature, head movements have been ignored by past and recent studies: they challenge today’s learning-based methods as they often degrade the performance of models that are trained on clean, frontal, and steady face images. To alleviate this problem, we propose to use robust face frontalization (RFF) in combination with an AVSE method based on a variational auto-encoder (VAE) model. We briefly describe the basic ingredients of the proposed pipeline and we perform experiments with a recently released audio-visual dataset. In the light of these experiments, and based on three standard metrics, namely STOI, PESQ and SI-SDR, we conclude that RFF improves the performance of AVSE by a considerable margin.
- Successor Feature Neural Episodic Control
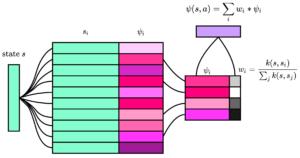
by Davier Emukpere, Xavier Alameda-Pineda and Chris Reinke
Abstract. A longstanding goal in reinforcement learning is to build intelligent agents that show fast learning and a flexible transfer of skills akin to humans and animals. This paper investigates the integration of two frameworks for tackling those goals: episodic control and successor features. Episodic control is a cognitively inspired approach relying on episodic memory, an instance-based memory model of an agent’s experiences. Meanwhile, successor features and generalized policy improvement (SF&GPI) is a meta and transfer learning framework allowing to learn policies for tasks that can be efficiently reused for later tasks which have a different reward function. Individually, these two techniques have shown impressive results in vastly improving sample efficiency and the elegant reuse of previously learned policies. Thus, we outline a combination of both approaches in a single reinforcement learning framework and empirically ...
- Dynamical Variational AutoEncoders
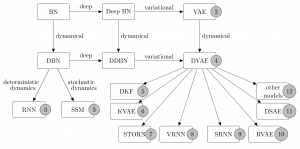
by Laurent Girin, Simon Leglaive, Xiaoyu Bie, Julien Diard, Thomas Hueber, and Xavier Alameda-Pineda
Foundations and Trends in Machine Learning, 2021, Vol. 15, No. 1-2, pp 1–175.Abstract. Variational autoencoders (VAEs) are powerful deep generative models widely used to represent high-dimensional complex data through a low-dimensional latent space learned in an unsupervised manner. In the original VAE model, the input data vectors are processed independently. Recently, a series of papers have presented different extensions of the VAE to process sequential data, which model not only the latent space but also the temporal dependencies within a sequence of data vectors and corresponding latent vectors, relying on recurrent neural networks or state-space models. In this paper, we perform a literature review of these models. We introduce and discuss a general class of models, called dynamical variational autoencoders (DVAEs), which encompasses a large subset of these temporal ...
- SocialInteractionGAN: Multi-person Interaction Sequence Generation
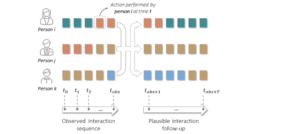
by Louis Airale, Dominique Vaufreydaz and Xavier Alameda-Pineda
Abstract. Prediction of human actions in social interactions has important applications in the design of social robots or artificial avatars. In this paper, we model human interaction generation as a discrete multi-sequence generation problem and present SocialInteractionGAN, a novel adversarial architecture for conditional interaction generation. Our model builds on a recurrent encoder-decoder generator network and a dual-stream discriminator. This architecture allows the discriminator to jointly assess the realism of interactions and that of individual action sequences. Within each stream a recurrent network operating on short subsequences endows the output signal with local assessments, better guiding the forthcoming generation. Crucially, contextual information on interacting participants is shared among agents and reinjected in both the generation and the discriminator evaluation processes. We show that the proposed SocialInteractionGAN succeeds in producing high realism action sequences ...
