



The scientific ambition of RobotLearn is to train robots to acquire the capacity to look, listen, learn, move and speak in a socially acceptable manner. This is being achieved via a fine tuning between scientific findings, development of practical algorithms and associated software packages, and thorough experimental validation. RobotLearn team members plan to endow robotic platforms with the ability to perform physically-unconstrained and open-domain multi-person interaction and communication. The roadmap of RobotLearn is twofold: (i) to build on the recent achievements of the Perception team, in particular, machine learning techniques for the temporal and spatial alignment of audio and visual data, variational Bayesian methods for unimodal and multimodal tracking of humans, and deep learning architectures for audio and audio-visual speech enhancement, and (ii) to explore novel scientific research opportunities at the crossroads of discriminative and generative deep learning architectures, Bayesian learning and inference, computer vision, audio/speech signal processing, spoken dialog systems, and robotics. The paramount applicative domain of RobotLearn is the development of multimodal and multi-party interactive methodologies and technologies for social (companion) robots. RobotLearn is a Research Team at the Inria Center of Université Grenoble Alpes, associated with Laboratoire Jean Kuntzman.
You might be interested in our publications, the open positions in the team, or the ongoing projects.
Recent news
- MEGA: Masked Generative Autoencoder for Human Mesh Recovery

by Guénolé Fiche, Simon Leglaive, Xavier Alameda-Pineda, Francesc Moreno-Noguer
IEEE International Conference on Computer Vision and Pattern Recognition
Abstract: Human Mesh Recovery (HMR) from a single RGB image is a highly ambiguous problem, as similar 2D projections can correspond to multiple 3D interpretations. Nevertheless, most HMR methods overlook this ambiguity and make a single prediction without accounting for the associated uncertainty. A few approaches generate a distribution of human meshes, enabling the sampling of multiple predictions; however, none of them is competitive with the latest single-output model when making a single prediction. This work proposes a new approach based on masked generative modeling. By tokenizing the human pose and shape, we formulate the HMR task as generating a sequence of discrete tokens conditioned on an input image. We introduce MEGA, a MaskEd Generative Autoencoder trained ...
- Diffusion-based Unsupervised Audio-visual Speech Enhancement
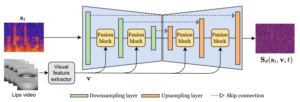
by Jean-Eudes Ayilo, Mostafa Sadeghi, Romain Serizel, Xavier Alameda-Pineda
IEEE International Conference on Audio, Speech, and Signal Processing
Abstract: —This paper proposes a new unsupervised audiovisual speech enhancement (AVSE) approach that combines a diffusion-based audio-visual speech generative model with a non-negative matrix factorization (NMF) noise model. First, the diffusion model is pre-trained on clean speech conditioned on corresponding video data to simulate the speech generative distribution. This pre-trained model is then paired with the NMF-based noise model to estimate clean speech iteratively. Specifically, a diffusion-based posterior sampling approach is implemented within the reverse diffusion process, where after each iteration, a speech estimate is obtained and used to update the noise parameters. Experimental results confirm that the proposed AVSE approach not only outperforms its audio-only counterpart but also generalizes better than a recent supervised-generative AVSE method. ...
- AnCoGen: Analysis, Control and Generation of Speech with a Masked Autoencoder
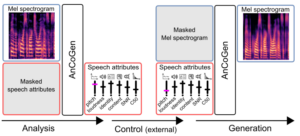
by Samir Sadok, Simon Leglaive, Laurent Girin, Gaël Richard, Xavier Alameda-Pineda
IEEE International Conference on Audio, Speech, and Signal Processing
Abstract: This article introduces AnCoGen, a novel method that leverages a masked autoencoder to unify the analysis, control, and generation of speech signals within a single model. AnCoGen can analyze speech by estimating key attributes, such as speaker identity, pitch, content, loudness, signal-to-noise ratio, and clarity index. In addition, it can generate speech from these attributes and allow precise control of the synthesized speech by modifying them. Extensive experiments demonstrated the effectiveness of AnCoGen across speech analysisresynthesis, pitch estimation, pitch modification, and speech enhancement.
- Lost and found: Overcoming detector failures in online multi-object tracking

by Lorenzo Vaquero, Yihong Xu, Xavier Alameda-Pineda, Víctor M Brea, Manuel Mucientes
European Conference on Computer Vision
Abstract: Multi-object tracking (MOT) endeavors to precisely estimate the positions and identities of multiple objects over time. The prevailing approach, tracking-by-detection (TbD), first detects objects and then links detections, resulting in a simple yet effective method. However, contemporary detectors may occasionally miss some objects in certain frames, causing trackers to cease tracking prematurely. To tackle this issue, we propose BUSCA, meaning ‘to search’, a versatile framework compatible with any online TbD system, enhancing its ability to persistently track those objects missed by the detector, primarily due to occlusions. Remarkably, this is accomplished without modifying past tracking results or accessing future frames, i.e., in a fully online manner. BUSCA generates proposals based on neighboring tracks, motion, and learned tokens. ...
- Vq-hps: Human pose and shape estimation in a vector-quantized latent space

