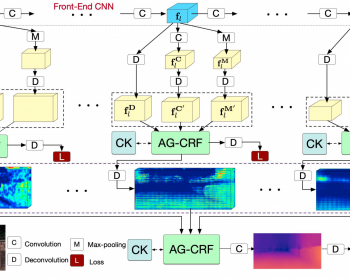
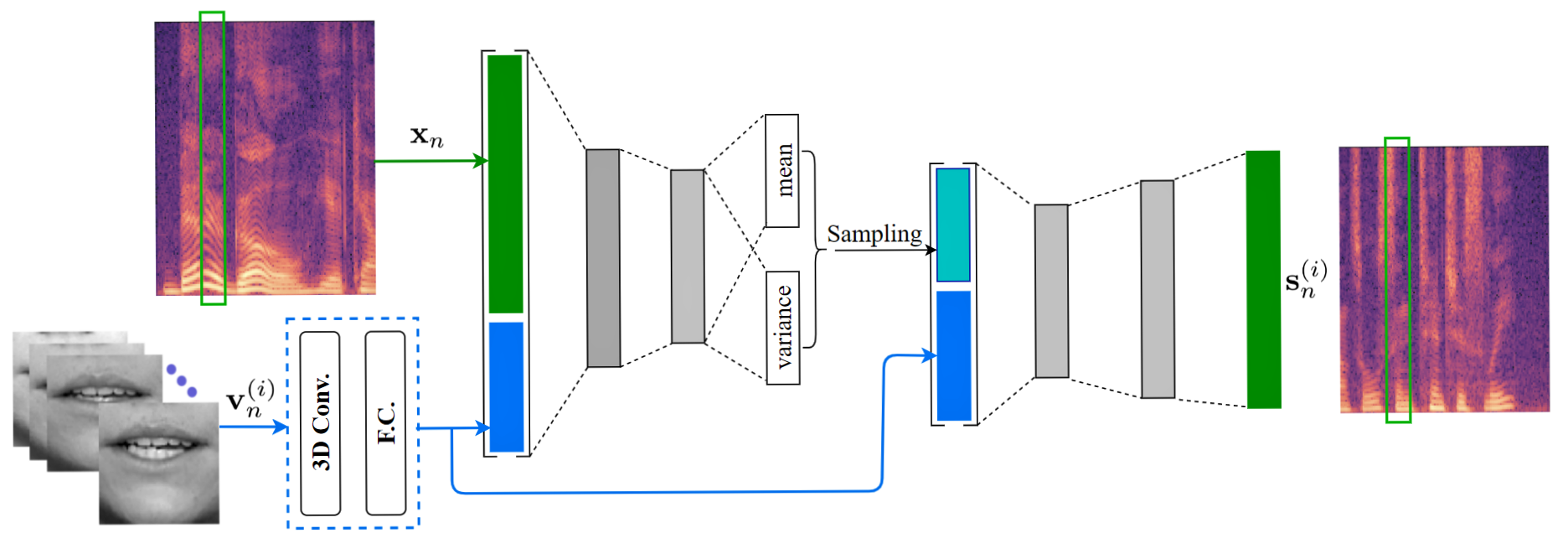
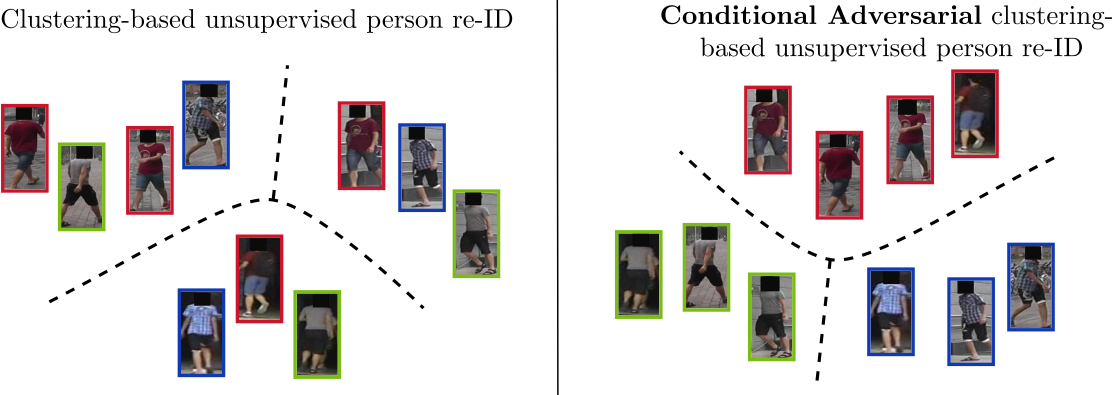
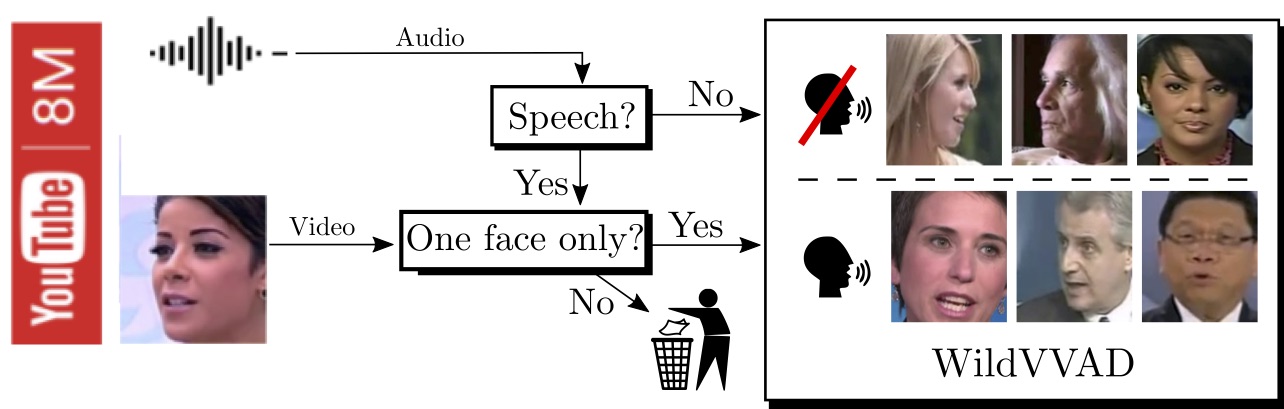
Variational Inference and Learning of Piecewise-linear Dynamical Systems

by Xavier Alameda-Pineda, Vincent Drouard, Radu Horaud IEEE TNNLS 2021 [PDF] [arXiv] Abstract Modeling the temporal behavior of data is of primordial importance in many scientific and engineering fields. Baseline methods assume that both the dynamic and observation equations follow linear-Gaussian models. However, there are many real-world processes that cannot be characterized by…