by Xiaofei Li and Radu Horaud
INTERSPEECH 2020
[arXiv] [speech enhancement examples]
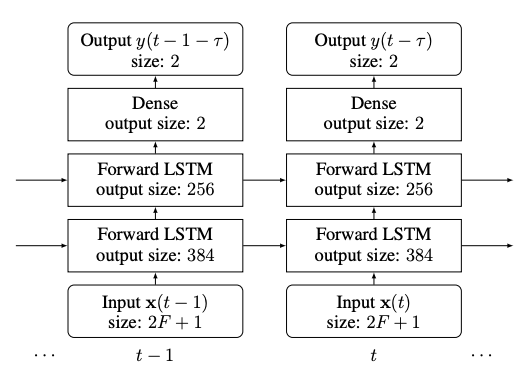
Abstract. This paper proposes a delayed subband LSTM network for online monaural (single-channel) speech enhancement. The proposed method is developed in the short time Fourier transform (STFT) domain. Online processing requires frame-by-frame signal reception and processing. A paramount feature of the proposed method is that the same LSTM is used across frequencies, which drastically reduces the number of network parameters, the amount of training data and the computational burden. Training is performed in a subband manner: the input consists of one frequency, together with a few context frequencies. The network learns a speech-to-noise discriminative function relying on the signal stationarity and on the local spectral pattern, based on which it predicts a clean-speech mask at each frequency. To exploit future information, i.e. look-ahead, we propose an output-delayed subband architecture, which allows the unidirectional forward network to process a few future frames in addition to the current frame. We leverage the proposed method to participate to the DNS real-time speech enhancement challenge. Experiments with the DNS dataset show that the proposed method achieves better performance-measuring scores than the DNS baseline method, which learns the full-band spectra using a gated recurrent unit network.