



by Laurent Girin, Simon Leglaive, Xiaoyu Bie, Julien Diard, Thomas Hueber, and Xavier Alameda-Pineda
Foundations and Trends in Machine Learning, 2021, Vol. 15, No. 1-2, pp 1–175.
[Review paper] [Code] [Tutorial @ICASPP 2021]
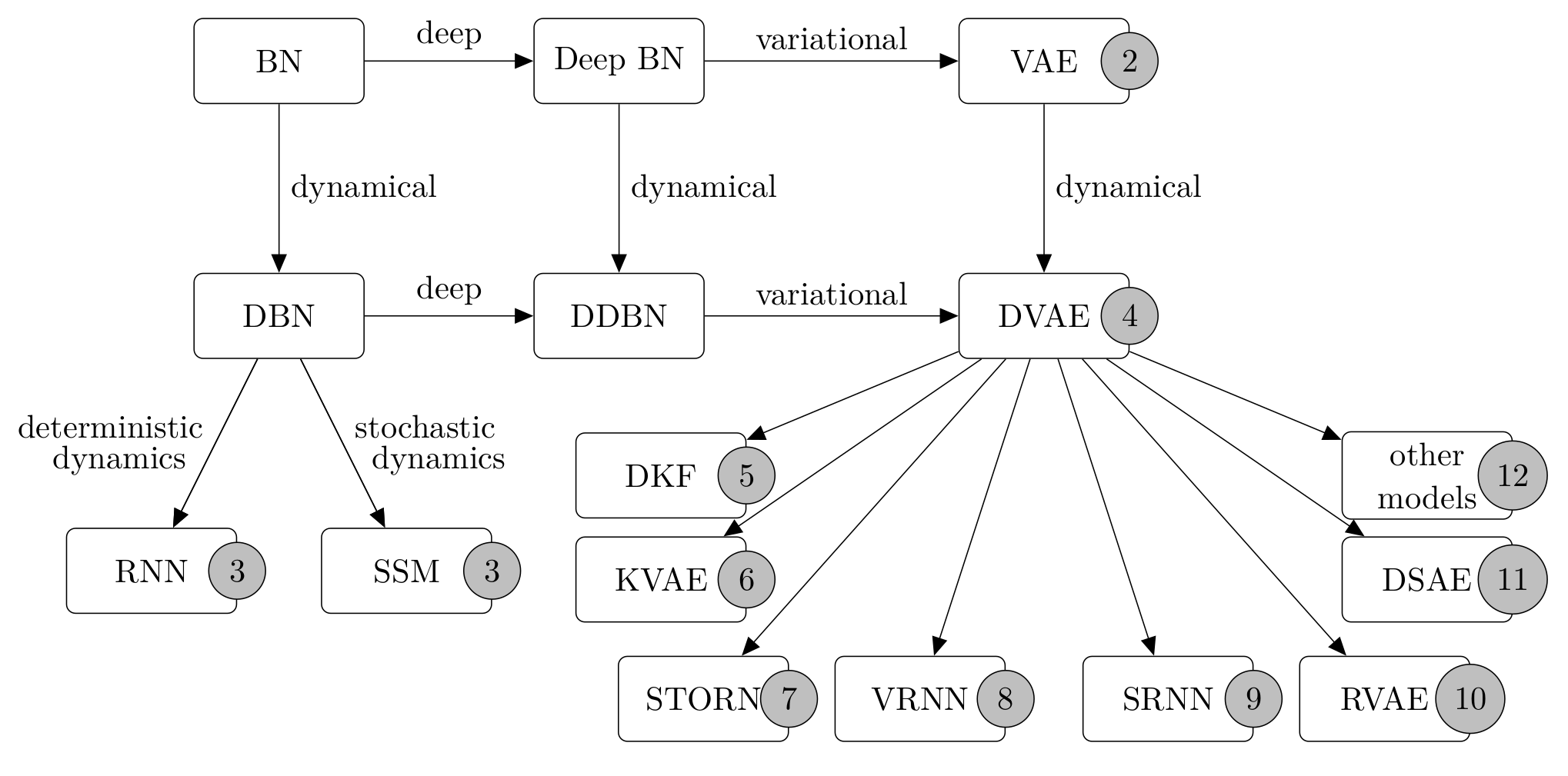
DVAE overview
Abstract. Variational autoencoders (VAEs) are powerful deep generative models widely used to represent high-dimensional complex data through a low-dimensional latent space learned in an unsupervised manner. In the original VAE model, the input data vectors are processed independently. Recently, a series of papers have presented different extensions of the VAE to process sequential data, which model not only the latent space but also the temporal dependencies within a sequence of data vectors and corresponding latent vectors, relying on recurrent neural networks or state-space models. In this paper, we perform a literature review of these models. We introduce and discuss a general class of models, called dynamical variational autoencoders (DVAEs), which encompasses a large subset of these temporal VAE extensions. Then, we present in detail seven recently proposed DVAE models, with an aim to homogenize the notations and presentation lines, as well as to relate these models with existing classical temporal models. We have reimplemented those seven DVAE models and presented the results of an experimental benchmark conducted on the speech analysis-resynthesis task (the PyTorch code is made publicly available). The paper concludes with a discussion on important issues concerning the DVAE class of models and future research guidelines.
