Our key insight is that machine learning itself can deal well with errors, qualitative and noisy data. Hence, we aim to do statistical analysis directly on heterogeneous data. The ongoing projects are:
-
- Joint analysis of heterogeneous data sources
- Learning from dirty categorical data
- Using large corpora of neuroimaging studies for brain mapping
- Crawling and structuring Open Data
- Missing Data in the Big Data Era
Joint analysis of heterogeneous data sources
The tech world is abuzz with ‘big data’, in which many observations of the same phenomenon enable building very rich data-driven models. However, for a wide variety of fields of study, observations are difficult to acquire and require performing manual operations. Conversely, the growth in dimensionality of the data with a limited number of observation leads to a challenging statistical problem, the curse of dimensionality. Yet, many application fields face an accumulation of weakly-related datasets with observations of different nature and from numerous related data acquisitions.
The goal of this project is to develop a statistical-learning framework that can leverage the weak links across datasets to improve the statistical task on each of the dataset. Technically, one option to explore would be to learn latent factors, or ‘representations’ as they are called in deep learning, common to the multiple tasks. Non-linear mappings or kernels may be necessary to deal with the multiple nature of the data. This framework should help using a wide variety of datasets to improve prediction in specific, separate tasks.
Learning from dirty categorical data
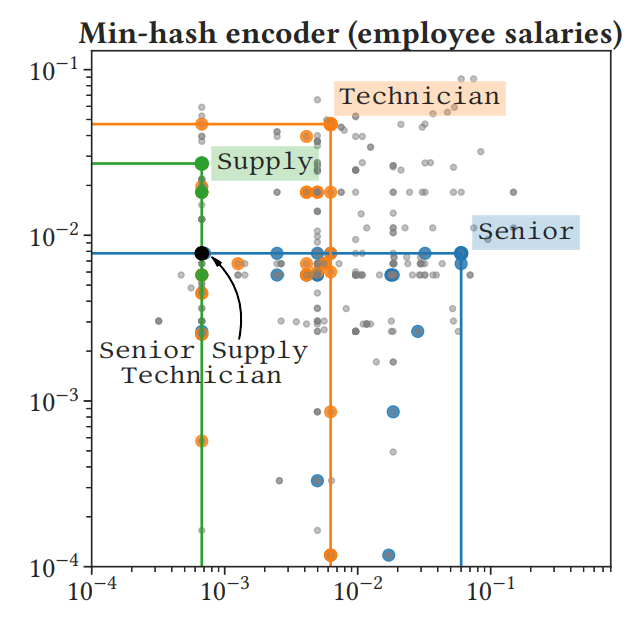 Most statistical learning algorithms require a numerical feature matrix as input . In the presence of categorical variables in the data, feature engineering is needed to encode the different categories into a suitable feature vector. In controlled data-collection settings, categorical variables are standardized: the set of categories is finite, well-known a priori and categories are mutually exclusive. In this case, the common approach is to use one-hot encoding.
Most statistical learning algorithms require a numerical feature matrix as input . In the presence of categorical variables in the data, feature engineering is needed to encode the different categories into a suitable feature vector. In controlled data-collection settings, categorical variables are standardized: the set of categories is finite, well-known a priori and categories are mutually exclusive. In this case, the common approach is to use one-hot encoding.
On the contrary, many of real-world data contain non-standardized categorical variables, which can arise from a variety of mechanisms: typographical errors, use of special characters, concatenated hierarchical data, etc. From a data-integration point of view, “dirty” categories may be seen as a data cleaning problem, addressed, for instance, with entity resolution. The goal of this project is to study novel methods to represent dirty categories in a robust way in order to perform statistical learning without a data-cleaning step.
One simple approach to solve to this problem is similarity encoding, which creates embeddings based on morphological string similarities. Implementations and examples on learning with dirty categories can be found in the Python package dirty-cat.
This research is supported by the DirtyData project.
Using large corpora of neuroimaging studies for brain mapping.
Crawling and structuring Open Data
Machine learning has inspired new markets and applications by extracting new insights from complex and noisy data. However, to perform such analyses, the most costly step is often to prepare the data. It entails correcting input errors and inconsistencies as well as transforming the data into a single matrix-shaped table that comprises all interesting descriptors for all observations to study.
This project aims to explore these concerns using French open data.
Missing Data in the Big Data Era

‘Big data’, often observational and compound, rather than experimental and homogeneous, poses missing-data challenges: missing values are structured, non independent of the outcome variables of interest. Deleting incomplete observations creates at best information losses, at worst warped conclusions due to a selection bias.
MissingBigData is funded by Institute DATAIA. The project is motivated by applications in medical data (with tabular data), with the Traumabase and UK Biobank, which feature a great diversity of missing values. In particular, we would like to tackle the problem of causal inference when the data is incomplete.
We propose to use more powerful models that can benefit from the large sample sizes, specifically autoencoders, to impute the missing values, even when they are generated by a non ignorable mechanism. We also consider alternatives to imputation, by directly adapting models such as random forests to handle missing values in the features.
This project also lead to contribute to open source project, as the website platform for missing values and to scikit-learn project.
MissingBigData is a joint work between Parietal, CMAP and CNRS.
- PhD candidate: Nicolas Prost
- PostDoc: Marine Le Morvan
- Research engineer: Thomas Schmitt
- Parietal: Gaël Varoquaux, Alexandre Gramfort
- CMAP: Julie Josse, Erwan Scornet
- CNRS: Balázs Kégl.
An introductory interview of Julie and Gaël on MissingBigData.
