
[PhD defense] Generalizing a causal effect from a trial to a target population
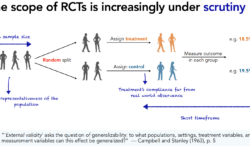
Bénédicte Colnet brilliantly defended her PhD on generalization of causal effects across populations on June 29th 2023. The question she tackled is the following: to empirically evaluate a causal effect, randomized controlled trials (RCTs) give excellent control of confounding effects (internal validity), but they often are performed on a population…