- A Benchmark of Dynamical Variational Autoencoders applied to Speech Spectrogram Modeling
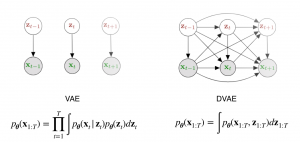
by Xiaoyu Bie, Laurent Girin, Simon Leglaive, Thomas Hueber and Xavier Alameda-Pineda
Interspeech’21, Brno, Czech Republic
Abstract. The Variational Autoencoder (VAE) is a powerful deep generative model that is now extensively used to represent high-dimensional complex data via a low-dimensional latent space learned in an unsupervised manner. In the original VAE model, input data vectors are processed independently. In recent years, a series of papers have presented different extensions of the VAE to process sequential data, that not only model the latent space, but also model the temporal dependencies within a sequence of data vectors and corresponding latent vectors, relying on recurrent neural networks. We recently performed a comprehensive review of those models and unified them into a general class called Dynamical Variational Autoencoders (DVAEs). In the present paper, we present the results of an experimental benchmark comparing ...
- PI-Net: Pose Interacting Network for Multi-Person Monocular 3D Pose Estimation
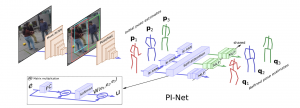
by Wen Guo, Enric Corona, Francesc Moreno-Noguer, Xavier Alameda-Pineda,
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2021)
Abstract. Recent literature addressed the monocular 3D pose estimation task very satisfactorily. In these studies, different persons are usually treated as independent pose instances to estimate. However, in many everyday situations, people are interacting, and the pose of an individual depends on the pose of his/her interaction. In this paper, we investigate how to exploit this dependency to enhance current – and possibly future – deep networks for 3D monocular pose estimation. Our pose interacting network, or PI-Net, inputs the initial pose estimates of a variable number of interaction into a recurrent architecture used to refine the pose of the person-of-interest. Evaluating such a method is challenging due to the limited availability of public annotated multi-person 3D human pose datasets. ...
- Robust Face Frontalization For Visual Speech Recognition

by Zhiqi Kang, Radu Horaud and Mostafa Sadeghi
ICCV’21 Workshop on Traditional Computer Vision in the Age of Deep Learning (TradiCV’21)
Abstract. Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution is a robust method that preserves non-rigid facial deformations, i.e. expressions. The method iteratively estimates the rigid transformation and the non-rigid deformation between 3D landmarks extracted from an arbitrarily-viewed face, and 3D vertices parameterized by a deformable shape model. The one merit of the method is its ability to deal with large Gaussian and non-Gaussian errors in the data. For that purpose, we use the generalized Student-t distribution. The associated EM algorithm assigns a weight to each observed landmark, the higher the weight the more important the landmark, thus favouring landmarks that are only affected by rigid head movements. We propose ...
- TransCenter: Transformers with Dense Representations for Multiple-Object Tracking
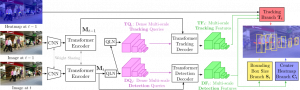
by Yihong Xu*, Yutong Ban*, Guillaume Delorme, Chuang Gan, Daniela Rus and Xavier Alameda-Pineda
Abstract:
Transformers have proven superior performance for a wide variety of tasks since they were introduced, which has drawn in recent years the attention of the vision community where efforts were made such as image classification and object detection. Despite this wave, building an accurate and efficient multiple-object tracking (MOT) method with transformers is not a trivial task. We argue that the direct application of a transformer architecture with quadratic complexity and insufficient noise-initialized sparse queries – is not optimal for MOT. Inspired by recent research, we propose TransCenter, a transformer-based MOT architecture with dense representations for accurately tracking all the objects while keeping a reasonable runtime. Methodologically, we propose the use of dense image-related multi-scale detection queries produced by an efficient transformer architecture. The queries allow ...
