Task 1.1 Unified Data Management for Hybrid Analytics
Due to an ever-growing digitalization of the everyday life, massive amounts of data start to be accumulated, providing larger and large volumes of historical data (past data) on more and more monitored systems. At the same time, an up-to-date vision of the actual status of these systems is offered by the increasing number of sources of real-time data (present data). Today’s data analytics systems correlate these two types of data (past and present) to predict the future evolution of the systems to enable decision making. However, the relevance of such decisions is limited by the knowledge already accumulated in the past. Our vision consists in improving this decision process by enriching the knowledge acquired based on past data with what could be called future data generated by simulations of the system behavior under various hypothetical conditions that have not been met in the past.
Activity in 2020
Sub-goal 3: To enable the deployment of the Sigma architecture (introduced in 2019) atop complex hybrid Edge/Cloud environments, a rigorous methodology is needed. We aim to provide a platform able to implement such a methodology and allow seamless deployment of analytics frameworks on the Computing Continuum (formed by aggregated, hybrid Edge to Cloud ressources).
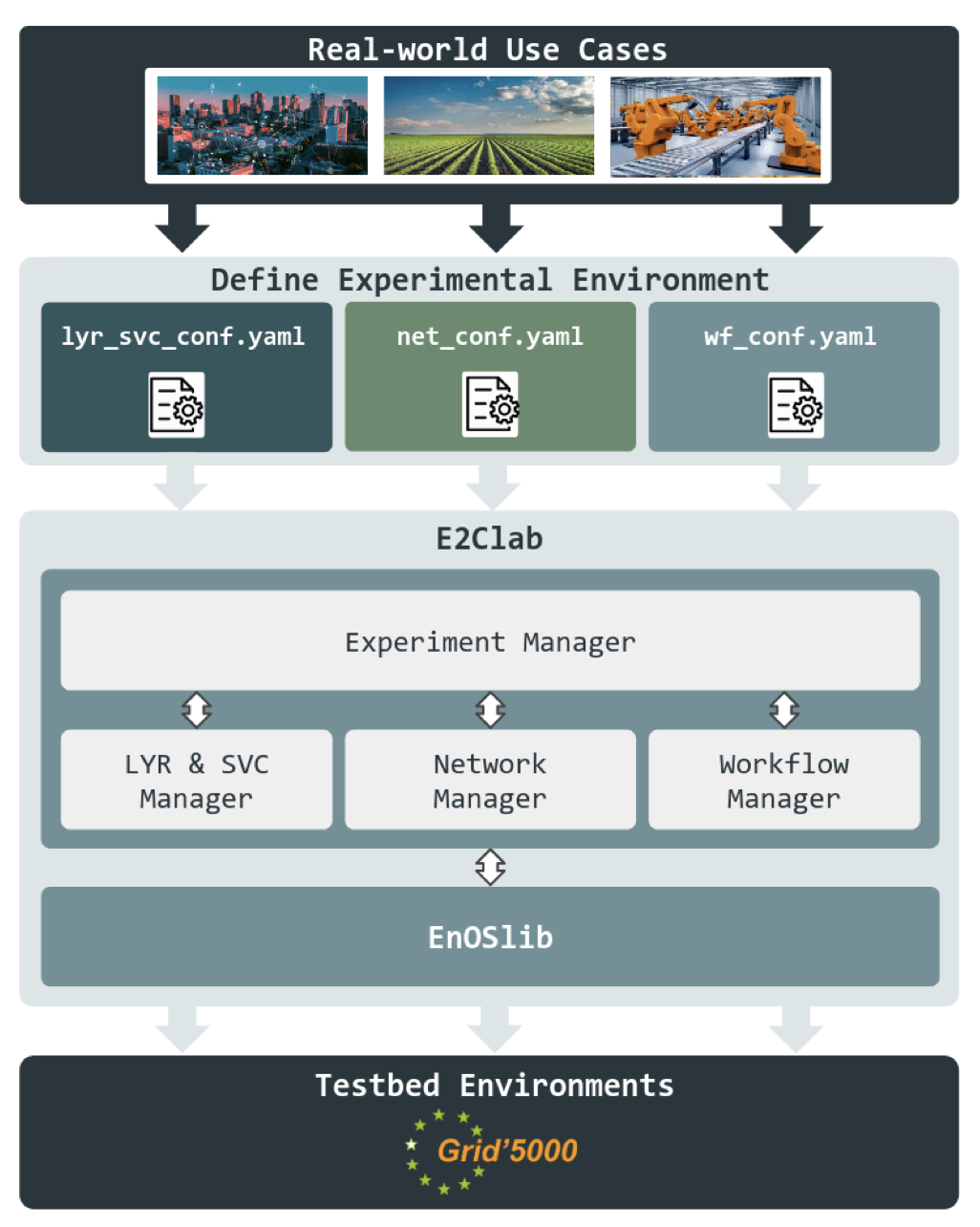
The E2Clab framework
Results: To address this goal, Daniel Rosendo (KerData) leveraged the analytical models studied by José Canepa (IPN) (see Task 1.2 – Activity in 2019) for hybrid deployments in order to propose a rigorous methodology for designing experiments with real-world workloads on the Computing Continuum spanning from the Edge through the Fog to the Cloud. E2Clab is a novel framework that implements this methodology and allows researchers to deploy their use cases on real-world large-scale testbeds, e.g., Grid’5000. To the best of our knowledge, E2Clab is the first platform to support the complete analysis cycle of an application on the Computing Continuum: (i) the configuration of the experiment environment, libraries and frameworks; (ii) the mapping between application parts and machines on the Edge, Fog and Cloud; (iii) the deployment of the application, and (iv) automated execution.
