PLASMA Associate Research Team (Emeraude // CCRMA@Stanford)
Overview
Plasma (Pushing the Limits of Audio Spatialization with eMerging Architectures) is an associate research team gathering the strength of Emeraude and of the Center for Computer Research in Music and Acoustics (CCRMA) at Stanford University.
The two main objectives of Plasma are:
- Exploring various approaches based on embedded systems towards the implementation of modular audio signal processing systems involving a large number of output channels (and hence speakers) in the context of spatial audio.
- Making these systems easily programmable: we want to create an open and accessible system for spatial audio where the number of output channels is not an issue anymore.
Two approaches are being considered in parallel:
- Distributed using cheap simple embedded audio systems (i.e., Teensy, etc.),
- Centralized using an FPGA-based (Field-Programmable Gate Array) solution.
We’re basically looking at improving current spatial audio systems in terms of hardware/computational capabilities rather than DSP algorithms for spatial audio themselves.
Research
During the year of 2023, we focused on implementing different prototypes of spatial audio systems taking both a centralized and a distributed approach using some of the technology developed in the Emeraude team (i.e., the Faust programming language [OR7], SyFaLa [OR8], etc.). Both approaches present pros and cons that we’re trying to analyze and compare. For instance:
| Pros | Cons | |
|---|---|---|
| Centralized | No clock synchronicity issues; robustness; cost: can target multiple audio codec chips at once. | Performances and hence number of channels limited by the FPGA (even though multiple FPGAs could potentially be used in parallel and synchronized) |
| Distributed | Infinitely scalable; based on standard technologies known and trusted by a large number of people in the community. | Potential clock synchronicity issues; robustness (package drops can potentially happen). |
The following section provides an overview of the work that has been done so far as part of PLASMA.
Centralized System for Spatial Audio
FPGAs are highly adapted to spatial audio thanks to (i) their large number of GPIOs (General Purpose Inputs and Outputs) allowing for the interfacing of numerous audio chips (audio codecs) in parallel, (ii) their high level of parallelization. In other words, many audio channels can be processed in parallel on an FPGA and rendered through a bunch of audio chips. Additionally, the i2s TDM (Time Division Multiplexing) protocol allows for multiple channels (8 in general and up to 16 on some high-end codecs) to be transmitted through the same i2s bus (which typically uses only 3 GPIOs). Since clocks can be shared between all audio codecs in the system, every new set of audio channels (8, 16, etc.) implies the use of only one new GPIO. Hence, if using codecs allowing for TDM on 16 channels, designing a system (see Figure below) with 32 audio outputs only requires the use of 4 GPIOs (2 + 1 + 1); 48 channels would be 5 GPIOs (2 + 1 + 1 + 1), etc. Basic FPGA boards such as the Digilent Zybo Z7 provide up to 30 GPIOs whereas higher end FPGA boards such as the Digilent Genesys provide up to 70 GPIOs. This means that theoretically (and disregarding any potential computational limits), implementing a system with a total number of 2176 audio outputs should be possible using a Genesys board.
