By Xiang Hao*,#, Xiangdong Su#, Radu Horaud and Xiaofei Li* (*Westlake University, #Inner Mongolia University, China)
ICASSP 2021
[arXiv][github][youtube]
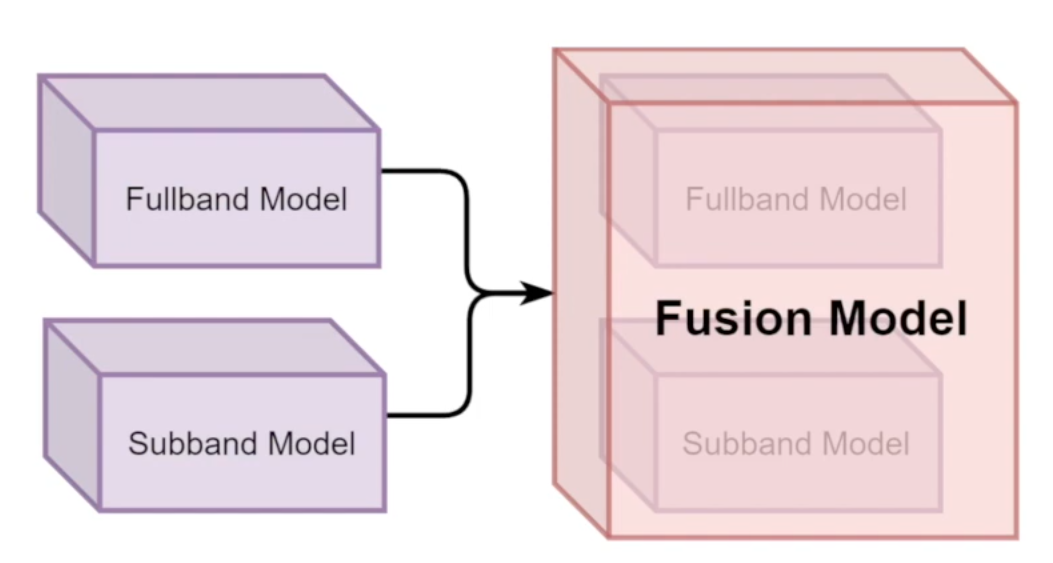
Abstract. This paper proposes a full-band and sub-band fusion model, named as FullSubNet, for single-channel real-time speech enhancement. Full-band and sub-band refer to the models that input full-band and sub-band noisy spectral feature, output full-band and sub-band speech target, respectively. The sub-band model processes each frequency independently. Its input consists of one frequency and several context frequencies. The output is the prediction of the clean speech target for the corresponding frequency. These two types of models have distinct characteristics. The full-band model can capture the global spectral context and the long-distance cross- band dependencies. However, it lacks the ability to modeling signal stationarity and attending the local spectral pattern. The sub-band model is just the opposite. In our proposed FullSubNet, we connect a pure full-band model and a pure sub-band model sequentially and use practical joint training to integrate these two types of mod- els’ advantages. We conducted experiments on the DNS challenge (INTERSPEECH 2020) dataset to evaluate the proposed method. Experimental results show that full-band and sub-band information are complementary, and the FullSubNet can effectively integrate them. Besides, the performance of the FullSubNet also exceeds that of the top-ranked methods in the DNS Challenge (INTERSPEECH 2020).