E2Clab was developed with usability in mind: we propose a structure for configuration files (as shown in the Figure). Those files allow experimenters to write their requirements in a descriptive manner. They are easy to comprehend, to use and to adapt to any scenario, reducing the effort of configuring the whole experimental environment. This allows E2Clab to support any deployment of analytics frameworks either Edge-based, Cloud-based, or hybrid Edge/Cloud.
People: Daniel Rosendo, Alexandru Costan, Gabriel Antoniu, José Canepa
Status: Completed
Activity in 2019
Sub-goal 1: To support such analytics we advocate for unified data processing on converged, extreme-scale distributed environments. We are targeting a novel data processing architecture able to relevantly leverage and combine stream processing and batch processing in situ and in transit.
Sub-goal 2: Leveraging on the previous goal, we aim to provide a set of design principles and to identify relevant several software libraries and components based on which such an architecture can be implemented as a demonstrator.
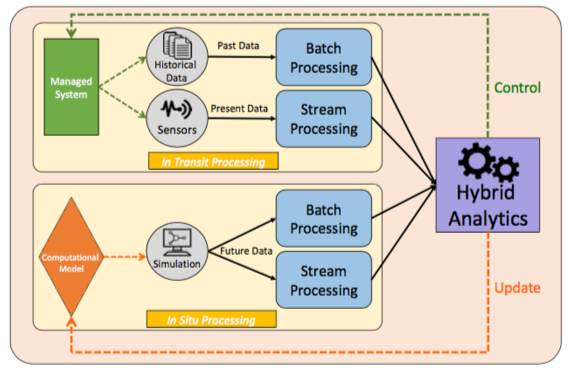
The Sigma Architecture
Results: The first sub-goal lead to the design of the Sigma architecture for data processing, leveraging data-driven analytics and simulations-driven analytics. It combines batch-based and stream-based Big Data processing techniques (i.e., the Lambda architecture) with in situ/in transit data processing techniques inspired by the HPC. This allows to collect, manage and process extreme volumes of past, real-time and simulated data. The architecture relies on two layers: (1) the data-driven layer leverages the unified Lambda architecture to update the simulation model dynamically using the past and real-time data through a continuous learning loop; (2) the computation-driven layer uses in situ and in transit processing to proactively control in real-time the targeted systems. The concept of the Sigma architecture was published as a white paper at the BDEC2 workshop 2019.
The second sub-goal was achieved by investigating the potential candidate libraries able to provide a reference implementation of the Sigma architecture. Our approach consists in jointly leveraging two existing software components: the Damaris middleware for scalable in situ/in transit processing and the KerA unified system for ingestion and storage of data for scalable stream processing. Damaris has already been integrated with HPC storage systems (e.g., HDF5) to enable scalable collective writing of data generated by simulations running on tens of thousands of cores (e.g., at the end of each iteration). Such data can further be analyzed (typically through offline analysis). We developed for Damaris a new real-time storage backend based on KerA: leveraging Damaris dedicated cores and shared memory components, we are able to asynchronously write in real-time the data output of a simulation (that corresponds to multiple iterations) as a series of events, logically aggregated by a stream, with metadata describing the stream’s sub-partitions for each iteration. This is an important step towards a complete data processing and analytics workflow: by leveraging real-time streaming analytics (e.g., Apache Flink) efficiently coupled with KerA through shared memory, scientists can further apply machine learning techniques in real time, in parallel with the running simulation. This joint architecture is now at the core of a start-up creation within the KerData team: ZettaFlow, providing a new generic IoT data storage and analysis platform.
People: Ovidiu Marcu, Alexandru Costan, Gabriel Antoniu, Rolando Menchaca-Mendez
Status: Completed
Task 1.2 Analytical Models for Performance Evaluation of Stream Processing
In recent years we have witnessed an exponential growth on the number of devices connected to internet, from personal computers and smartphones to surveillance cameras, household appliances, autonomous vehicles, traffic lights and specially, many different kinds of sensors. All of these devices are constantly producing useful, but massive amounts of data, which are currently being processed by means of Big Data solutions in the Clouds. However, as the number of devices (and in consequence, the size of data produced) keeps growing, the current solutions might not be sufficient to handle such huge quantities of data, or might incur on prohibitive monetary or energetic costs, or in large response times that degrade the user experience or even cause dangerous situations (as in real-time applications that require to take critical decisions i.e. self-driving cars). Edge computing has been proposed as an alternative solution, which aims to process data near to where it is generated, and while it may seem to be the right alternative, it poses a series of challenges which need to be addressed. One of these challenges is to identify the situations and scenarios in which Edge processing is suitable to be applied.
