
First paper with the soda affiliation: Imputing out-of-vocabulary embeddings with LOVE makes language models robust with little cost (https://arxiv.org/abs/2203.07860) Making language models robust to unknown words (eg typos): a bit of contrastive learning can extend language models without retraining them!
The idea of LOVE (Learning Out-of-Vocabulary Embeddings) is to map unknown tokens to parameters of the language model representing known ones.
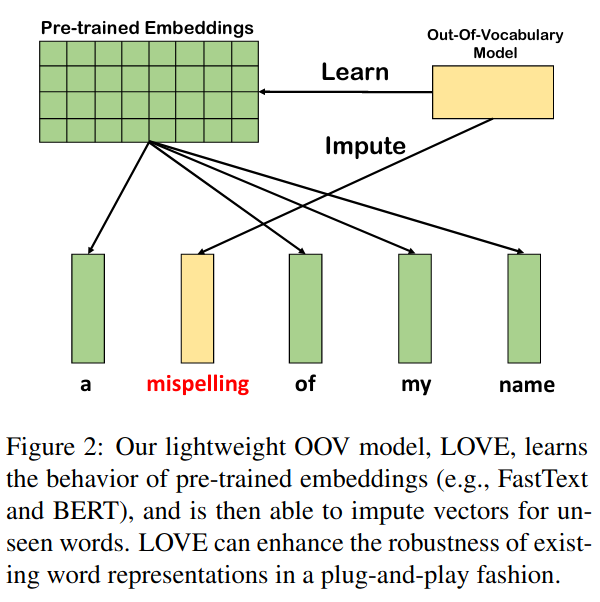
The mapping from unknown tokens to known ones is learned with contrastive learning: generating variants of the tokens with a model of morphological variants and tuning a char-level encoder (a lightweight attentional module) to maximize their similarity to the original token.
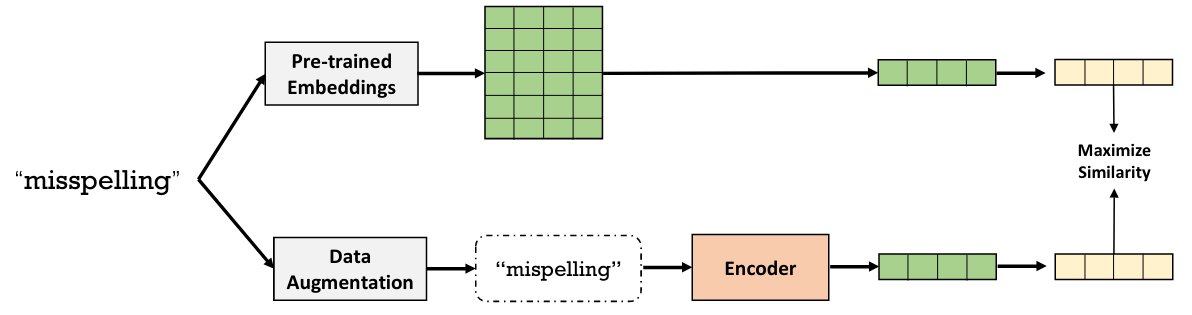
We demonstrate that it makes models such as BERT or fasttext more robust to typos. Such robustness is important in Electronic Health Records, as well as for our research on embedding information in non-curated databases.