- Fullsubnet: a full-band and sub-band fusion model for real-time single-channel speech enhancement
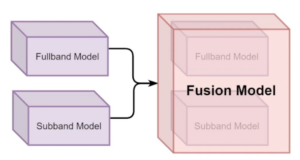
By Xiang Hao*,#, Xiangdong Su#, Radu Horaud and Xiaofei Li* (*Westlake University, #Inner Mongolia University, China)
ICASSP 2021
Abstract. This paper proposes a full-band and sub-band fusion model, named as FullSubNet, for single-channel real-time speech enhancement. Full-band and sub-band refer to the models that input full-band and sub-band noisy spectral feature, output full-band and sub-band speech target, respectively. The sub-band model processes each frequency independently. Its input consists of one frequency and several context frequencies. The output is the prediction of the clean speech target for the corresponding frequency. These two types of models have distinct characteristics. The full-band model can capture the global spectral context and the long-distance cross- band dependencies. However, it lacks the ability to modeling signal stationarity and attending the local spectral pattern. The sub-band model is just the opposite. In our proposed FullSubNet, we connect a ...
- Mixture of Inference Networks for VAE-based Audio-visual Speech Enhancement
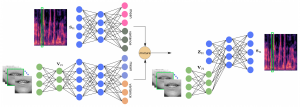
by Mostafa Sadeghi, Xavier Alameda-Pineda
IEEE TSP, 2021
Abstract. In this paper, we are interested in unsupervised (unknown noise) speech enhancement, where the probability distribution of clean speech spectrogram is simulated via a latent variable generative model, also called the decoder. Recently, variational autoencoders (VAEs) have gained much popularity as probabilistic generative models. In VAEs, the posterior of the latent variables is computationally intractable, and it is approximated by a so-called encoder network. Motivated by the fact that visual data, i.e. lip images of the speaker, provide helpful and complementary information about speech, some audio-visual architectures have been recently proposed. The initialization of the latent variables at test time is crucial as the overall inference problem is non-convex. This is usually done by using the output of the encoder where the noisy audio and clean video data are given as input. Current ...
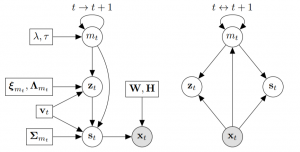
- Variational Inference and Learning of Piecewise-linear Dynamical Systems
by Xavier Alameda-Pineda, Vincent Drouard, Radu Horaud
IEEE TNNLS 2021
Abstract Modeling the temporal behavior of data is of primordial importance in many scientific and engineering fields. Baseline methods assume that both the dynamic and observation equations follow linear-Gaussian models. However, there are many real-world processes that cannot be characterized by a single linear behavior. Alternatively, it is possible to consider a piecewise-linear model which, combined with a switching mechanism, is well suited when several modes of behavior are needed. Nevertheless, switching dynamical systems are intractable because their computational complexity increases exponentially with time. In this paper, we propose a variational approximation of piecewise linear dynamical systems. We provide full details of the derivation of two variational expectation-maximization algorithms, a filter and a smoother. We show that the model parameters can be split into two sets, static and dynamic parameters, and that the former parameters ...
- ODANet: Online Deep Appearance Network for Identity-Consistent Multi-Person Tracking

by Guillaume Delorme , Yutong Ban , Guillaume Sarrazin and Xavier Alameda-Pineda
ICPR’20 Workshop on Multimodal pattern recognition for social signal processing in human computer interaction
Abstract. The analysis of effective states through time in multi-person scenarii is very challenging, because it requires to consistently track all persons over time. This requires a robust visual appearance model capable of re-identifying people already tracked in the past, as well as spotting newcomers. In real-world applications, the appearance of the persons to be tracked is unknown in advance, and therefore on must devise methods that are both discriminative and flexible. Previous work in the literature proposed different tracking methods with fixed appearance models. These models allowed, up to a certain extent, to discriminate between appearance samples of two different people. We propose an online deep appearance network (ODANet), a method able to simultaneously track people and update the ...
