



by Mostafa Sadeghi and Xavier Alameda-Pineda
Presented at IEEE ICASSP 2021
[arXiv]
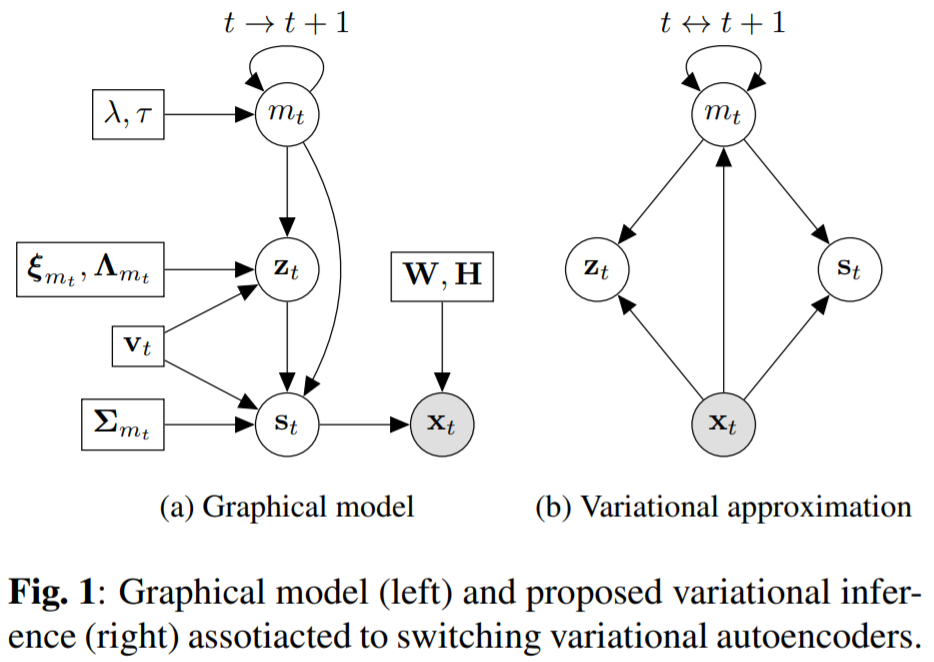
Switching variational autoencoders are a dynamic mixture of non-linear generative models, implemented via deep neural networks, and optimised following the same rationale as VAEs.
Abstract: Recently, audio-visual speech enhancement has been tackled in the unsupervised settings based on variational auto-encoders (VAEs), where during training only clean data is used to train a generative model for speech, which at test time is combined with a noise model, e.g. nonnegative matrix factorization (NMF), whose parameters are learned without supervision. Consequently, the proposed model is agnostic to the noise type. When visual data is clean, audio-visual VAE-based architectures usually outperform the audio-only counterpart. The opposite happens when the visual data is corrupted by clutter, e.g. the speaker not facing the camera. In this paper, we propose to find the optimal combination of these two architectures through time. More precisely, we introduce the use of a latent sequential variable with Markovian dependencies to switch between different VAE architectures through time in an unsupervised manner: leading to switching variational auto-encoder (SwVAE). We propose a variational factorization to approximate the computationally intractable posterior distribution. We also derive the corresponding variational expectation-maximization algorithm to estimate the parameters of the model and enhance the speech signal. Our experiments exhibit the performance of SwVAE