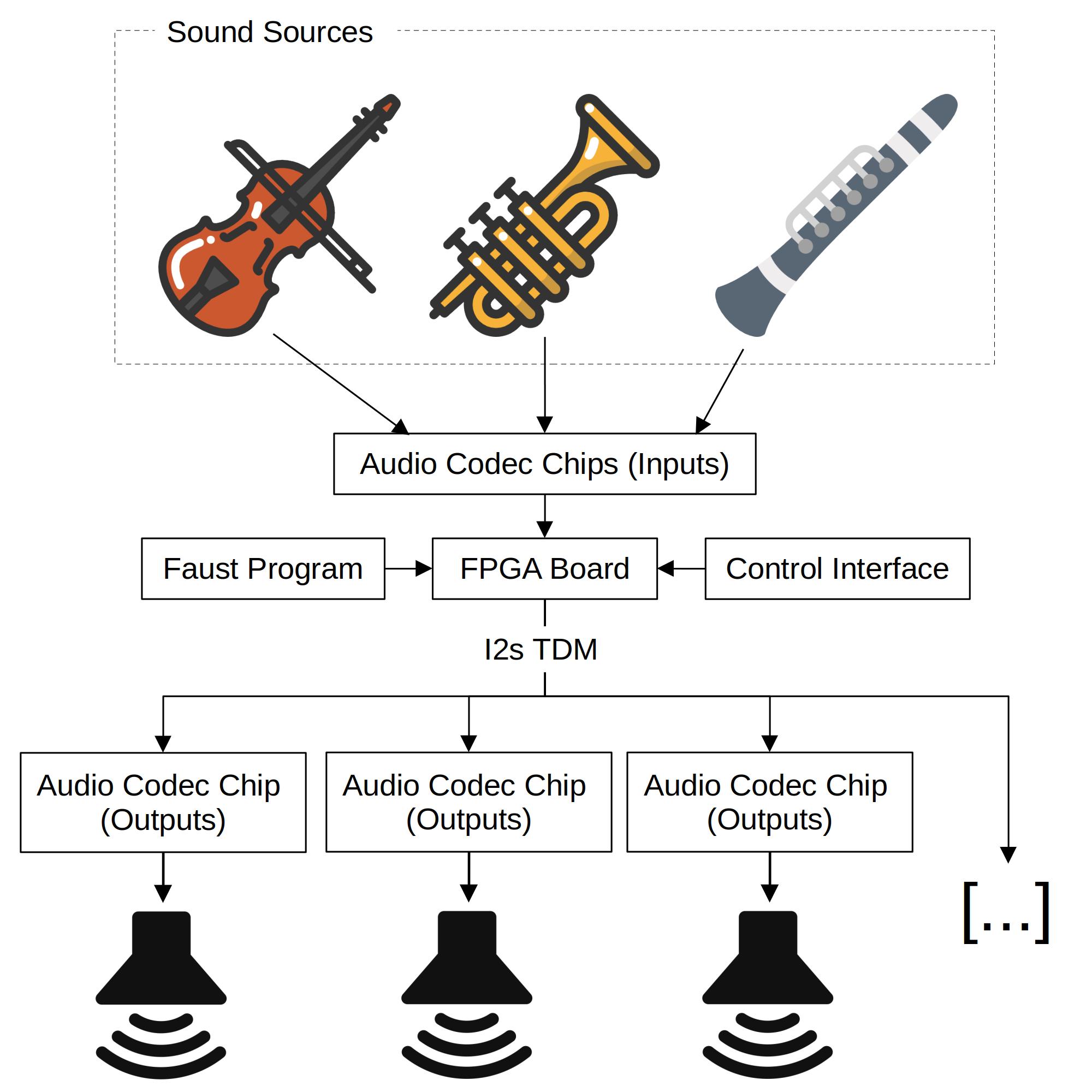 Overview of an FPGA-Based Centralized Spatial Audio System
Overview of an FPGA-Based Centralized Spatial Audio System
As a first step in this direction, we hired an intern (Joseph Bizien) to work on a low-cost Wave Field Synthesis (WFS) [OR2] system based on MAX98357A digital amplifiers which are compatible with TDM up to 8 channels and only cost 5 euros a piece! Joseph made custom speakers (see picture below) with laser cut wood which directly connect to the amplifiers (schematic available on GitHub). We also implemented a specific TDM-compatible version of the SyFaLa toolchain targeting this system and accessible through the --tdm option in the SyFaLa tool.
The current version of the WFS system has 32 speakers and only uses 6 GPIOS (2 + 1 + 1 + 1 +1) of a Zybo Z7-20 board. We successfully ran a standard WFS algorithm implemented in the Faust programming language on this system where 2 sources can be moved in space. Individual sources are sent to the speaker array though analog audio using the built-in audio inputs of the Zybo Z7-20. Their position can be controlled using a web interface accessible through am HTTPD server.
Thanks to the use of the FPGA, the cost of each new channel in the system is very low. Implementing a WFS system with a more traditional architecture would be way more expensive that what we achieved which is very promising! This work led to a publication at the NIME 2023 conference [PU1].
 Prototype of a Low-Cost Wave Field Synthesis System Based on an FPGA and the Syfala Toolchain
Prototype of a Low-Cost Wave Field Synthesis System Based on an FPGA and the Syfala Toolchain
The next step in this direction consists both of (i) further benchmarking the system to test its limits (i.e., possible number of output channels, sources, etc.) and (ii) implementing a more professional (and costly) version compatible with any kind of speaker systems.
