



by Wen Guo, Enric Corona, Francesc Moreno-Noguer, Xavier Alameda-Pineda,
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV 2021)
[paper][code]
Abstract. Recent literature addressed the monocular 3D pose estimation task very satisfactorily. In these studies, different persons are usually treated as independent pose instances to estimate. However, in many everyday situations, people are interacting, and the pose of an individual depends on the pose of his/her interaction. In this paper, we investigate how to exploit this dependency to enhance current – and possibly future – deep networks for 3D monocular pose estimation. Our pose interacting network, or PI-Net, inputs the initial pose estimates of a variable number of interaction into a recurrent architecture used to refine the pose of the person-of-interest. Evaluating such a method is challenging due to the limited availability of public annotated multi-person 3D human pose datasets. We demonstrate the effectiveness of our method in the MuPoTS dataset, setting the new state-of-the-art on it. Qualitative results on other multi-person datasets (for which 3D pose ground-truth is not available) showcase the proposed PI-Net.
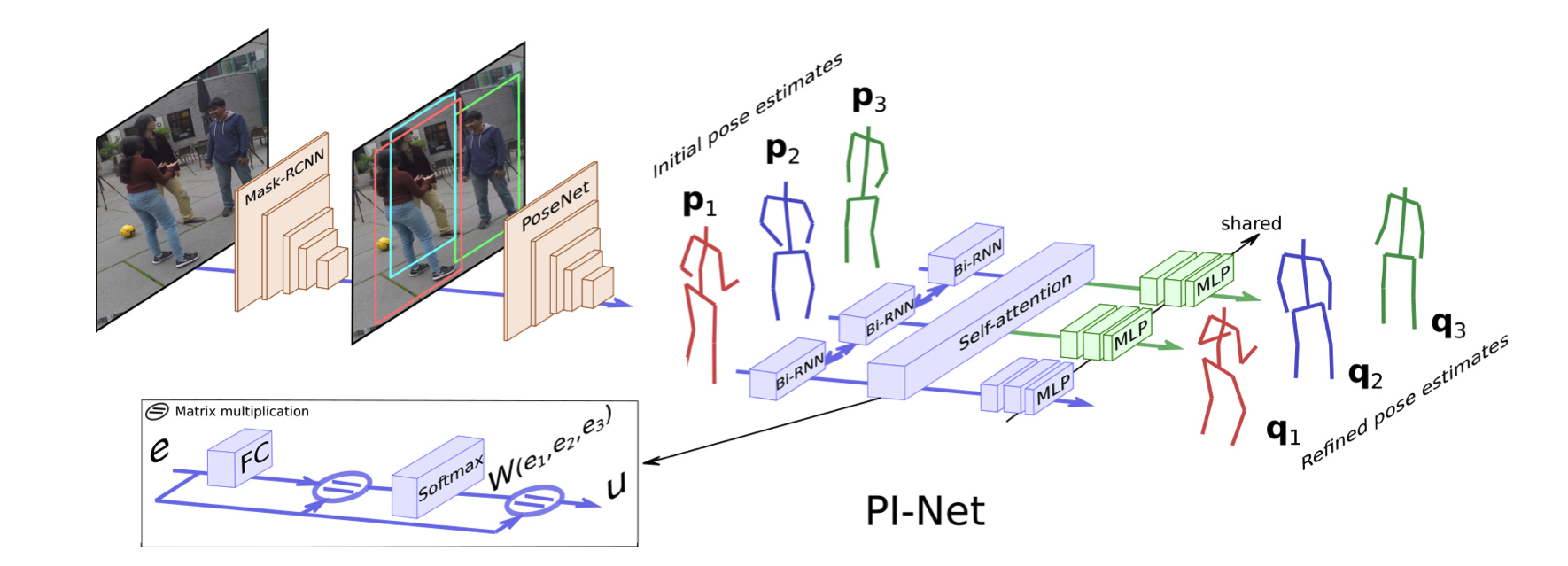
PI-Net pipeline