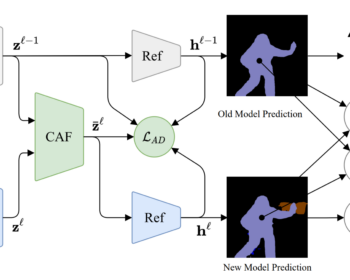
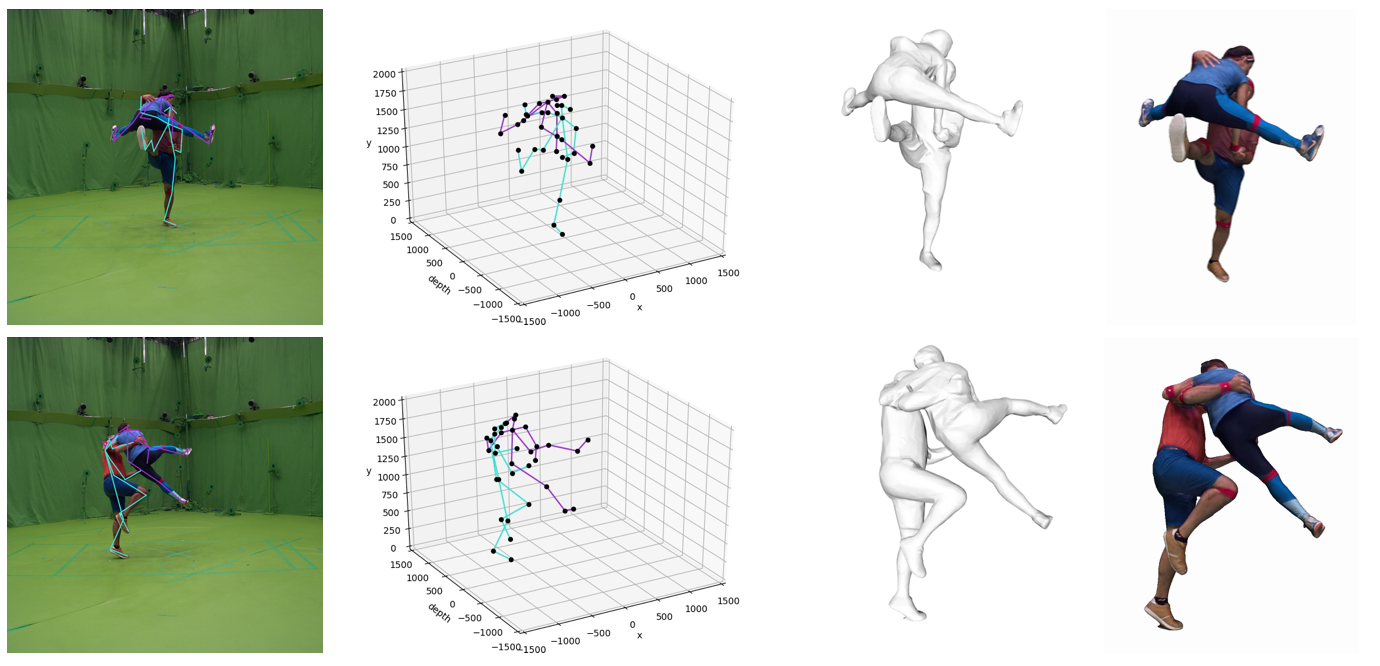
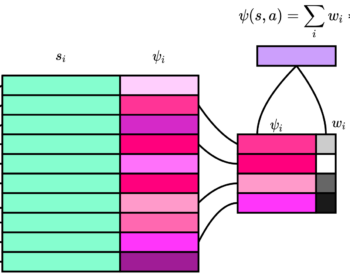
Variational meta-reinforcement learning for social robotics

by Anand Ballou, Xavier Alameda-Pineda, and Chris Reinke Applied Intelligence [paper][code] Abstract: With the increasing presence of robots in our everyday environments, improving their social skills is of utmost importance. Nonetheless, social robotics still faces many challenges. One bottleneck is that robotic behaviors often need to be adapted, as social…