



Abstra: Toward Generic Abstractions for Data of Any Model
Teaser video
Case Studies

The dataset abstraction of the XMark dataset (3M nodes, 3M edges), describing auctions on an online website.

The dataset abstraction of the NASA dataset (140K nodes, 174K edges), describing spacecraft launches.
Gallery
Below, we provide the Entity-Relationship schema of each dataset we epxerimented on.
JSON
- CoreResearch
- DeFacto
- Github
- NYTimes
- Prescriptions
- Researchers
- YelpBusiness
- YelpCheckin
- YelpTips
RDF
XML
Download
Abstra is a software developed in Java and using Postgres to store data that you can download at the following link:
https://gitlab.inria.fr/cedar/abstra
Results: user study results are available in the GitLab repository and in this ZIP file.
Publications
When referring to this work, please cite the article published in EDBT 2024.
- Nelly Barret, Ioana Manolescu, Prajna Upadhyay. Computing Generic Abstractions from Application Datasets. EDBT 2024 (research paper).
- Nelly Barret, Ioana Manolescu, Prajna Upadhyay. Computing Generic Abstractions from Application Datasets. BDA 2023 (informal publication).
- Nelly Barret, Ioana Manolescu, Prajna Upadhyay. Abstra: Toward Generic Abstractions for Data of Any Model. CIKM 2022 (demonstration paper).
- Nelly Barret, Ioana Manolescu, Prajna Upadhyay. Abstra: Toward Generic Abstractions for Data of Any Model. BDA 2022 (informal publication).
- Nelly Barret, Ioana Manolescu, Prajna Upadhyay. Towards Generic Abstractions for Data of Any Model. BDA 2021 (short paper).
- Nelly Barret. Facilitating Heterogenous Dataset Understanding. BDA 2021 (PhD paper).
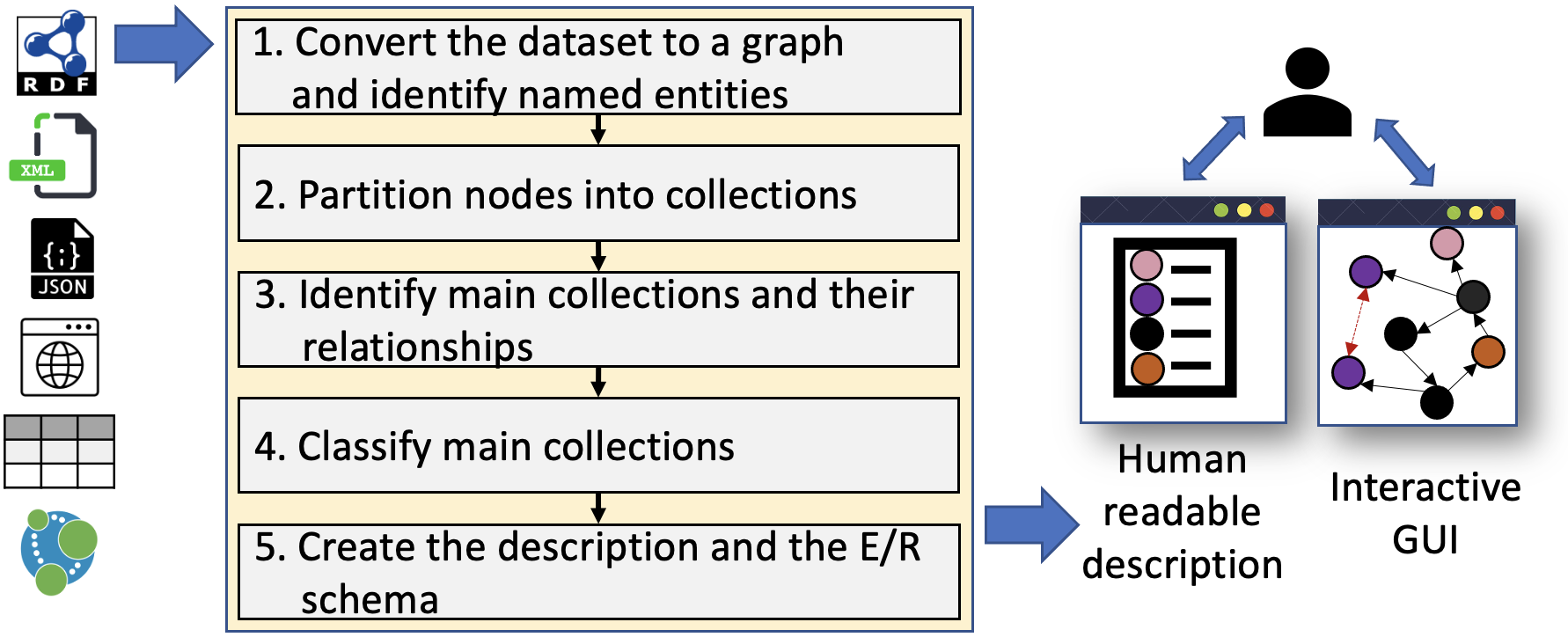
How to read a description?
A description contains the main entity collections classified and their relationships. The output presents on the left the natural language description and on the right the Entity/Relation schema. For a given entity collection, you have the following information: its name, its size (number in parentheses) and the properties of the records that are in the collection. For each property, you have its name and its frequency in the collection records. Finally, the relationships linking entity collections are described with their name.