



The CAMIL dataset is a unique set of audio recordings made with the robot POPEYE. The dataset was gathered in order to investigate audio-motor contingencies from a computational point of view and experiment new auditory models and techniques for Computational Auditory Scene Analysis. The version 0.1 of the dataset was built in November 2010, and the version 1.1 in April 2012. All recording sessions were held at INRIA Grenoble Rhône-Alpes and lead by Antoine Deleforge. A fully automatized protocol for the University of Coimbra’s audiovisual robot head POPEYE was designed to gather a very large number of binaural sounds from different motor states, with or without head movements. Recordings were made in the presence of a static loud speaker emitting sounds with different properties (random spectrum sounds, white noise, speech, music…). Each recording is annotated with the corresponding ground truth motor coordinates of the robot. The overall experiments were entirely unsupervised and laster respectively 70 and 48 hours.
The CAMIL dataset is freely accessible for scientific research purposes and for non-commercial applications.


Experimental Setup and Data Acquisition
Hardware & Experimental Setup
Data were recorded using the Sennheiser MKE 2002 dummy-head, linked to a computer via a Behringer ADA8000 Ultragain Pro-8 digital external sound card. The head was mounted onto the University of Coimbra’s audiovisual robot head POPEYE with four rotational degrees of freedom: a pan motion, a tilt motion, as well as two additional degrees of freedom for eye vergence. This device was specifically designed to achieve precise and reproducible movements with a very good signal-to-noise ratio. The emitter —a loud-speaker— was placed at approximately 2.7 meters ahead of the robot. The loud-speaker’s input and the microphones’ outputs were handled by two synchronized sound cards in order to simulteneously record and play. The experiment was carried out in real-world conditions, i.e., a room with reverberations and background noise.

Motor States & Direct Kinematics
The emitter remained fixed during the whole experiment while the robot was placed in different (pan,tilt) motor states. Each sound recorded was precisely annotated with its corresponding (α,β) ground truth motor state. The ground truth 3D position (xs,ys,zs) of the sound source in the robot frame at each record can therefore be retrieved using the following direct kinematics formula:

This model needs two parameters: the distance from the tilt-axis to the microphones’ midpoint, r=0.22m, and the distance from this midpoint to the emitter, d=2.70m.
Audio Recordings: Version 0.1 (Download)
This dataset was used in the paper
Learning the Direction of a Sound Source Using Head Motions and Spectral Features[1]
The robot was placed in 16,200 motor states: 180 pan rotations α in the range [-180°,180°] and 90 tilt rotations β in the range [-90°,90°] (one recording every 2°). One static and two dynamic binaural recordings of one second were made at each motor states, while the speaker emitted a reference and a random spectrum artificial sound, totalling 6 binaural records per motor state. The name and location of emitted and recorded sounds in our dataset are summarized in the following table:

A pan movement is a head rotation rightwards at constant speed dα/dt=9°/s, centered on the current motor state. A tilt movement is a head rotation downwards at constant speed dβ/dt=9°/s, centered on the current motor state. Emitted sounds were generated using:
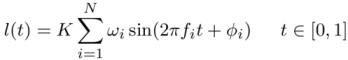
where l(t) is the loud-speaker’s membrane displacement as a function of time t, K is a real positive constant coresponding to the global volume, F={f1…fi…fN} is a fixed set of N frequency channels, {ωi}i=1..N ∈ ]0,1]N and {φi}i=1..N ∈ [0,2π]N are weights and phases associated with each frequency channel. In practice, a set of N=600 frequency channels F={50,150,250…5950} was used. The reference sound was defined by fixed values for ωi and φi and was the same during the whole experiment. A different random spectrum sound was emitted at each motor state by drawing ωi and φi from a uniform distribution.
Audio Recordings: Version 1.1 (Download)
This dataset was used in the papers A Latently Constrained Mixture Model for Audio Source Separation and Localization [2], 2D Sound-Source Localization on the Binaural Manifold [3] and Variational EM for Binaural Sound-Source Separation and Localization
The robot was placed in 10,800 motor states: 180 pan rotations α in the range [-180°,180°] and 60 tilt rotations β in the range [-60°,60°] (one recording every 2°). At each motor state, three static binaural recordings
each were made while the speaker emitted different sounds.
Sound 1 corresponds to one second of white noise, and can be used for training (section 3 in [2] or section 4 in [3]). Sounds 2 corresponds to a random utterance from the TIMIT speech dataset and can be used for testing. Sound 0 corresponds to a silent speaker (“room silence”) and can be used to determine the acoustic level threshold during tests (section 4 in [2] or section 5 in [3]).
Data & Downloads
Version 0.1
To make it easier to downolad, the set of audio recordings was splitted into 18 subparts. Each part contains the dynamic and static binaural recordings of the reference and random spectrum sounds as well as their corresponding emitted sounds (see the table in Setup & Experiment) for a restricted set of 900 motor states. These motor states correspond to 180 different pan positions α forming a complete 360° turn, and 5 different adjacent tilt positions β. The entire data set containing recordings from 16,200 motor states from 180 pan positions and 90 tilt positions can be obtained by simply merging the 18 subparts. Each subparts contains a file associating all sound indexes to their corresponding ground truth motor state (sound_source_ground_truth), as well as a documentation file (README.txt).
Version 1.1
To facilitate downloading, the dataset was divided in 9 sub parts, named soundX_tiltY.zip. X=0 Corresponds to background noise recordings, X=1 corresponds to white noise recordings, X=2 corresponds to random utterances from the TIMIT speech dataset. Y=LOW corresponds to 20 tilt angles from -59° to -21°, Y=MID corresponds to 20 tilt angles from -19° to +19° and Y=HIGH corresponds to 20 tilt angles from 21° to 59°.
| sound0_tiltLOW | sound0_tiltMID | sound0_tiltHIGH |
| sound1_tiltLOW | sound1_tiltMID | sound1_tiltHIGH |
| sound2_tiltLOW | sound2_tiltMID | sound2_tiltHIGH |