Activity in 2020
Sub-goal 2: Fine-tuning and optimising the mapping algorithm proposed in Sub-goal 1 (2019) with the goal to incorporate Dynamic Programming‘s main principle into the internal engine of Genetic Algorithms, a popular technique used for numerical optimisation, but seen as a poor choice when it comes to combinatorial optimisation.
Sub-goal 3: Validate the algorithm with real-life use-cases at large scale.
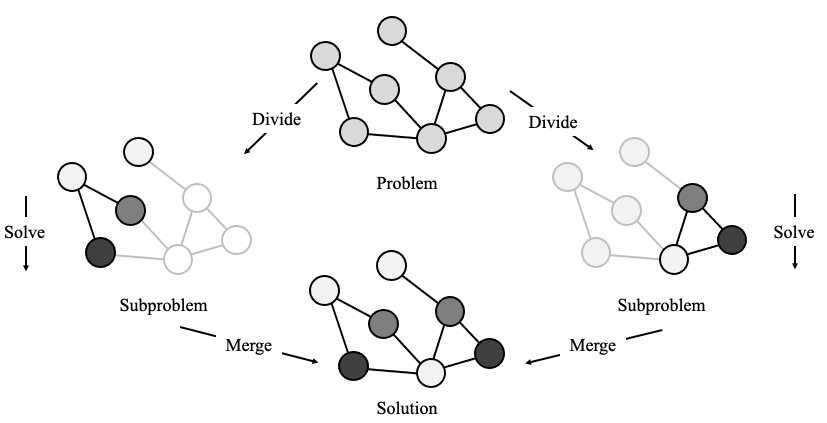
Using Dynamic Programming and Genetic Algorithms to solve complex Edge/Cloud scheduling.
Results: The critical aspect of DP is to divide the problem into smaller sub-problems as independently as possible that can be solved with more ease than the original one and use these sub-solutions to solve the complete problem. With this principle in mind, we designed an algorithm to solve the Graph Coloring Problem, a widespread combinatorial optimization problem that consists of given a graph, assign each of its vertices a label (color) so that no adjacent vertices share the same label. Our proposal uses random, efficient algorithms to partition the graph into smaller sub-graphs, color them using a classical genetic algorithm, and join together to solve the complete graph. Experimental tests on benchmark graphs show promising results (a paper is currently underway to showcase these initial results).
However, we are now interested in test its performance in more massive graphs derived from real-life scenarios (Sub-goal 3). For example, a case study is a network of thousands of servers used to distribute content on the Internet. They require installing or updating their software regularly, but the update cannot be deployed on every server simultaneously because servers might require to be taken down. Also, the update should not be done one at a time because it will take much time. There are sets of servers that cannot be taken down together because they have certain critical functions. This scenario is a typical scheduling application of a graph coloring problem. Another scenario is the radiofrequency assignment: when a cell phone call is made, the phone emits an electronic signal. This signal must be sent at a frequency that does not interfere with calls being placed by other nearby users; otherwise, there will be a degradation of the signal quality or, in the worst case, a “dropped call.” To model this scenario, we are given a set of transmitters that are to be assigned one of an available collection of equally spaced frequencies, which are numbered from 0 to n. These frequencies are thought of like colors, and a vertex of a graph represents each user. Two vertices are joined by an edge when the transmitters they represent must get different frequencies. So, finding a good coloring for this graph effectively finds an assignment for the underlying problem. Cell phones are the most common scenario; however, the radio frequency assignment has many applications such as radio, television, GPS, maritime, space, military and police communications, microwave transmissions, radio astronomy, and radar, to mention but a few.
People: José Canepa, Alexandru Costan, Rolando Menchaca, Ricardo Menchaca
Status: Completed
Activity in 2019
Sub-goal 1: Determine which parts of the application should be executed on the Edge (if any) and which parts should remain on the Cloud.
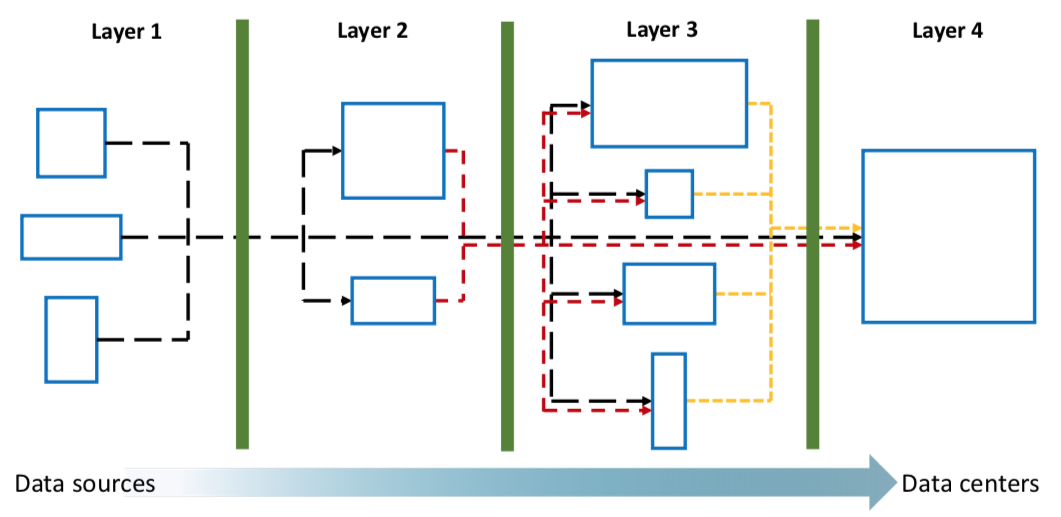
Mapping the application graph on the network graph
Results: To address this goal, José Canepa did a 3 month internship at Inria, under the supervision of Pedro Silva and Alexandru Costan. We have modelled the application using a graph consisting of tasks as nodes and data dependencies between them as edges. The problem comes down to deploying the application graph onto the network graph, that is, operators need to be put on machines, and finding the optimal cut in the graph between the Edge and Cloud resources (i.e., nodes in the network graph). We have designed an algorithm that finds the optimal execution plan, with a rich cost model that lets users to optimize whichever goal they might be interested in, such as monetary costs, energetic consumption or network traffic, to name a few. In order to validate the cost model and the effectiveness of the algorithm, a series of experiments were designed using two real-life stream processing applications: a closed-circuit television surveillance system, and an earthquake early warning system. Two network infrastructures were designed to run the applications: the first one being a state-of-art infrastructure where all processing is done on the Cloud to serve as benchmark; and the second one being an infrastructure produced by the algorithm. Both scenarios were executed on the Grid’5000. Several experiments are currently underway, the results will be published in a journal paper (current target: a Special Issue of Future Generation of Computer Systems). The trade-offs of executing Cloud/Edge workloads with this model were published at the IEEE Big Data 2019 conference.