by Guénolé Fiche, Simon Leglaive, Xavier Alameda-Pineda, Antonio Agudo, Francesc Moreno-Noguer
European Conference on Computer Vision
Abstract: Previous works on Human Pose and Shape Estimation (HPSE) from RGB images can be broadly categorized into two main groups: parametric and non-parametric approaches. Parametric techniques leverage a low-dimensional statistical body model for realistic results, whereas recent non-parametric methods achieve higher precision by directly regressing the 3D coordinates of the human body mesh. This work introduces a novel paradigm to address the HPSE problem, involving a low-dimensional discrete latent representation of the human mesh and framing HPSE as a classification task. Instead of predicting body model parameters or 3D vertex coordinates, we focus on predicting the proposed discrete latent representation, which can be decoded into a registered human mesh. This innovative paradigm offers two key advantages. Firstly, predicting a ...
- Navigating the Practical Pitfalls of Reinforcement Learning for Social Robot Navigation
by Dhimiter Pikuli, Jordan Cosio, Xavier Alameda-Pineda, Pierre-Brice Wieber, Thierry Fraichard
Robotics: Science and Systems (RSS) Workshop on Unsolved Problems in Social Robot Navigation
Navigation is one of the essential tasks in order for robots to be deployed in environments shared with humans. The problem becomes increasingly complex when taking in consideration that the robot’s behaviour should be suitable to humans. This is referred to as social navigation and it is a cognitive task that us humans pay little attention to as it comes naturally. Since crafting a model of the environment dynamics that faithfully characterises how humans navigate seems an impossible task, we look on the side of learning-based approaches and especially reinforcement learning. In this paper we are interested in drawing conclusions on the vast number of design choices when training a navigation agent using reinforcement learning. ...
- Learning for Companion Robots: Preparation and Adaptation

Xavier Alameda-Pineda was a keynote speaker at RFIAP/cAP 2024, on the topic of Learning for Companion Robots: Preparation and Adaptation.
- A weighted-variance variational autoencoder model for speech enhancement
by Ali Golmakani, Mostafa Sadeghi, Xavier Alameda-Pineda, Romain Serizel
Abstract: We address speech enhancement based on variational autoencoders, which involves learning a speech prior distribution in the timefrequency (TF) domain. A zero-mean complex-valued Gaussian distribution is usually assumed for the generative model, where the speech information is encoded in the variance as a function of a latent variable. In contrast to this commonly used approach, we propose a weighted variance generative model, where the contribution of each spectrogram time-frame in parameter learning is weighted. We impose a Gamma prior distribution on the weights, which would
effectively lead to a Student’s t-distribution instead of Gaussian for speech generative modeling. We develop efficient training and speech enhancement algorithms based on the proposed generative
model. Our experimental results on spectrogram auto-encoding and speech enhancement demonstrate the effectiveness and robustness of the proposed approach ... - Univariate Radial Basis Function Layers: Brain-inspired Deep Neural Layers for Low-Dimensional Inputs
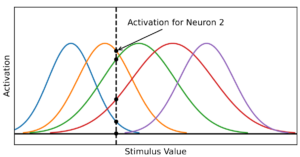
by Daniel Jost, Basavasagar Patil, Xavier Alameda-Pineda, and Chris Reinke
Abstract: Deep Neural Networks (DNNs) became the standard tool for function approximation with most of the introduced architectures being developed for high-dimensional input data. However, many real-world problems have low-dimensional inputs for which the standard Multi-Layer Perceptron (MLP) are a common choice. An investigation into specialized architectures is missing. We propose a novel DNN input layer called the Univariate Radial Basis Function (U-RBF) Layer as an alternative. Similar to sensory neurons in the brain, the U-RBF Layer processes each individual input dimension with a population of neurons whose activations depend on different preferred input values. We verify its effectiveness compared to MLPs and other state-of-the-art methods in low-dimensional function regression tasks. The results show that the U-RBF Layer is especially advantageous when the target function ...
- Robust audio-visual contrastive learning for proposal-based self-supervised sound source localization in videos
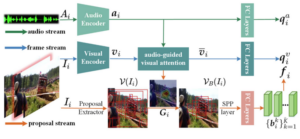
by Hanyu Xuan, Zhiliang Wu, Jian Yang, Bo Jiang, Lei Luo, Xavier Alameda-Pineda, Yan Yan
IEEE Transactions on Pattern Analysis and Machine Intelligence
Abstract: By observing a scene and listening to corresponding audio cues, humans can easily recognize where the sound is. To achieve such cross-modal perception on machines, existing methods take advantage of the maps obtained by interpolation operations to localize the sound source. As semantic object-level localization is more attractive for prospective practical applications, we argue that these map-based methods only offer a coarse-grained and indirect description of the sound source. Additionally, these methods utilize a single audio-visual tuple at a time during selfsupervised learning, causing the model to lose the crucial chance to reason about the data distribution of large-scale audio-visual samples. Although the introduction of Audio-Visual Contrastive Learning (AVCL) can effectively alleviate this issue, the contrastive set constructed by randomly ...