Projects
Research Themes
Current topics of research within OAK include:
- Scalable complex processing within large-scale Web databases (RDF, XML, JSON etc.)
- Models and optimizations for emerging data models
- Architectures and optimizations for complex data in the cloud
- Architectures for data transformations on large, evolving datasets
Projects
The main research projects of the team are described below.
Permanent link to this article: https://team.inria.fr/oak/projects/
CliqueSquare is a system for storing and querying large RDF graphs relying on Hadoop’s distributed file system (HDFS) and Hadoop’s MapReduce open-source implementation. CliqueSquare is equipped with a unique optimization algorithm capable of generating highly parallelizable flat query plans relying on n-ary equality joins. In addition, it provides a novel partitioning and storage scheme that …
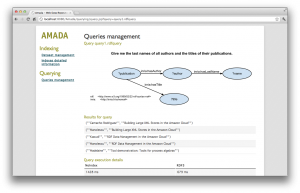
AMADA is a platform for storing Web data (in particular, XML documents and RDF graphs) based on the Amazon Web Services (AWS) cloud infrastructure. AMADA operates in a Software as a Service (SaaS) approach, allowing users to upload, index, store, and query large volumes of Web data. The binary and the source code of the platform …
Fact-checking is the task of assessing the factual accuracy of claims, typically prior to publication. Modern fact-checking is faced with a triple revolution in terms of scale, complexity, and visibility: many more claims are made and disseminated through Web and social media, they represent a complex reality and their investigation requires using multiple heterogeneous data …
“The deepest parts of [data transformation] are totally unknown to us. No soundings have been able to reach them. What goes on in those distant depths? What [data and transformations] inhabit, or could inhabit, those regions […]? What is the constitution of these […]? It’s almost beyond conjecture.” A slightly altered version of an excerpt of Jules …
The OakSad associated team is an Inria structure associating Oak with the database team from UC San Diego. The team has been created in 2013. Publications Invisible Glue: Scalable Self-Tuning Multi-Stores, by Francesca Bugiotti, Damian Bursztyn, Alin Deutsch, Ioana Ileana and Ioana Manolescu accepted for publication in CIDR 2015: https://hal.inria.fr/hal-01087624 XR query-view composition tech. report …
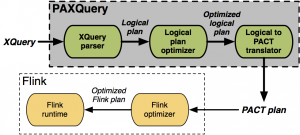
Overview The PAXQuery engine seamlessly parallelizes the execution of XQuery queries. By applying on-the-fly translation and optimization procedures, PAXQuery runs user queries over massive collections of XML documents in a distributed fashion. PAXQuery runs on top of Apache Flink, previously known as Stratosphere, a parallel execution platform that relies on the PACT model. After the …
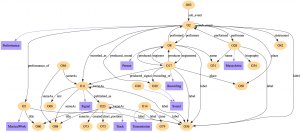
In this work, we study the problem of RDF summarization, that is: given an input RDF graph, find an RDF summary graph which summarizes the input dataset as accurately as possible, while being (most frequently) orders of magnitude smaller than the original graph. Such a summary can be used in a variety of contexts: to help …
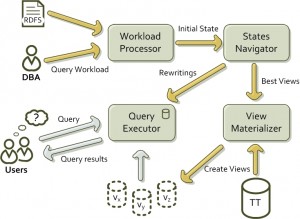
Who is this for ? Database administrators who need an easy way to fine-tune RDF databases RDF applications end-users who need fast access to the semantic web on a day-to-day basis How does it work ? RDFViewS analyses workloads and RDF schemas to look for the best views to materialize It uses various parameters as well as some heuristics to find configurations …
ViP2P is a fully functional Java-based platform for the efficient, scalable management of XML documents in structured peer-to-peer networks based on distributed hash table (DHT) indices. We exploit indices (or materialized views) deployed in the P2P network independently by the peers, to answer an interesting dialect of tree pattern queries. There is a query (and …
WaRG is a warehouse-style analytics platform on RDF graphs. The tool stores data in kdb+ with a Java frontend based on the Prefuse Visualization toolkit. The novelty of WaRG is to redesign the full stack of Data Warehouse abstractions and tools for heterogeneous, semantics-rich RDF data; this enables a WaRG RDF DW to be an RDF graph …
Content on today’s Web is typically document-structured and richly connected; XML is by now widely adopted to represent Web data. Moreover, the vision of a computer-understandable Web relies on Web and real world resources described by simple properties having names or values; URIs are the normative method of identifying resources and RDF (Resource Description Framework) …