Contact
Email: leo.maczyta@inria.fr
Address: INRIA Rennes – Bretagne Atlantique,
Campus Universitaire de Beaulieu,
35042 Rennes cedex – France
Brief vitae
Léo Maczyta obtained a Masters degree in Robotics and embedded systems from ENSTA ParisTech Université Paris-Saclay, France, and a Masters degree in Advanced systems and robotics from University Pierre and Marie Curie, France in 2017. He then conducted his PhD thesis work at Inria Rennes from 2017 to 2020 on the research topic of motion saliency estimation in video sequences.
Research
Journal article
L. Maczyta, P. Bouthemy, O. Le Meur. CNN-based temporal detection of motion saliency in videos. Pattern Recognition Letters, 2019
Conference paper
L. Maczyta, P. Bouthemy, O. Le Meur. Unsupervised motion saliency map estimation based on optical flow inpainting. Proc. IEEE Int. Conf. on Image Processing (ICIP’19), Taipei, 2019
National conference papers
L. Maczyta, P. Bouthemy, O. Le Meur. Estimation non supervisée de cartes de saillance dynamique dans des vidéos. In Reconnaissance des Formes, Image, Apprentissage et Perception (RFIAP’20), 2020
L. Maczyta, P. Bouthemy, O. Le Meur. Détection temporelle de saillance dynamique dans des vidéos par apprentissage profond. In Reconnaissance des Formes, Image, Apprentissage et Perception (RFIAP’18), Marne-la-Vallée, France, 2018
Preprint
L. Maczyta, P. Bouthemy, O. Le Meur. Trajectory saliency detection using consistency-oriented latent codes from a recurrent auto-encoder.
Overview
Motion saliency detection
We consider the problem of frame-based motion saliency detection, that is, estimating which frames of a video contain motion saliency. The method we propose is based on two steps. First, the dominant motion due to the camera is cancelled. For the variant RFS-Motion2D, this is done by subtracting to the optical flow the dominant motion, which is estimated with a parametric model. Then, the classification into the salient or non salient class is achieved with a convolutional neural network, applied to the residual flow.
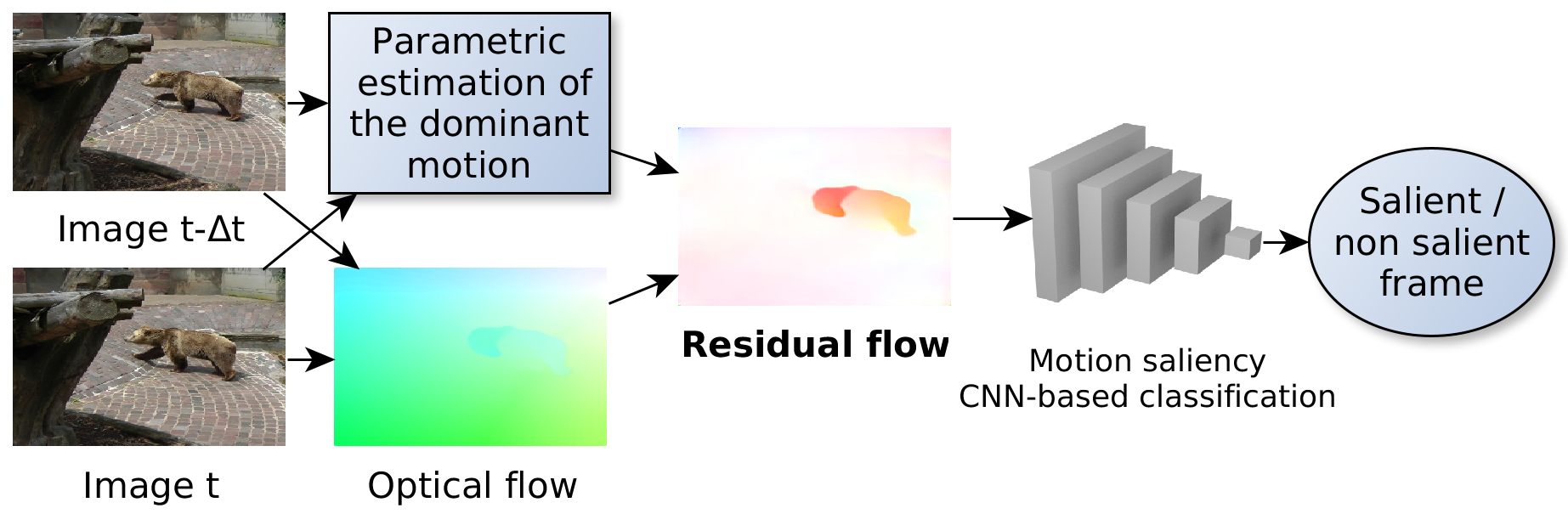
Framework for motion saliency detection.

