



Tatooine: lightweight data integration for heterogeneous data journalism
Data journalism oftentimes requires the ability to work with data sources of heterogeneous nature, such as: structured and unstructured databases (relational, XML, JSON, RDF, …), and also oftentimes text (comprised in HTML, Word, PDF etc.) As part of our ContentCheck project, we have developed Tatooine, a plan execution engine capable of integrating data extracted from sources of different nature, and of processing them together. For instance, Tatooine allows to enrich structured text, modeling Parliament debates, with metadata about the people who speak in these debates; such metadata is extracted from an RDF knowledge base, which integrates public information e.g. from DBPedia with handcrafted data sources whereas journalists or NGO activists gather useful information about public figures.
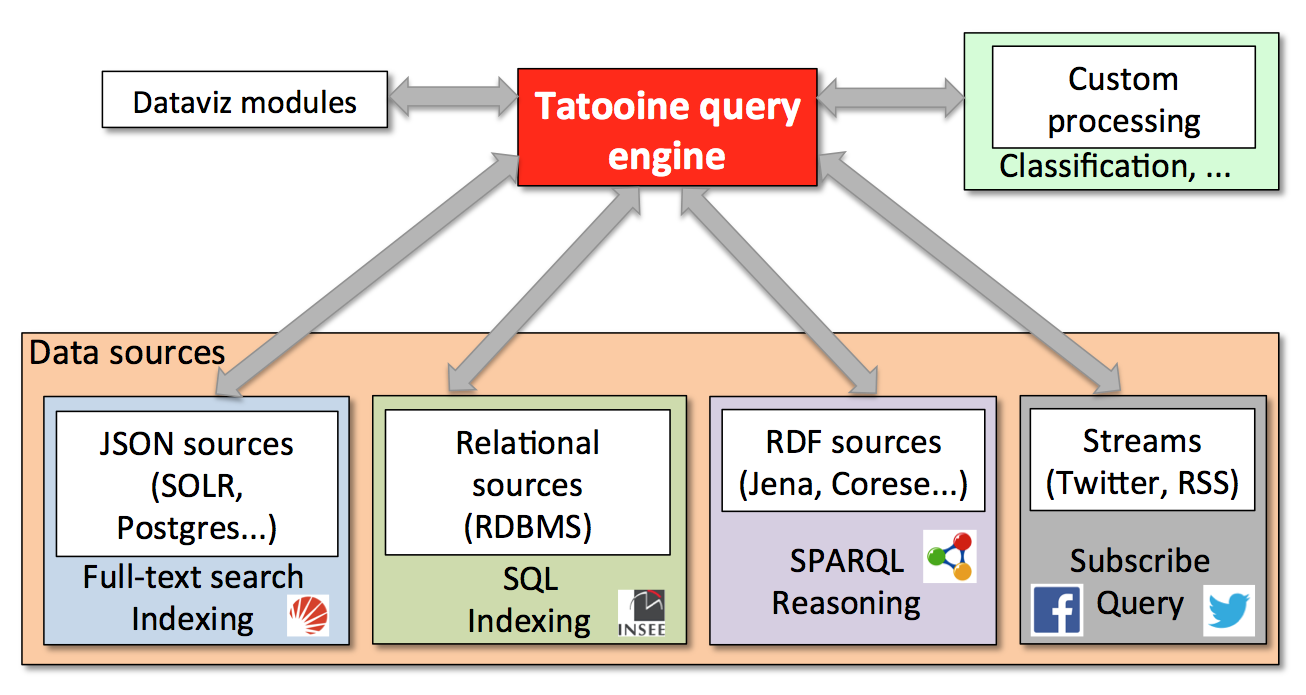 Beyond data processing, data journalism also requires the ability to integrate other functionalities, such as classifiers, visualization modules etc. Tatooine supports such primitives as user-defined functions, allowing, for instance, to:
Beyond data processing, data journalism also requires the ability to integrate other functionalities, such as classifiers, visualization modules etc. Tatooine supports such primitives as user-defined functions, allowing, for instance, to:
- identify the topics most related to published media articles (for instance: finance, foreign affairs etc.);
- for each topic, find the corresponding ministry in a knowledge based derived from DBPedia;
- with the help of a query over an RDF knowledge base, further the analysis by identifying e.g. the person in charge of each ministry.
Such a scenario demonstrates that classical query-style processing naturally mixes with analytics and visualization to help users make the most out of rich, heterogeneous data sources.
Publications:
- Mixed-instance querying: a lightweight integration architecture for data journalism Raphaël Bonaque, Tien Duc Cao, Bogdan Cautis, François Goasdoué, Javier Letelier, Ioana Manolescu, Oscar Mendoza, Swen Ribeiro, Xavier Tannier, Michaël Thomazo VLDB, Sep 2016, New Delhi, India. VLDB, <http://vldb2016.persistent.com/>