- Probabilistic Graph Attention Network with Conditional Kernels for Pixel-Wise Prediction
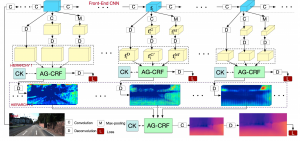
by Dan Xu, Xavier Alameda-Pineda, Wanli Ouyang, Elisa Ricci, Xiaogang Wang and Nicu Sebe
IEEE TPAMI, 2020
Abstract. Multi-scale representations deeply learned via convolutional neural networks have shown tremendous importance for various pixel-level prediction problems. In this paper we present a novel approach that advances the state of the art on pixel-level prediction in a fundamental aspect,i.e.structured multi-scale features learning and fusion. In contrast to previous works directly considering multi-scale feature maps obtained from the inner layers of a primary CNN architecture, and simply fusing the features with weighted averaging or concatenation, we propose a probabilistic graph attention network structure based on a novel Attention-Gated Conditional Random Fields(AG-CRFs) model for learning and fusing multi-scale representations in a principled manner. In order to further improve the learning capacity of the network structure, we propose to exploit feature dependant conditional kernels within the ...
- Switching Variational Auto-Encoders for Noise-Agnostic Audio-visual Speech Enhancement
by Mostafa Sadeghi and Xavier Alameda-Pineda
Presented at IEEE ICASSP 2021
Abstract: Recently, audio-visual speech enhancement has been tackled in the unsupervised settings based on variational auto-encoders (VAEs), where during training only clean data is used to train a generative model for speech, which at test time is combined with a noise model, e.g. nonnegative matrix factorization (NMF), whose parameters are learned without supervision. Consequently, the proposed model is agnostic to the noise type. When visual data is clean, audio-visual VAE-based architectures usually outperform the audio-only counterpart. The opposite happens when the visual data is corrupted by clutter, e.g. the speaker not facing the camera. In this paper, we propose to find the optimal combination of these two architectures through time. More precisely, we introduce the use of a latent sequential variable with Markovian dependencies to switch between different VAE architectures through time ...
- Deep Variational Generative Models for Audio-visual Speech Separation
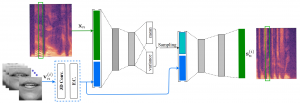
by Viet-Nhat Nguyen, Mostafa Sadeghi, Elisa Ricci, and Xavier Alameda-Pineda
Presented at IEEE MLSP 2021
Abstract: In this paper, we are interested in audio-visual speech separation given a single-channel audio recording as well as visual information (lips movements) associated with each speaker. We propose an unsupervised technique based on audio-visual generative modeling of clean speech. More specifically, during training, a latent variable generative model is learned from clean speech spectrograms using a variational auto-encoder (VAE). To better utilize the visual information, the posteriors of the latent variables are inferred from mixed speech (instead of clean speech) as well as the visual data. The visual modality also serves as a prior for latent variables, through a visual network. At test time, the learned generative model (both for speaker-independent and speaker-dependent scenarios) is combined with an unsupervised non-negative matrix factorization (NMF) variance model for background ...
- Online Monaural Speech Enhancement using Delayed Subband LSTM
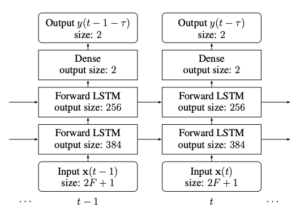
by Xiaofei Li and Radu Horaud
INTERSPEECH 2020
Abstract. This paper proposes a delayed subband LSTM network for online monaural (single-channel) speech enhancement. The proposed method is developed in the short time Fourier transform (STFT) domain. Online processing requires frame-by-frame signal reception and processing. A paramount feature of the proposed method is that the same LSTM is used across frequencies, which drastically reduces the number of network parameters, the amount of training data and the computational burden. Training is performed in a subband manner: the input consists of one frequency, together with a few context frequencies. The network learns a speech-to-noise discriminative function relying on the signal stationarity and on the local spectral pattern, based on which it predicts a clean-speech mask at each frequency. To exploit future information, i.e. look-ahead, we propose an output-delayed subband architecture, which allows ...