People: José Canepa, Pedro Silva, Alexandru Costan, Rolando Menchaca, Ricardo Menchaca
Status: Completed
Task 1.3 Benchmarking Edge/Cloud Processing Frameworks
With the spectacular growth of the Internet of Things, Edge processing emerged as a relevant means to offload data processing and analytics from centralized Clouds to the devices that serve as data sources (often provided with some processing capabilities). While a large plethora of frameworks for Edge processing were recently proposed, the distributed systems community has no clear means today to discriminate between them. Some preliminary surveys exist, focusing on a feature-based comparison. We claim that a step further is needed, to enable a performance-based comparison. To this purpose, the definition of a benchmark is a necessity.
Activity in 2020
Sub-goal 2: Executing benchmarks in complex, largely-distributed environments breaks down to reconciling many, typically contradicting application requirements and constraints with low-level infrastructure design choices. One important challenge is to accurately reproduce relevant behaviors of a given application workflow and representative settings of the physical infrastructure underlying this complex Edge to Cloud Continuum.
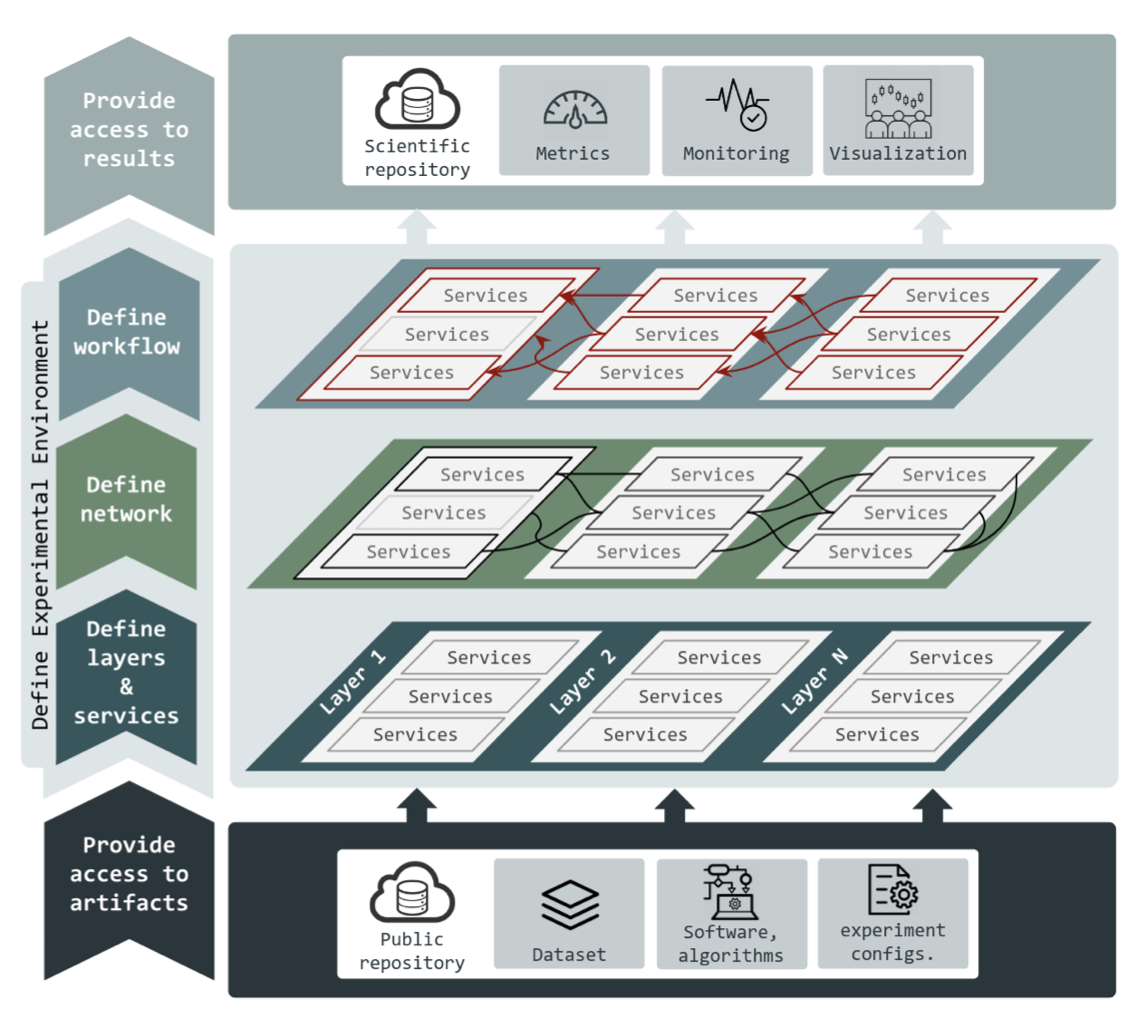
The layers and services abstraction in E2Clab
Results: To address this goal, the KerData team leveraged the E2Clab framework to enable a holistic understanding of performance in such environments. That is, finding a rigorous approach to answering questions like: how to identify infrastructure bottlenecks? which system parameters and infrastructure configurations impact on performance and how? A key challenge in this context is to be able to reproduce in a representative way the application behavior in a controlled environment, for extensive experiments in a large-enough spectrum of potential configurations of the underlying hybrid Edge-Fog-Cloud infrastructure. In particular, this means rigorously mapping the scenario characteristics to the experimental environment, identifying and controlling the relevant configuration parameters of applications and system components, defining the relevant performance metrics. The above process is non-trivial due to the multiple combination possibilities of heterogeneous hardware and software resources, system components for data