



Multi Person Extreme Motion Prediction
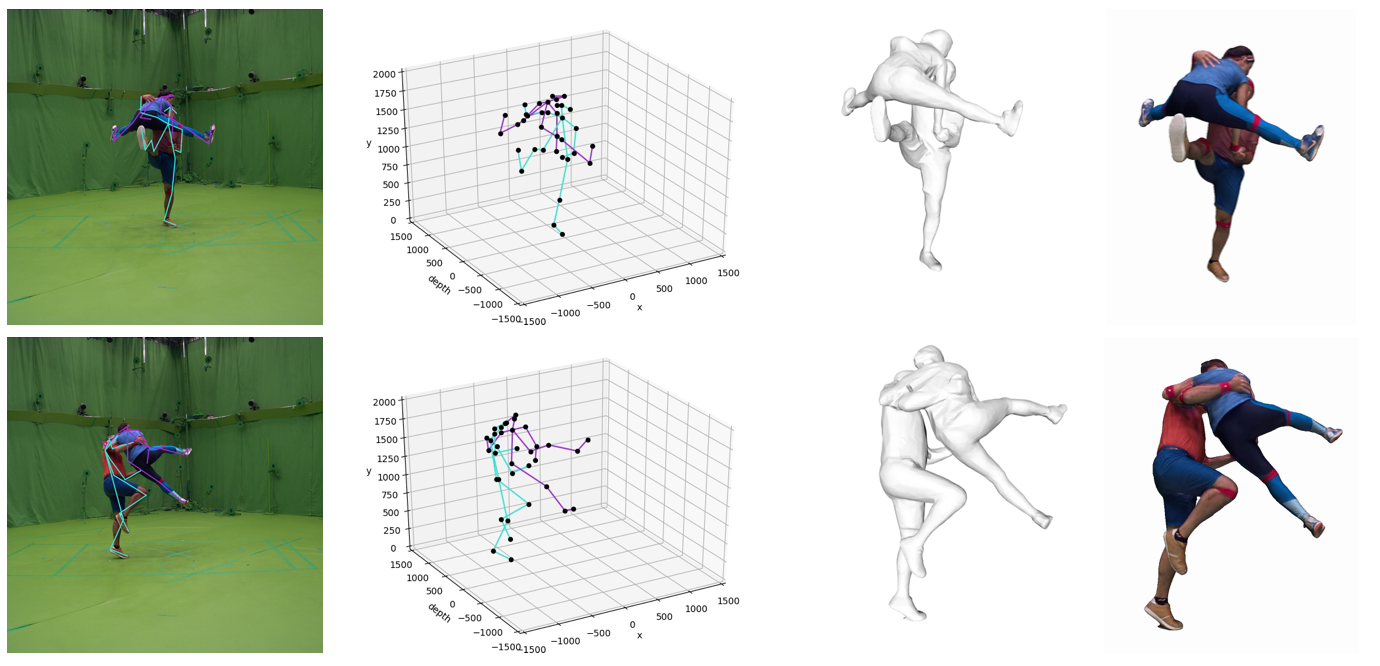
by Wen Guo*, Xiaoyu Bie*, Xavier Alameda-Pineda and Francesc Moreno-Noguer IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022, New Orleans, USA [paper] [code] [data] Abstract. Human motion prediction aims to forecast future poses given a sequence of past 3D skeletons. While this problem has recently received increasing attention, it has mostly been…



