
Salto
Contacts: Erven Rohou, François Bodin, André Seznec, Zbigniew Chamski
General Presentation
Salto is a retargetable framework for developing the whole spectrum of tools that manipulates assembly-language. The objective of such a system is to provide the user with a single environment that will allow him to implement the tools that are needed for performance tuning on low-level codes; this set of tools includes assembly-code schedulers (such as software pipelining), as well as profiling and tracing tools that provide the user with information on where to focus optimizations and how efficient they can be, therefore allowing tradeoff choices. Such a system is intended to address general computing as well as embedded systems for which optimizations are more critical and aggressive, but time-consuming techniques are more tolerable.
Salto is fully and easily retargetable with respect to the hardware details and the instruction set architecture. Any relevant piece of hardware has to be described in a machine description file. Then resource usage may be represented for any instruction therefore enabling data dependences computation.
Salto was partially founded by the ESPRIT LTR project OCEANS.
Salto is registered at APP (Agence pour la Protection des Programmes) under number IDDN.FR.001.070004.00.R.C.1998.000.10600.
Overview of Salto
Contents
For a more accurate description, you can refer to the functional specification (pdf).
Introduction
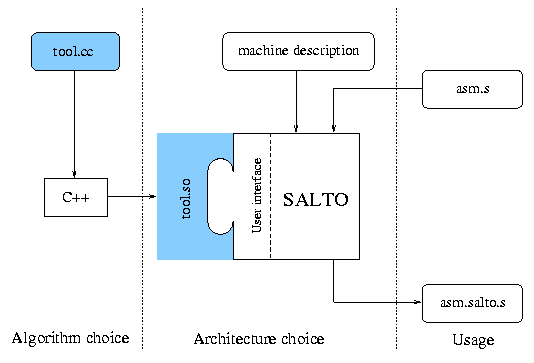
A Salto application is composed of three parts: a kernel, a machine description file and an optimization or instrumentation algorithm. Figure 1 illustrates the organization of these three components.
-
The kernel performs common house-keeping tasks that the user doesn’t want to worry about. The parsing of the assembly-code and of the machine -description file are done automatically, as are the construction of the internal representation. This internal representation is available via the user interface.
-
The machine description file contains the hardware configuration and the complete description of the instruction-set with reservation-tables.
-
The optimization or instrumentation algorithm is supplied by the user. Once the system has read the machine-description file and the assembly- code, an internal representation is built and control is given to the user through the call to a predefined function.
Data Structures
The data structures used in Salto are divided into two groups, depending on their role. The first group represents the control flow of the program, the second group describes resource usage and data dependencies between instructions.
Control Flow Structures
Additionally, the control flow graph is built for each procedure. The vertices are the basic-blocks and the edges denote the execution order of the basic-blocks. Edges are labelled to indicate if they correspond to the taken or not-taken branch.
Hardware Resources and Data Dependences
Each instruction is described by a reservation-table, which indicates the list of resources it needs and the mode and cycle a resource is accessed. This information is used when determining the type of dependence between two instructions: RAW (read after write), WAW (write after write), WAR (write after read).
Machine Description
Salto is designed to be a retargetable tool. Thus, the target machine must be described in a flexible way, permitting an accurate description while retaining the ability to easily modify parameters. This is achieved with a Lisp-like language based on the reservation-table formalism. The description file is parsed by Salto and an internal representation is built using RTL (Register Transfer Language). The machine description contains:
-
the syntax of the assembly-language used, that is, how does a comment start, how many registers are there, and what are their names;
-
all the resources needed for the computation of data dependencies;
-
the list of the instructions recognized by the assembler with the applicable formats and the associated reservation-tables;
-
semantical information to warn Salto about special features implemented in the processor like bypass-mechanism or delayed branch.
User Interface
The object-oriented user interface provides a flexible way to deal with the internal data structures. Features of Salto include:
-
access to the code at three different levels : procedure, basic-block or instruction;
-
modification of the code: insertion, deletion;
-
unparsing;
-
access to the reservation-tables;
-
computation of dependencies and delays between instructions caused by pipeline stalls;
-
addition of attributes: attributes are a flexible way to put any kind of information on a particular basic-block or instruction.
The easiest way to understand how the user interface is used, is to have a look at small examples of tools written with Salto.