processing, data analytics or AI model training. Furthermore, in order to allow other researchers to leverage the experimental results and advance knowledge in different domains, the testbed needs to enable three R’s of research quality: Repeatability, Replicability, and Reproducibility (3R’s). This translates to establishing a well-defined experimentation methodology and providing transparent ac- cess to the experiment artifacts and experiment results.
This was achieved by enhancing E2Clab with two abstractions:
• Services represent any system that provides a specific functionality or action in the scenario workflow (e.g., Edge producers, gateways or processing frameworks)
• Layers define the hierarchy between services and group them with different granularities. They can also be used to reflect the geographical distribution of the compute resources. In the context of the Computing Continuum, layers refer to Edge, Fog, and Cloud, for instance.
This layer and service abstraction targets experiments scalability and variation, since it allows to easily resize the number of layers and to analyze different scenario deployments such as single-layered (e.g., Cloud-only) or multi-layered (e.g., Edge + Cloud). Essentially, using only three configuration files the experimenter describes the workflow, the layers and services that compose the scenario and the network specification. The framework abstracts from the users the complexity of the mappings between layers and services with the actual machines in the environment.
Leveraging the analytical models for hybrid processing developed by José Canepa (Task 1.2), E2Clab was used to analyze the performance of a Smart Surveillance application in order to find a representative setup in a Computing Continuum environment. E2Clab allowed to understand the impact on performance of Cloud- centric and Hybrid (Fog+Cloud) processing and to analyze the resource consumption of gateways, data ingestion (Kafka) clusters and processing (Flink) clusters. These results were published at the IEEE Cluster 2020 conference.
People: Daniel Rosendo, Alexandru Costan, Alexandru Costan, Pedro Silva, José Canepa
Status: Completed
Activity in 2019
Sub-goal 1: Design a preliminary methodology for comparing Edge processing frameworks through benchmarking.
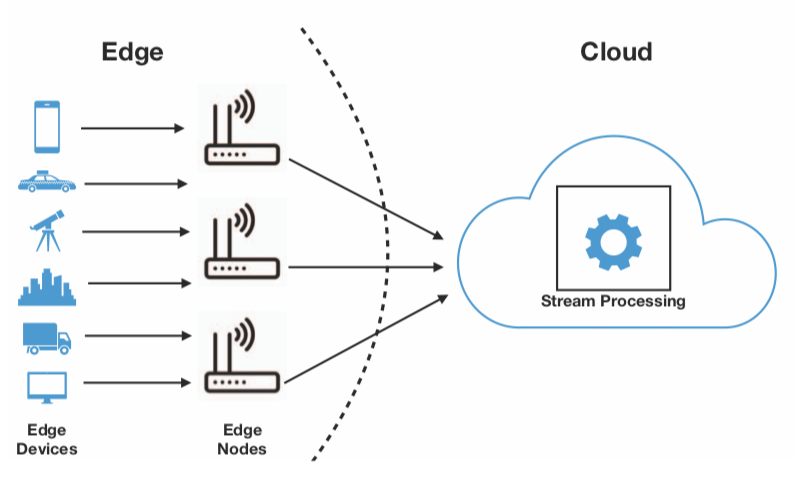
Edge computing infrastructure.