(i) Performance wise, we already know that the main bottleneck won’t be computational power but probably the number of memory accesses that can be carried out with a one sample cycle. Again, we do need to run more tests to know what the limits of the system are. We haven’t reach them yet.
(ii) The current low-cost system that we implemented is only compatible with small 3w 4ohm speakers and can’t really be interfaced to more professional speakers. We’re currently in the process of finishing the development of a modular sister board system for the Genesys board providing an arbitrary number of analog inputs and outputs. It will be based on ADAU1787 high end audio codecs which are TDM compatible up to 16 channels. The board will provide balanced inputs and outputs compatible with most amplified speakers on the market. Our goal is to then interface this system with the CCRMA stage which hosts an ambisonics array with more than 60 speakers.
 The CCRMA Stage at Stanford University Featuring a 7th Order Ambisonics Speaker Array
The CCRMA Stage at Stanford University Featuring a 7th Order Ambisonics Speaker Array
(i) and (ii) will be carried out during 2024.
Distributed System for Spatial Audio
Another way to approach audio spatialization systems involving a large number of speakers is by distributing computation over a network of sound processing platforms. Curiously enough, this approach hasn’t been explored much in the past and even though streaming a large number of audio channels over a network is very standard nowadays (i.e., through standards such as Dante, etc.), distributed real-time audio DSP systems are way less common. An intern (Thomas Rushton) was hired to work on developing a distributed systems for spatial audio DSP based on a network of microcontrollers. We chose this type of platform because they are cost-effective, very lightweight, and OS-free. We used PJRC’s Teensys 4.1 as they host a powerful Cortex M7 clocked at 600MHz as well as built-in ethernet support. PJRC also provides an “audio shield” which is just a breakout board for a stereo audio codec (SGTL-5000) compatible with the Teensy 4.1.
A preliminary task was to send audio streams over the Ethernet from a laptop to the Teensy. For that, we decided to use the JackTrip protocol which is open source and used a lot in the audio/music tech community. Implementing a JackTip client on the Teensy was fairly straightforward. We do believe that this also has applications for network audio performances.
Audio DSP is carried out directly on the Teensys which are programmed with the Faust programming language thanks to the faust2teensy [OR9] tool developed by the Emeraude team. A laptop is used to transmit audio streams to the Teensys which are controlled using the Open Sound Control (OSC) standard. OSC messages are multicast/broadcast to save bandwidth. The same audio streams are sent to all the Teensys in the network (all audio processing is carried out on the Teensys, not on the laptop computer). The figure below provides an overview of how this system is working.
