
Continuity editing of 3D animation (AAAI 2015)

We describe an optimization-based approach for automatically creating well-edited movies from a 3D animation. We review the main causes of editing errors in literature and propose an edit-ing model relying on a minimization of such errors. We make a plausible semi-Markov assumption, resulting in a dynamic programming solution which is computation-ally efficient. We also show that our method can generate movies with different editing rhythms and validate the results through a user study. Combined with state-of-the-art cinematography, our approach therefore promises to significantly extend the expressiveness and naturalness of virtual movie-making.
See the video. Read the paper.
Space-time sketching of character animation (SIGGRAPH’2015)

We present a space-time abstraction for the sketch-based design of character animation. It allows animators to draft a full coordinated motion using a single stroke called the space-time curve (STC). Our dynamic models for the line’s motion are entirely geometric, require no pre-existing data, and allow full artistic control.
Vector Graphics Animation with Time-Varying Topology (SIGGRAPH 2015)
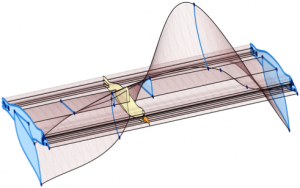
We introduce the Vector Animation Complex (VAC), a novel data structure for vector graphics animation, designed to support the modeling of time-continuous topological events. This allows features of a connected drawing to merge, split, appear, or disappear at desired times via keyframes that introduce the desired topological change. Because the resulting space-time complex directly captures the time-varying topological structure, features are readily edited in both space and time in a way that reflects the intent of the drawing. A formal description of the data structure is provided, along with topological and geometric invariants. We illustrate our modeling paradigm with experimental results on various examples.
Multi-Clip Video Editing from a Single Viewpoint (CVMP 2014)
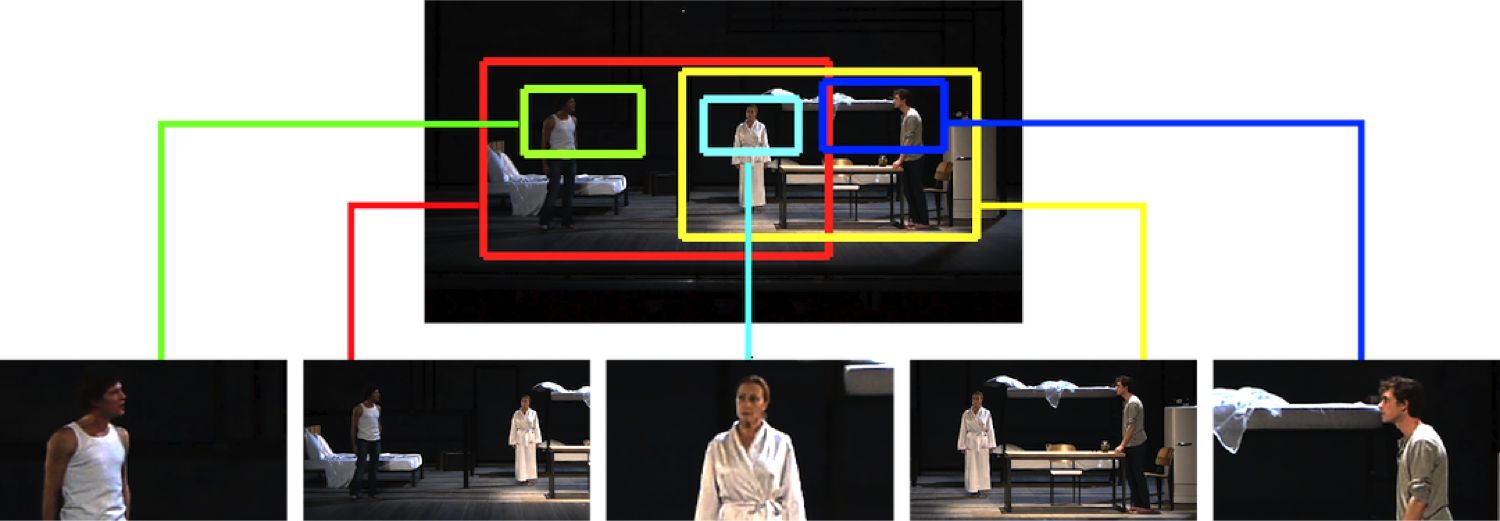
We propose a framework for automatically generating multiple clips suitable for video editing by simulating pan-tilt-zoom camera movements within the frame of a single static camera. Assuming important actors and objects can be localized using computer vision techniques, our method requires only minimal user input to define the subject matter of each sub-clip. The composition of each sub-clip is automatically computed in a novel L1-norm optimization framework. Our approach encodes several common cinematographic practices into a single convex cost function minimization problem, resulting in aesthetically pleasing sub-clips which can easily be edited together using off-the-shelf multi-clip video editing software. We demonstrate our approach on five video sequences of a live theatre performance by generating multiple synchronized subclips for each sequence
Beyond Basic Emotions: Expressive Virtual Actors with Social Attitudes (MIG 2014)

