 An open source tool for training STT models.
An open source tool for training STT models.
Overview
COMPRISE Weakly Supervised Speech-to-Text (STT) provides components for semi-supervised and weakly supervised training of STT Acoustic Models (AMs) and Language Models (LMs), thus reducing the need for time-consuming and expensive manual transcription of speech data. It consists of three components.
- Error detection driven training component: processes untranscribed speech data to obtain automatic transcripts along with tags representing reliable and unreliable regions, and finally performs semi-supervised training of STT models.
- Dialogue state based training component: exploits weak supervision from utterance level dialogue state labels to obtain better automatic transcriptions on untranscribed speech data, and hence better STT models.
- Confusion network based language model training component: trains statistical n-gram LMs and Recurrent Neural Network (RNN) LMs using STT confusion networks obtained from untranscribed speech data.
Example of “Error detection driven semi-supervised AM training. Dashed arrows indicate ‘use for training’”
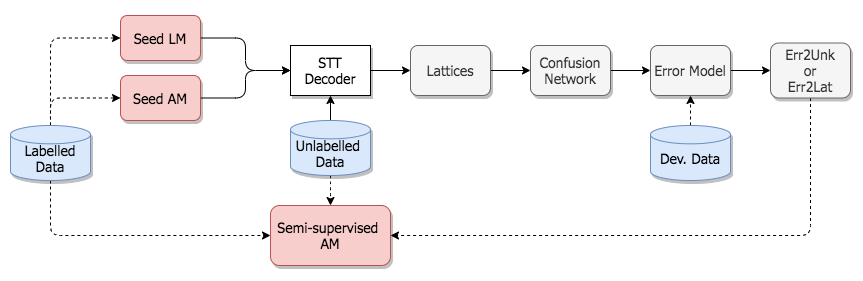
Readers interested in the high-level design and experimental evaluation of these components can refer to COMPRISE deliverables D4.2 and D4.4.
Features
- Semi-supervised and weakly supervised training of STT models
- Readily supports the Kaldi speech recognition toolkit
- Examples for training with state-of-the-art TDNN Chain AMs and LF-MMI
- Methods that generalise to other types of STT AMs and LMs
- Support to train RNN/LSTM/GRU LMs in Pytorch and use with Kaldi
- Tools to train STT error detection models
- Learn n-gram and RNN LMs from STT confusion networks
- Interpolated expected KN smoothing for training n-gram LMs from fractional counts
Requirements
- Kaldi toolkit
- Python 3.X
- Numpy 1.19
- PyTorch 1.5.1
Recommended usage in combination with the COMPRISE Cloud Platform.
Documentation & Download
![]() Installation & Usage guide (video)
Installation & Usage guide (video)
![]() Code and documentation (Gitlab)
Code and documentation (Gitlab)
For scientific details and experimental results, refer to the following paper: I. Sheikh, E. Vincent, I. Illina, “On semi-supervised LF-MMI training of acoustic models with limited data“, in Interspeech, 2020.