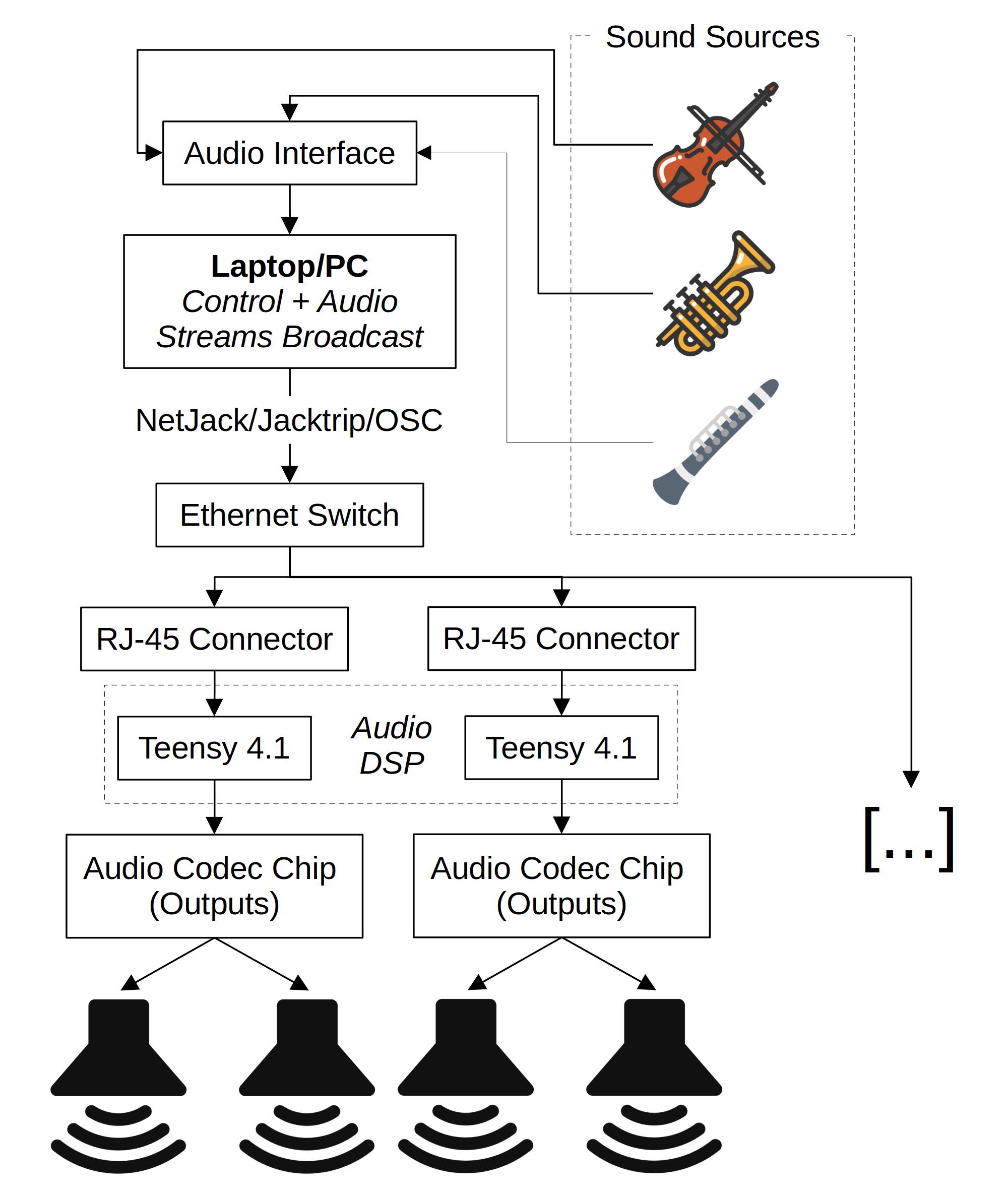 Distributed Spatial Audio System Based on a Network of Microcontrollers
Distributed Spatial Audio System Based on a Network of Microcontrollers
A key point when designing such a system is to make sure that all the Teensys in the network are perfectly synchronized insuring a consistant latency between all the audio outputs in the system. Measurements were carried out to make sure that it’s the case. The figure below shows a bunch of Teensy 4.1 boards equipped with an audio shield and an ethernet port. They’re all connected to and Ethernet switch linking them to a laptop.
 Network of Teensy 4.1 Microcontrollers
Network of Teensy 4.1 Microcontrollers
A prototype WFS system using the same Faust program as the one used for our centralized approach (see Centralized System for Spatial Audio) was implemented. We obtained similar results in both scenarios. The figure below shows a picture of this system.

WFS System Based on a Network of Microcontrollers (Teensy 4.1)
While we now have a working prototype that led a publication [PU2], many tasks remain to be carried out in 2024:
(i) Multicast should be implemented in JackTrip in order to send the same audio stream to all the Teensys without having to duplicate it each time. This should allow us to scale our system almost infinitely which is not the case now since each new speaker in the system implies more bandwidth, etc.
(ii) Clock synchronicity issues should be fixed. Indeed, in the current system, clocks between the Teensy and the laptop tend to get out of sync which results in potential sample dropouts. Even though those are fairly rare, they can impact sound quality on the long run.
(iii) Ultimately we’d like to try this system with a large speaker array such as the one available on the CCRMA stage.
Visits
Stanford, Fall 2023
Romain Michon, Tanguy Risset, and Pierre Cochard visited Stanford in October 2023 for 7 days. During this trip, they gave a half day workshop on the Syfala toolchain developed within Emeraude as well as two research seminars on the work carried out as part of PLASMA. Stanford hired an intern (Richard Berrebi) to work on PLASMA for a period of 6 months. Members of Emeraude spent time with him to get him started on the project. Multiple meetings took place to discuss future directions for the project.

Lyon, July 2023
Mike Mulshine (PhD student at Stanford) visited Emeraude for one week in July to work on real-time audio DSP on FPGA platforms in the context of PLASMA. This lead to the development of a prototype “PureData to FPGA compiler” allowing us to program FPGAs directly using the high-level PureData environment. This will potentially lead to a publication.
