Expression-preserving face frontalization improves visually assisted speech processing

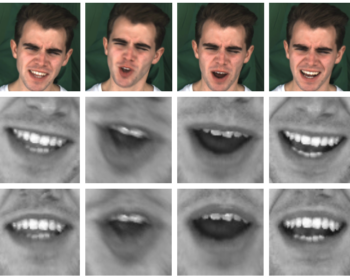
by Zhiqi Kang, Mostafa Sadeghi, Radu Horaud and Xavier Alameda-Pineda International Journal of Computer Vision, 2023, 131 (5), pp.1122-1140 [arXiv] [HAL] [webpage] Abstract. Face frontalization consists of synthesizing a frontally-viewed face from an arbitrarily-viewed one. The main contribution of this paper is a frontalization methodology that preserves non-rigid facial deformations in order to boost…