Results: During this period, Pedro Silva focused on analyzing the existing Edge processing frameworks and preliminary benchmarking efforts. We proposed an initial version of a benchmarking methodology for Edge processing and analyzed the main challenges posed by its implementation. The benchmark methodology in presented in seven dimensions: (i) benchmark objectives, (ii) Edge processing frameworks, (iii) infrastructure, (iv) scenario applications and input data, (v) experiment parameters, (vi) evaluation metrics, and (vii) benchmark workflow. Once implemented, this benchmark would make a step beyond existing feature-based comparisons available in the related work, typically based on their documentation: it will serve to compare a large number of private and open-source Edge processing frameworks in a performance-oriented fashion. Current collaboration with José Canepa and Rolando Menchaca set the pathway towards the implementation of the benchmarks, enriched with the data models presented in the previous section. The vision of the benchmark was initially published at the PAISE workshop joint with IPDPS 2019.
People: Pedro Silva, Alexandru Costan, Gabriel Antoniu, José Canepa
Status: Completed
Task 1.4 Modelling Smart Cities Applications
Smart Cities are the main applicative use-case of this Associated Team. We therefore need to take into account both the characteristics of the data and the process/storage requirements of these particular applications, since they will drive the design choices of the systems supporting them. The objective is to devise clear models of the data handled by the applications in this context. The relation between the data characteristics and the processing requirements does not have to follow an one-to-one relation. In some cases, some particular types of data might need one or more types of processing, depending on the use case. For example, small and fast data coming from sensors do not always have to be processed in real-time, but they could also be processed in a batch manner at a later stage.
Activity in 2020
Sub-goal 3: Modelling data flow from Vehicular Networks through phase-type distributions and Artificial Neural Networks to obtain a robust system to reserve and allocate resources.
Sub-goal 4: Distribute the data flow’s prediction in multiple antennas to estimate load work in a specific point based on the demand for resources in the neighbourhood.

Multiple antennas architecture
Results: The SUMO simulator generates vehicles’ traffic flow to feed the Neural Network and the Phase-type model. The first approach was for a single antenna (Sub-goal 1 in 2019), where the mathematical model bounded the real traffic in the up and the Neural Network learns the actual traffic history. This single antenna model only considers its self data. Multiple antennas’ model considers the data from neighbor antennas to feed the Neural Network to predict the vehicles’ flow.
The current precision of Neural Networks is beneficial for the prediction; however, the complexity of such a model increases such that updates or computing may demand Cloud capabilities. We leveraged Grid’5000 to compare performance between Cloud capabilities and Edge capabilities and estimate multiple antennas’ data flow. The resulting flow prediction models are currently in submission to a journal in the field of Vehicular/Edge Networks. This joint Inria/IPN article is the beginning of a future papers’ collection for Edge/Cloud computing architecture in the area of Vehicular Networks.
People: Edgar Romo, Alexandru Costan, Mario Rivero, Gabriel Antoniu, Ricardo Menchaca-Mendez
Status: Completed
Activity in 2019
Sub-goal 1: Model the stream rates of data from sets of sensors in Smart Cities, specifically, from vehicles inside a closed coverage area.
Sub-goal 2: Use the previous model for accurate predictions of the resources needed to process the sensors data at the Edge and in the Cloud, as an input for auto-scaling modules.
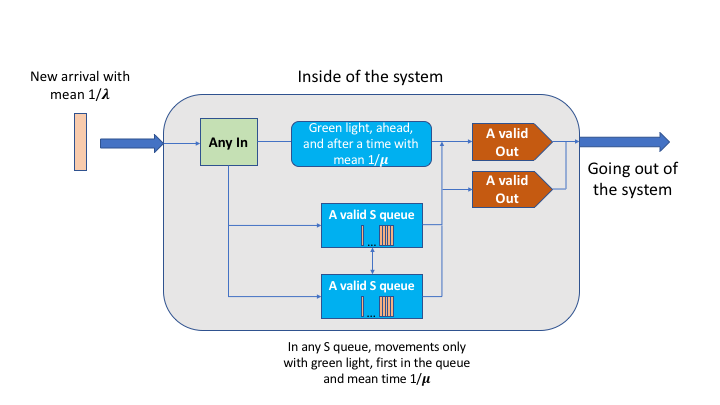
Model of the time spent by a vehicular sensor inside a designated area
Results: These two goals were addressed during the 3 month internship of Edgar Romo Montiel at Inria, under the supervision of Alexandru Costan and Gabriel Antoniu. Specifically, the first sub-goal lead to the design of a mathematical model to predict the time that a mobile sensor resides inside a geographical designated area. To bound the problem, users are vehicles in a V2I VANET connected to some specific applications in the Cloud such as traffic reports, navigation apps, multimedia downloading etc. The proposed model is based on Coxian distributions to estimate the time a vehicle demands Cloud services. The main challenge is to adjust its parameters and this was achieved by validating the model agains real-life data traces from the city of Luxembourg, through extensive experiments on the Grid’5000.
As a second sub-goal, the objective is to use these models to estimate the resources needed in the Cloud (or at the Edge) in order to process the whole stream of data. We designed an Auto-Scaling module able to adapt the resources based on the detected load. Using the Grid’5000, we evaluate the different choices for placing the prediction module: (i) at the Edge, close to data with less accuracy but faster results, or (ii) in the Cloud, with higher accuracy due to the global data, but higher latency as well). The results will be published at a workshop joint with an A class conference from the Cloud/Big Data domain.
