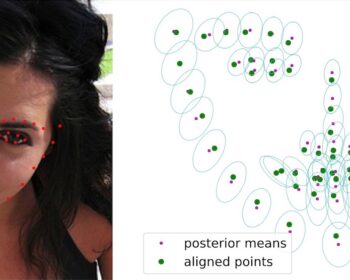
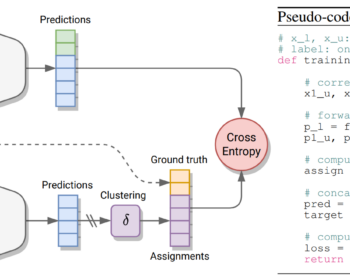
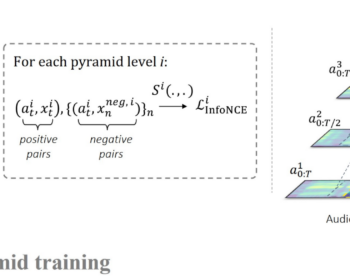A Multimodal Dynamical Variational Autoencoder for Audiovisual Speech Representation Learning

by Samir Sadok, Simon Leglaive, Laurent Girin, Xavier Alameda-Pineda, and Renaud Séguier Neural Networks [paper][demo][code] Abstract: In this paper, we present a multimodal \textit{and} dynamical VAE (MDVAE) applied to unsupervised audio-visual speech representation learning. The latent space is structured to dissociate the latent dynamical factors that are shared between the…