Architecture of the classification Convolutional Neural Network (CNN) of the motion saliency detection framework.
Results obtained with our method RFS-Motion2D. The colour of the frame border, orange or blue, designates the prediction, respectively dynamic saliency or non saliency. The green (respectively red) square at the bottom right indicates that the prediction is correct (respectively wrong). The first part of the video is constituted of non salient clips, and the second part is constituted of salient clips. The video shows that non saliency is correctly predicted even when the shallow scene assumption is not valid, with for instance walls, trees or pillars in the foreground.
Motion saliency map estimation
The problem of motion saliency map estimation consists in predicting a saliency value for each pixel of video frames. To solve it, we build a method based on optical flow inpainting. In a first step, candidate salient regions are extracted. Then, the optical flow inside these regions is inpainted from the surrounding flow. The idea is that, if the region is salient, the reconstructed flow should be clearly distinct from the flow present originally. On the contrary, if the region is not salient, the reconstructed and original flow should be similar. We then leverage the difference between these two flows (the residual flow) to compute the motion saliency map.

Framework for motion saliency map estimation based on optical flow inpainting.

Motion saliency map estimation results. Top to bottom: video frame, computed residual flow, motion saliency map predicted by our method MSI-ns, and binary ground truth. The three samples on the left come from the DAVIS 2016 dataset. In the fourth sample, a square region has been artificially moved. The fifth sample comes from an infra-red video.
Trajectory saliency
We propose a method to tackle the problem of trajectory saliency estimation. Indeed, trajectories naturally allow to handle saliency which progressively appears over time. We develop a framework whose core is a (nearly) unsupervised recurrent neural network. The role of this network is to represent trajectories with a latent code the following way: similar trajectories should be represented with codes close in the embedding space, and dissimilar trajectories should be represented with distant codes. The training relies on an auto-encoder structure, complemented by a consistency constraint in the loss. This constraint traduces the fact that non salient trajectories are similar, and its role is to make non salient codes closer in the embedding space. Finally, the distance of the trajectory code to a prototype code accounting for normality is the means to detect salient trajectories.
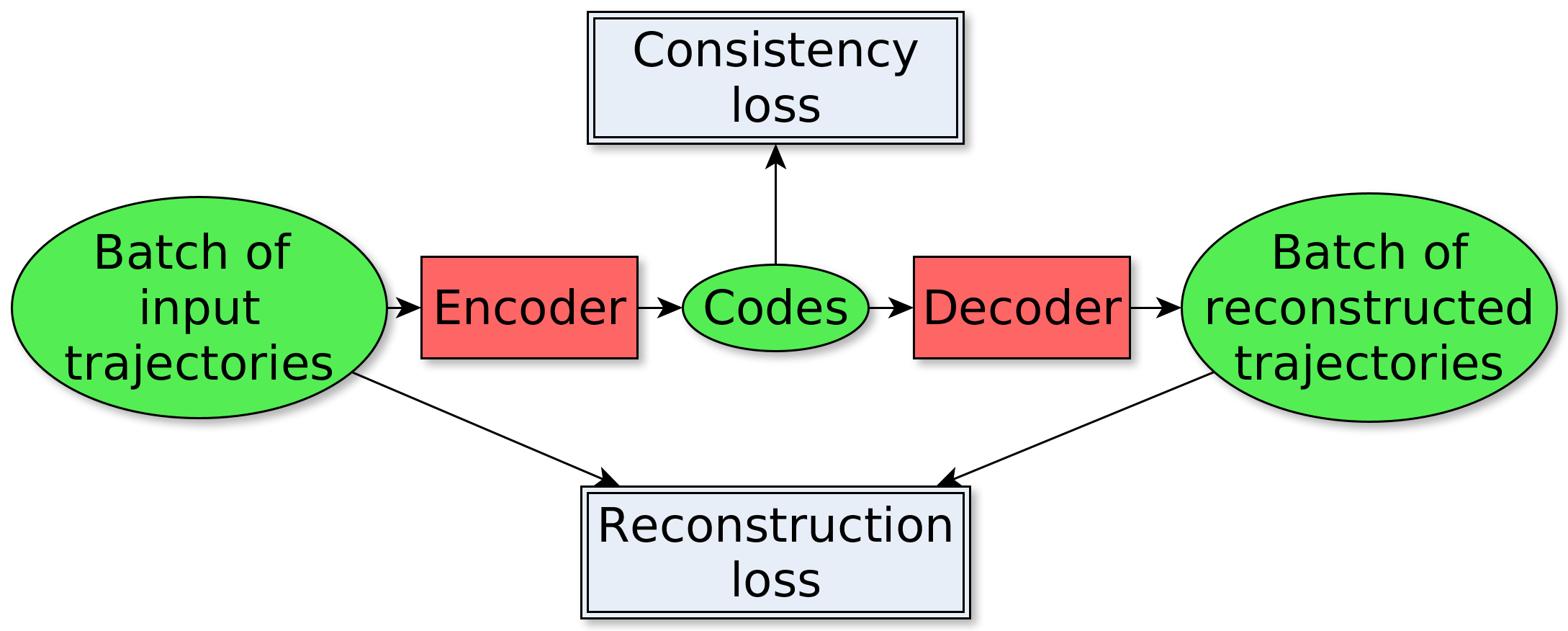
Framework for the estimation of a code to represent trajectories. The backbone of this framework is a trajectory auto-encoder. The other main component is the consistency constraint, which expresses the fact that non salient trajectories are similar, and should then be represented with a similar code.