Results
For speech data, using:
- training dataset: wsj0_si_tr_s
- validation dataset: wsj0_si_dt_05
- test dataset: wsj0_si_et_05
| Models | SI-SDR | PESQ MOS | ESTOI |
| VAE | 5.3 | 2.97 | 0.83 |
| DKF | 9.3 | 3.53 | 0.91 |
| STORN | 6.9 | 3.42 | 0.90 |
| VRNN | 10.0 | 3.61 | 0.92 |
| SRNN | 11.0 | 3.68 | 0.93 |
| RVAE-Causal | 9.0 | 3.49 | 0.90 |
| RVAE-NonCausal | 8.9 | 3.58 | 0.91 |
| DSAE | 9.2 | 3.55 | 0.91 |
| SRNN-TF-GM | -1.0 | 1.93 | 0.64 |
| SRNN-GM | 7.8 | 3.37 | 0.88 |
For human motion data, using:
- training dataset: S1, S6, S7, S8, S9
- validation dataset: S5
- test dataset: S11
| Models | MPJPE (mm) |
| VAE | 48.69 |
| DKF | 42.21 |
| STORN | 9.47 |
| VRNN | 9.22 |
| SRNN | 7.86 |
| RVAE-Causal | 31.09 |
| RVAE-NonCausal | 28.59 |
| DSAE | 28.61 |
| SRNN-TF-GM | 221.87 |
| SRNN-GM | 43.98 |
Audio examples
| Models | 440c0201 | 441c0201 | 442c0201 |
| Clean |
|
|
|
| VAE |
|
|
|
| DKF |
|
|
|
| STORN |
|
|
|
| VRNN |
|
|
|
| SRNN |
|
|
|
| RVAE-Causal |
|
|
|
| RVAE-NonCausal |
|
|
|
| DSAE |
|
|
|
| SRNN-TF-GM |
|
|
|
| SRNN-GM |
|
|
|
Motion examples
- Ground truth (skeleton in light color)
- Resynthesis (skeleton in dark color)
| Models | eating | greeting | walking |
| VAE |
|
|
|
| DKF |
|
|
|
| STORN |
|
|
|
| VRNN |
|
|
|
| SRNN |
|
|
|
| RVAE-Causal |
|
|
|
| RVAE-NonCausal |
|
|
|
| DSAE |
|
|
|
| SRNN-TF-GM |
|
|
|
| SRNN-GM |
|
|
|
List of applications.
- Spectrogram and 3D human data modeling
- Speech enhancement
- Unsupervised multiple object tracking
- Human motion generation
Generation examples.