People: Edgar Romo, Alexandru Costan, Mario Rivero, Gabriel Antoniu, Ricardo Menchaca-Mendez
Status: Completed
Task 2.1 Modelling the Machine Learning Constraints of Smart Cities Applications
Building on the data models discovered through Task 1.4, we zoom on the specificities of the ML-based applications (leveraging IPN expertise on ML) and capture some data access patterns and eventually detect some regularities in large datasets, that could be further exploited in Task 2.2
Activity in 2021
Model of vehicular circulation in the city environment used by ML applications.
Results: We use a macromobility vehicular model that considers road layout, number of lanes, and speed limits which models the general behavior in a vehicular environment and allows us to focus on developing a mathematical framework for the Smart City application as opposed to micromobility models that are much more time-consuming and require heavy processing tasks to account for driver behavior and obstacles in the roads. Accordingly, we aim at providing initial and general results in the P2P vehicular research area and micromobility models, which can be used in future research works to consider more specific variables and scenarios.
To this end, we consider two environments: urban (based on the Manhattan model) and highway (straight segment). Additionally, we study the system performance in three traffic conditions, namely, high, medium, and low.
People: Daniel Rosendo, Alexandru Costan, Edgar Romo, Mario Rivero, Ricardo Menchaca
Status: Completed
Task 2.2 Machine Learning Based Analytics on top of Unified Edge/Cloud Stream Processing
We leverage the Sigma architecture and E2Clab to enable the seamless execution of machine learning algorithms for Smart Cities, across Edge and Cloud platforms. To this end, we are considering integration with open-source platforms for the end-to-end machine learning lifecycle atop platforms like Spark and Flink.
Activity in 2021
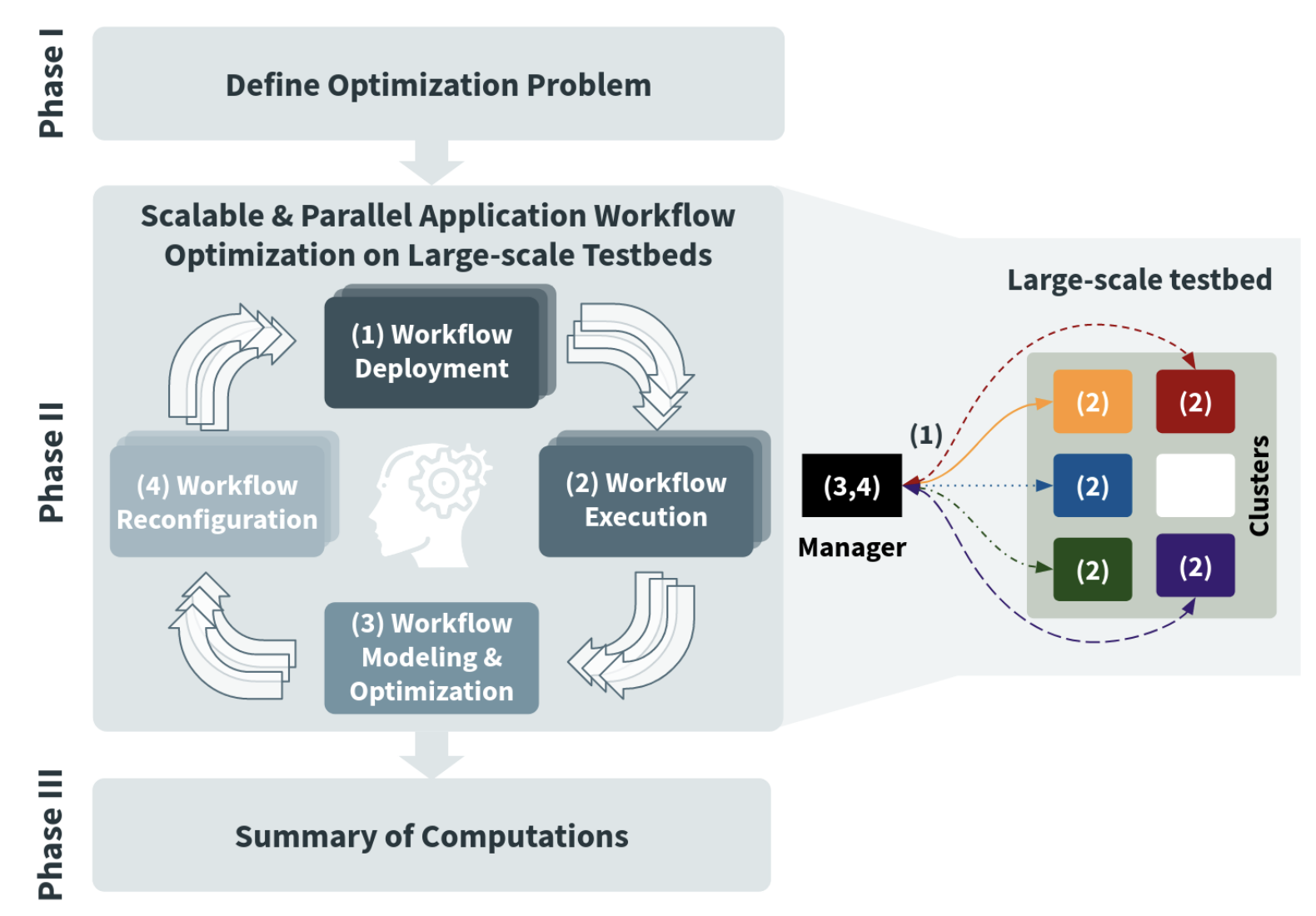
Optimisation methodology based on E2Clab for ML analytics in Smart Cities.
