Problems may occur when software encounters a character not supported by its designated encoding, resulting in errors such as character replacements or omissions. This tutorial provides guidance on preventing and resolving issues related to character encoding.
What are character encodings?
Human languages (think French, English, Chinese etc.) but also other sets of symbols (think math, emojis, etc.) have led to the need to represent numerous symbols each as a character of a character set. A character is encoded on a small number of bytes (one, two). A character set is: a finite set of characters, together with an encoding (that is, sequence of bytes) of each character present in the set.
Where are character encodings present?
A character encoding is present whenever a piece of software does something with a character (or more characters, such as a string, or a file). For instance:
- When typing characters on a keyboard, the terminal expects a certain character encoding
- When storing a file in a file system, the file system views the file as using a certain character encoding
- When looking at a file in a file editor, the editor uses a certain character encoding
- When creating a database in Postgres, one can assign it a given character encoding through a dedicated parameter
- When reading a database in Postgres, the client program (psql) also uses its own character encoding.
What character encoding is best?
We usually need one large enough to include accented French, Spanish (remember the reverse question mark in Spanish!) or German letters. For our daily needs, ==UTF8== does this and is the best. It makes sense to use it whenever there is no strong specific requests to use another encoding; and it makes sense not to use any character encoding that has fewer characters than UTF8.
Below, we consider UTF8 to be the reference encoding. If you need any other encoding E, just replace UTF8 by E everywhere below. It is sometimes possible to handle characters encoded using an encoding E1, with a software that is configured to use another encoding E2 (if E2 somehow subsumes or extends E1). However, this makes for complicated settings, and will not be considered below.
What can go wrong with character encodings?
If a software encounters a character that is not in the character encoding that the software expects, this leads to an error. The software may then handle the error in one of the following ways:
- Silently replace the character with the closest equivalent, e.g., if the software does not expect
é, it will showe. - Not show the character at all, e.g.,
HernàndezbecomesHernndez. - Show something very ugly instead of the character not being handled, e.g., an unprintable character.
- Complain, e.g., refuse to save a file containing a character that is not in the set associated to the file.
- Break, i.e., throw an error of some sort.
Note that most of the above may lead to other hard-to-catch errors down the road. For instance:
- a replacement of
éwithemay lead to similar but different names somewhere; - a replacement of
HernàndezwithHernndezmay make an entity extraction fail because the extractor has never seen such a name; - a string may fail to be saved in a database, throwing an error or not (depending on how the code is written), etc.
Therefore, it’s important to avoid or solve such problems.
How to avoid or solve character encoding problems?
Try to enforce UTF8 all over:
- Make sure all new files are in UTF8 encoding. You can find out a file’s encoding using the
filecommand, like this:ioanamanolescu@im22 submission % file the.bib the.bib: BibTeX text file, UTF-8 Unicode text, with very long lines
- If needed, you can change a file’s encoding, see e.g., https://stackoverflow.com/questions/132318/how-do-i-correct-the-character-encoding-of-a-file. You will have succeeded when the
filecommand returnsUTF8. - Make sure your shell uses UTF8. This will help you view correctly the contents of UTF8 files, and that your terminal is not changing file encodings even without your being aware of it, e.g., when you create a new file by pasting in the terminal and saving it, or when copying or downloading a file, etc. https://stackoverflow.com/questions/5306153/how-to-get-terminals-character-encoding gives some hints on how to find and change your terminal’s encoding. The command
localeshows the values known by your current shell, of the environment variables related to the character encoding and language:
ioanamanolescu@im22 submission % locale
LANG=""
LC_COLLATE="C"
LC_CTYPE="UTF-8"
LC_MESSAGES="C"
LC_MONETARY="C"
LC_NUMERIC="C"
LC_TIME="C"
LC_ALL=
The above page suggests changing the value of the LC_ALL environment varriable to control the default language and default character encoding, by including in one’s .bashrc:
$ export LC_ALL=pt_PT.utf8
$ export LANG="$LC_ALL"
Note that remotely connecting from a computer to another may attempt to set the locale on the remote machine, even if you did not intend it.
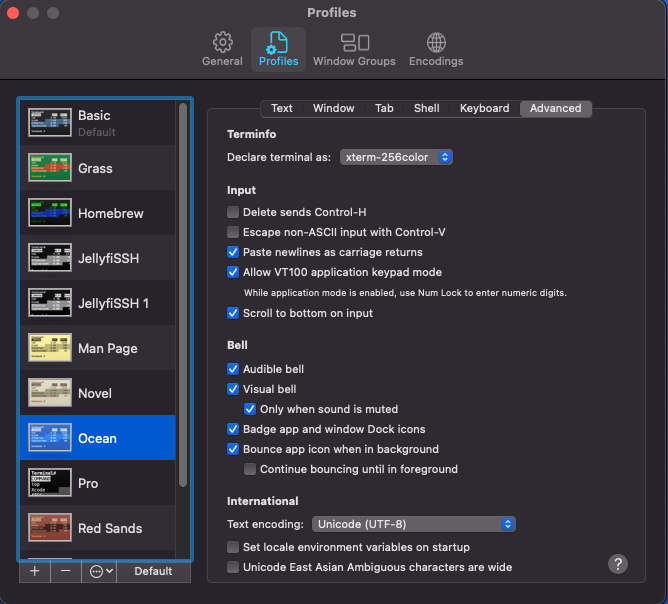
- When connecting from a Mac to another machine, to avoid such imposition, uncheck the box “Set locale environment variables at start-up” at the bottom in this menu that shows up in Terminal > Preferences > Advanced
- Make sure every newly created database is in UTF8, e.g., for Postgres (https://www.postgresql.org/docs/current/multibyte.html), but likely also for other systems since it is probably part of the SQL standard:
initdb -E UTF8- Make sure every client connecting to the database uses UTF8
- E.g., for the Postgres interactive client (https://www.postgresql.org/docs/current/multibyte.html)
SET CLIENT_ENCODING TO 'UTF8';- For a JDBC connection: https://docs.faircom.com/doc/v11rel/62494.htm says we can compose connections URLs of the form
jdbc:ctree:port@host_name:db_name?characterEncoding=UTF-8but this does not seem to be part of the JDBC standard. MORE INFO/RESOLUTION NEEDED HERE
tmuxalso brings its own encoding issues:
tmux attempts to guess if the terminal is likely to support UTF-8 by checking the first of the LC_ALL, LC_CTYPE and LANG environment variables to be set
for the string “UTF-8”. This is not always correct:
the -u flag explicitly informs tmux that UTF-8 is supported.