



by Xiaoyu Bie, Laurent Girin, Simon Leglaive, Thomas Hueber and Xavier Alameda-Pineda
Interspeech’21, Brno, Czech Republic
[paper][slides][code][bibtex]
Abstract. The Variational Autoencoder (VAE) is a powerful deep generative model that is now extensively used to represent high-dimensional complex data via a low-dimensional latent space learned in an unsupervised manner. In the original VAE model, input data vectors are processed independently. In recent years, a series of papers have presented different extensions of the VAE to process sequential data, that not only model the latent space, but also model the temporal dependencies within a sequence of data vectors and corresponding latent vectors, relying on recurrent neural networks. We recently performed a comprehensive review of those models and unified them into a general class called Dynamical Variational Autoencoders (DVAEs). In the present paper, we present the results of an experimental benchmark comparing six of those DVAE models on the speech analysis-resynthesis task, as an illustration of the high potential of DVAEs for speech modeling.
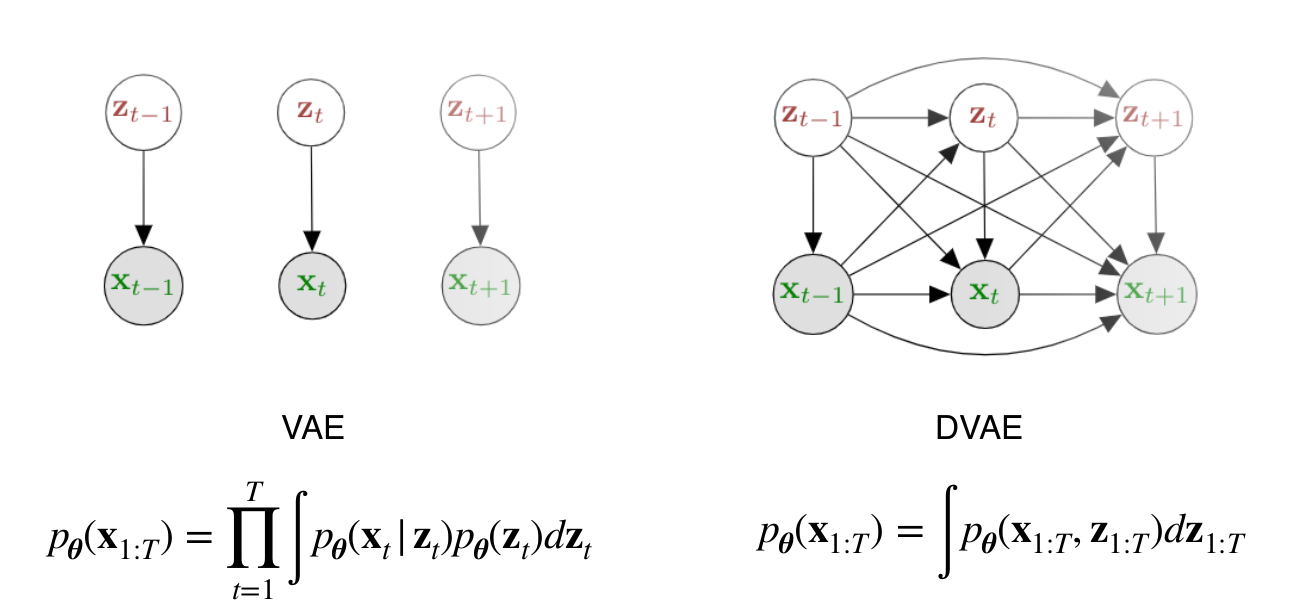
From VAE to DVAE
Different DVAE model varies in the formulation of generation and inference:
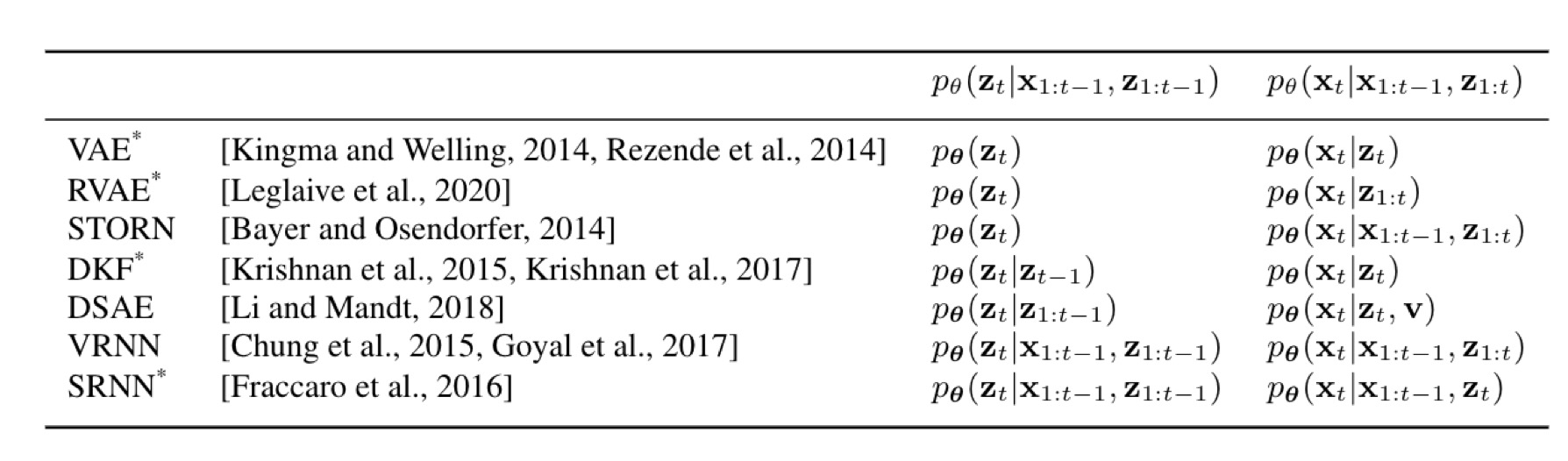
We re-implement those DVAE models in PyTorch and build a benchmark in the experiment of speech analyze-resynthesis:

- Dataset: WSJ0 subsets (si_tr_s, si_dt_05 and si_et_05, different speakers)
- Time-domain 16 kHz signals are normalized by the absolute maximum value
- STFT with a 32ms sine window and 16ms hop length
- Crop the magnitude spectrogram into 150-frame sequences during training
- In summary
- 9h for training (si_tr_s)
- 1.5h for validation (si_dt_05)
- 1.5h for evaluation (si_et_05, no cropping)

Experimental results show that:
- All DVAEs outperform the vanilla VAE
- Autoregressive models are powerful in speech analysis-resynthesis
- It is rewarding to respect the structure of the exact posterior distribution when designing the inference model
- It is better to apply a dynamical model on z, not simply assume that it is i.i.d
- SRNN performs the best because it features all three properties