Results: We propose a methodology to support the optimization of real-life Smart Cities applications on the Edge-to-Cloud Continuum. This methodology is useful to help decide on application configurations to optimize relevant metrics (e.g., performance, resource usage, energy consumption, etc.) by means of computationally tractable optimization techniques. It eases the configuration of the system components distributed on Edge, Fog, and Cloud infrastructures as well as the decision where to execute the application workflow components to minimize communication costs and end-to-end latency
It consists of three main phases illustrated in the next Figure. Phase I: Initialization, depicted at the top of Figure, consists in defining the optimization problem. Phase II: Evaluation aims at defining the mathematical methods and optimization techniques used in the optimization cycle (presented in the middle of Figure) to explore the search space. Phase III: Finalization, for reproducibility purposes, illustrated at the bottom of Figure provides a summary of computations.
People: José Canepa, Daniel, Rosendo, Alexandru Costan, Luc Bougé, Jésus Favela, Iclia Villordo
Status: Completed
Task 2.3 Computation Work Offloading in Vehicular Environments
Using the workload and framework profiles gained through Task 1.2 we focus on the case of vehicles connected to perform different processes related to smart cities. Such applications require either the timely transmission of results (i.e., data processing in autonomous vehicles) or more accurate results with higher latencies (i.e., determine optimal routes). In this scenario, vehicles would perform a certain amount of processing in the Fog, that can be readily available for nodes in the vicinity while other processes have to be transmitted to the Cloud, where more computational power is available, but latency is higher. The problem of selecting such partition of processes to be performed in the Fog or in the Cloud is not straightforward since it highly depends on the number of vehicles in the region, traffic conditions, number and type of processes, workload in the Fog and in the Cloud among others. We develop a mathematical framework that allows to evaluate the performance of the system in terms of energy, delay, and successful packet transmission in different environments and system conditions.
Activity in 2022
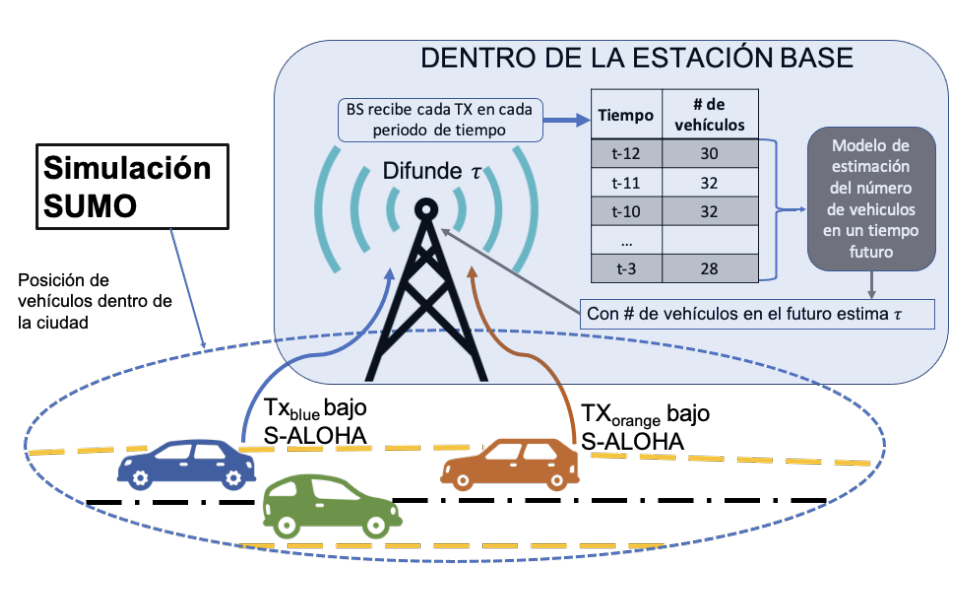
Data processing in the Fog (i.e., antennas)
Results: We developed the idea of using vehicles in a Smart City environment to collect data and send it to a collection center to decide to process it either in the Fog or in the Cloud. We are considering that nodes (vehicles) obtain the data from a certain part of the city and then transmit it or disseminate this information to neighbour nodes (using a P2P network) or directly to a cellular base station or Road Side Unit.
From this stage, the data is ingested in Big Data framework like Spark or Flink using E2Clab, to process it in the Fog or Cloud depending on the data priority, accepted latency, traffic conditions at the different servers, etc. Also, we worked on obtaining data in an efficient manner in other scenarios different from vehicles (i.e., Wireless Sensor Networks). These results were published in several journal and conference papers, listed here.
People: Luis Gallego, Ricardo Menchaca, Mario Rivero, Daniel Rosendo, Alexandru Costan
Status: Completed