Stanford, Spring 2023
Romain Michon and Maxime Popoff visited Stanford in the Spring of 2023 (April – June). Romain Michon holds a lecturer positon at CCRMA and taught a class and did research in the context of PLASMA. Maxime Popoff was a visiting researcher and worked on PLASMA as well. His trip was partly funded by the France-Stanford Center.
Lyon, December 2022
Fernando Lopez-Lezcano visited Emeraude in Lyon at the beginning of December 2022 to work with French members of the PLASMA team as well as participating in the 2022 Programmable Audio Workshop organized by Emeraude.
Stanford, October 2022
Romain Michon, Tanguy Risset, and Maxime Popoff of the Emeraude INRIA team visited CCRMA at the end of October 2022 to work on PLASMA with Chris Chafe, Fernando Lopez-Lezcano, Julius O. Smith and others. This was the first in-person meeting of the project during which:
- We had multiple work sessions,
- PLASMA was presented during the CCRMA open house,
- Some of the work of the INRIA Emeraude Team was presented in the context of the CCRMA colloquium,
- A technical talk on Syfala was given during Julius O. Smith’s DSP seminar.

Publications
[PU1] Michon, Romain, Joseph Bizien, Maxime Popoff, and Tanguy Risset. “Making Frugal Spatial Audio Systems Using Field-Programmable Gate Arrays.” In Proceedings of the 2023 New Interfaces for Musical Expression Conference (NIME-23), Mexico City (Mexico), 2023.
[PU2] Rushton, Thomas Albert, Romain Michon, and Stéphane Letz. “A Microcontroller-Based Network Client Towards Distributed Spatial Audio.” In Proceedings of the 2023 Sound and Music Computing Conference (SMC-23), Stockholm (Sweden), 2023.
Bibliography
[OR0] Rumsey, Francis. Spatial Audio. Taylor & Francis, 2001.
[OR1] Malham, David G., and Anthony Myatt. “3-D Sound Spatialization Using Ambisonic Techniques.” Computer Music Journal 19, no. 4 (1995): 58-70.
[OR2] Berkhout, Augustinus J. “A Holographic Approach to Acoustic Control.” Journal of the Audio Engineering Society 36, no. 12 (1988): 977-995.
[OR3] Belloch, Jose, José M. Badía, Diego F. Larios, Enrique Personal, Miguel Ferrer, Laura Fuster, Mihaita Lupoiu, Alberto Gonzalez, Carlos Léon, Antonio M. Vidal, and Enrique S. Quintana-Ortí. “On the Performance of a GPU-Based SoC in a Distributed Spatial Audio System.” Journal of Supercomputing 77, no. 4 (2021): 6920-6935.
[OR4] Theodoropoulos, Dimitris, Georgi Kuzmanov, and Georgi Gaydadjiev. “Multi-core Platforms for Beamforming and Wave Field Synthesis.” IEEE Transactions on Multimedia 13, no. 2 (2011): 235-245.
[OR5] Lecomte, Pierre. “Ambitools: Tools for Sound Field Synthesis With Higher Order Ambisonics – v1.0.” In Proceedings of the International Faust Conference (IFC-18), Mainz (Germany), 2018.
[OR6] Heller, Aaron, Eric Benjamin, Richard Lee. “A Toolkit for the Design of Ambisonic Decoders.” In Proceedings of the Linux Audio Conference (LAC-12), Stanford (USA), 2012.
[OR7] Orlarey, Yann, Stéphane Letz, Dominique Fober. “FAUST : an Efficient Functional Approach to DSP
Programming.” Editions Delatour France. New Computational Paradigms for Computer Music (2009): 65-96.
[OR8] Popoff, Maxime, Romain Michon, Tanguy Risset, Yann Orlarey and Stéphane Letz. “Towards an FPGA-Based Compilation Flow for Ultra-Low Latency Audio Signal Processing.” In Proceedings of the Sound and Music Computing Conference (SMC-22), Saint-Étienne (France), 2022.
[OR9] Michon, Romain, Yann Orlarey, Stéphane Letz, and Dominique Fober. “Real-Time Audio Ddigital Signal Processing With Faust and the Teensy.” In Proceedings of the Sound and Music Computing Conference (SMC-19), Malagà (Spain), 2019.