- CANU-ReID: A Conditional Adversarial Network for Unsupervised person Re-IDentification

by Guillaume Delorme, Stéphane Lathuilière, Radu Horaud and Xavier Alameda-Pineda
Presented at ICPR, 2021
Abstract: Unsupervised person re-ID is the task of identifying people on a target dataset for which the ID labels are unavailable during training. In this paper, we propose to unify two trends in unsupervised person re-ID: clustering & fine-tuning and adversarial learning. On one side, clustering is used to group the training images into pseudo-labels, and then use this pseudo-labels to fine-tune the feature extractor. On the other side, adversarial learning is used, inspired from domain adaptation, to match distributions from different domains. We propose to model each camera of the target dataset as a domain, and aim to learn domain-independent features. Straightforward adversarial learning yields negative transfer, and we introduce a conditioning vector to mitigate this undesirable effect. In our ...
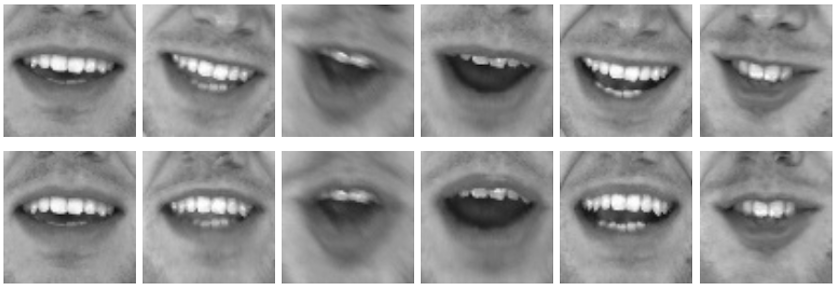
- Learning Visual Voice Activity Detection with an Automatically Annotated Dataset
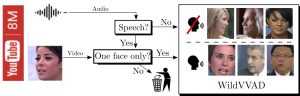
by Sylvain Guy, Stéphane Lathuilière, Pablo Mesejo and Radu Horaud
Presented at ICPR 2021
Abstract. Visual voice activity detection (V-VAD) uses visual features to predict whether a person is speaking or not. V-VAD is useful whenever audio VAD (A-VAD) is inefficient, either because the acoustic signal is difficult to analyze or because it is simply missing. We propose two deep architectures for V-VAD, one based on facial landmarks and one based on optical flow. Moreover, available datasets, used for learning and for testing V-VAD, lack content variability. We introduce a novel methodology to automatically create and annotate very large datasets in-the-wild – WildVVAD – based on combining A-VAD with face detection. A thorough empirical evaluation shows the advantage of training the proposed deep V-VAD models with this dataset.
Dataset. The automatically generated and annotated WildVVAD dataset is publicly available. It contains 12,000 video ...
- How To Train Your Deep Multi-Object Tracker
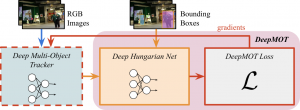
by Yihong Xu, Aljoša Ošep, Yutong Ban, Radu Horaud, Laura Leal-Taixé and Xavier Alameda-Pineda
Presented at IEEE CVPR 2020
Abstract: The recent trend in vision-based multi-object tracking (MOT) is heading towards leveraging the representational power of deep learning to jointly learn to detect and track objects. However, existing methods train only certain submodules using loss functions that often do not correlate with established tracking evaluation measures such as Multi-Object Tracking Accuracy (MOTA) and Precision (MOTP). As these measures are not differentiable, the choice of appropriate loss functions for end-to-end training of multiobject tracking methods is still an open research problem. In this paper, we bridge this gap by proposing a differentiable proxy of MOTA and MOTP, which we combine in a loss function suitable for end-to-end training of deep multiobject trackers. As a key ingredient, we propose a Deep ...
- Motion-DVAE: Unsupervised learning for fast human motion denoising