The purpose of this work is to evaluate the contribution of audiovisual prosody to the perception of complex mental states of virtual actors. We propose that global audio-visual prosodic contours – i.e. melody, rhythm and head movements over the utterance – constitute discriminant features for both the generation and recognition of social attitudes. The hypothesis is tested on an acted corpus of social attitudes in virtual actors and evaluation is done using objective measures and perceptual tests.
Vector Graphics Complexes (SIGGRAPH 2014)

Basic topological modeling, such as the ability to have several faces share a common edge, has been largely absent from vector graphics. We introduce the vector graphics complex (VGC) as a simple data structure to support fundamental topological modeling operations for vector graphics illustrations. The VGC can represent any arbitrary non-manifold topology as an immersion in the plane, unlike planar maps which can only represent embeddings. This allows for the direct representation of incidence relationships between objects and can therefore more faithfully capture the intended semantics of many illustrations, while at the same time keeping the geometric flexibility of stacking-based systems.
Detecting and Naming Actors in Movies using Generative Appearance Models (CVPR 2013)
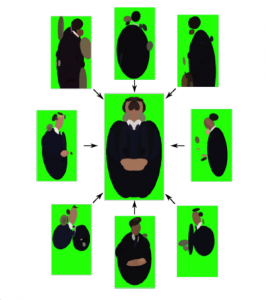
We introduce a generative model for learning person and costume specific detectors from labeled examples. We demonstrate the model on the task of localizing and naming actors in long video sequences. More specifically, the actor’s head and shoulders are each represented as a constellation of optional color regions. Detection can proceed despite changes in view-point and partial occlusions. We explain how to learn the models from a small number of labeled keyframes or video tracks, and how to detect novel appearances of the actors in a maximum likelihood framework. We present results on a challenging movie example, with 81% recall in actor detection (coverage) and 89% precision in actor identification (naming).
The Line of Action: an Intuitive Interface for Expressive Character Posing (SIGGRAPH ASIA 2013)

The line of action is a conceptual tool often used by cartoonists and illustrators to help make their figures more consistent and more dramatic. We often see the expression of characters–may it be the dynamism of a super hero, or the elegance of a fashion model–well captured and amplified by a single aesthetic line. Usually this line is laid down in early stages of the drawing and used to describe the body’s principal shape. By focusing on this simple abstraction, the person drawing can quickly adjust and refine the overall pose of his or her character from a given viewpoint. In this paper, we propose a mathematical definition of the line of action (LOA), which allows us to automatically align a 3D virtual character to a user specified LOA by solving an optimization problem. We generalize this framework to other types of lines found in the drawing literature, such as secondary lines used to place arms. Finally, we show a wide range of poses and animations that were rapidly created using our system.