Team STARS (Spatio-Temporal Activity Recognition of Social interactions) focuses on the long-term spatio-temporal interactions performed by humans in their natural environment. Our objective is to propose new algorithms to analyze human behavior. Deep learning techniques are highly successful for simple action recognition, nevertheless several important challenges remain in activity recognition in general.
Application in psychiatry. Specifically for our target medical application domain, we will work closely with our clinical partners. We have a strategic partnership named CoBTeK between STARS and the clinicians of Institut Claude Pompidou (ICP) and the university hospitals of Université Côte d’Azur at Lenval and Pasteur (CHU de Nice). Our objective to deepen research in social interaction is motivated by the needs of our clinician partners. A typical use-case of social interactions observed by sensors appears in the clinical assessments of psychiatric patients, such as people suffering from conditions like major depression, bipolar disorder, or schizophrenia. In these clinical assessments, interactions between the patient and the clinician are recorded with multi-modalities, i.e., with video, audio, and physiological sensors. The goal is to improve the treatment of behavioral disorders using video understanding approaches for the cognitive disorders by extracting digital markers (defined by formal interaction models), which are indicators of digital phenotypes. Patient-clinician interactions can last over an hour and the clinical annotations are highly subjective, which requires us to design new weakly-supervised learning algorithms. Our algorithms propose digital markers characteristic of the pathologies to the clinician who then evaluates their validity and decides upon further assessment. We recently carried out this process during experiments with children suffering from autistic spectrum disorders. Physiological signals as an additional modality for detecting stress. Monitoring of stress levels could play a major role in the prevention of stress-related issues, and early stress detection is vital in patients exhibiting emotional disorders, or in high-risk jobs such as surgeons, pilots or long-distance drivers. Building robust and reliable models for stress identification requires, among others, integrating the relationships between physical and physiological responses to stress. An essential element to such analyses is high-quality and versatile multimodal datasets that include varied categories of stressors, and are recorded on large and diverse populations. Our multimodal dataset StressID of audiovisual and physiological data is designed specifically for the identification of stress from different triggers, by using a guided breathing task, 2 video clips, 7 different interactive stressors, and a relaxation task. It is composed of 65 subjects and more than 39 hours of annotated data in total. StressID uses a collection of wearable sensors to record the physiological responses of the participants, namely, an Electrocardiogram (ECG), an Electrodermal Activity (EDA) sensor, and a respiration sensor. The work is now being extended into recognizing emotions and symptoms of psychiatric disorders.
Physiological signals as an additional modality for detecting stress. Monitoring of stress levels could play a major role in the prevention of stress-related issues, and early stress detection is vital in patients exhibiting emotional disorders, or in high-risk jobs such as surgeons, pilots or long-distance drivers. Building robust and reliable models for stress identification requires, among others, integrating the relationships between physical and physiological responses to stress. An essential element to such analyses is high-quality and versatile multimodal datasets that include varied categories of stressors, and are recorded on large and diverse populations. Our multimodal dataset StressID of audiovisual and physiological data is designed specifically for the identification of stress from different triggers, by using a guided breathing task, 2 video clips, 7 different interactive stressors, and a relaxation task. It is composed of 65 subjects and more than 39 hours of annotated data in total. StressID uses a collection of wearable sensors to record the physiological responses of the participants, namely, an Electrocardiogram (ECG), an Electrodermal Activity (EDA) sensor, and a respiration sensor. The work is now being extended into recognizing emotions and symptoms of psychiatric disorders. Social interaction as a new study target. Conversations play a central role in our lives – be it during family gatherings, business meetings, or in study groups. How people interact in conversations has a significant impact on interaction outcomes. If a shy person does not speak up during a brainstorming session, valuable ideas might be overlooked, and if discussions escalate and become personal, the group may not be able to solve its tasks efficiently. One of the most ambitious, but also most promising, ways to support humans in conversations is via an artificial mediator. This interactive intelligent agent actively engages in conversations in a human-like way to positively influence their course and outcomes. We attempt to contribute to realising the vision of autonomous artificial mediators by measurable advances in key conversational behaviour sensing and analysis tasks. Tro major tasks are body behavior detection and engagement estimation.
Social interaction as a new study target. Conversations play a central role in our lives – be it during family gatherings, business meetings, or in study groups. How people interact in conversations has a significant impact on interaction outcomes. If a shy person does not speak up during a brainstorming session, valuable ideas might be overlooked, and if discussions escalate and become personal, the group may not be able to solve its tasks efficiently. One of the most ambitious, but also most promising, ways to support humans in conversations is via an artificial mediator. This interactive intelligent agent actively engages in conversations in a human-like way to positively influence their course and outcomes. We attempt to contribute to realising the vision of autonomous artificial mediators by measurable advances in key conversational behaviour sensing and analysis tasks. Tro major tasks are body behavior detection and engagement estimation.

Weakly supervised anomaly detection in long untrimmed videos. The proliferation of surveillance cameras in public spaces highlights an escalating demand for autonomous systems adept at video anomaly detection and anticipation. Critical anomalies such as theft, vandalism, and accidents, despite their infrequency, play a pivotal role in safeguarding public security. The foremost challenge in this domain lies in pinpointing anomalous events within untrimmed video streams, a task traditionally reliant on frame-level annotations. However, such detailed labeling is resource-intensive and infeasible for expansive datasets. Weakly supervised video anomaly detection emerges as a compelling solution by predicting frame-level anomaly scores using only coarse-grained video-level labels, thereby circumventing exhaustive annotations. While current methods excel at identifying large-scale scene anomalies like explosions or traffic accidents through training on diverse video datasets, their effectiveness diminishes for intricate, human-centric anomalies such as shoplifting, theft, or abuse. These scenarios demand a nuanced understanding of human interactions and subtle actions, which current video-only approaches often fail to capture. To bridge this gap, we advocate integrating multimodal data encompassing pose estimation, depth information, panoptic segmentation, optical flow, and language semantics. These modalities enrich scene representation by detailing human motion, spatial relationships, dynamic movements, and contextual narratives.
Real-World Activity Recognition. Toyota Smarthome introduces a paradigm shift with a large-scale, multimodal dataset that mirrors the challenges of daily living, offering a scientifically rigorous benchmark for advancing activity recognition research. This dataset comprises 16,115 video clips across 31 daily activities, performed naturally and unscripted by 18 senior subjects (aged 60–80) in a smart home equipped with 7 Kinect cameras. Activities were recorded over eight hours and annotated with both coarse and fine-grained labels, providing a rich, nuanced dataset with RGB, depth, and 3D skeleton modalities. The dataset presents several key scientific challenges. One major issue is the high intra-class variation, as natural and unscripted human activities tend to differ significantly from instance to instance. Additionally, class imbalance poses a difficulty: activities appear with varying frequency, mirroring their real-world distribution rather than being evenly represented. The dataset’s multimodal complexity adds another layer of challenge, with fine-grained labels that require distinguishing between subtly different actions, such as drinking from a cup versus a bottle. Moreover, the data was collected under dynamic conditions, including changes in camera angles, subject distances, and frequent occlusions, all of which challenge the robustness of recognition models. Lastly, temporal diversity must be addressed, as activity durations vary widely, from brief actions like sitting down to prolonged tasks such as cooking. To address these challenges, we propose a pose-driven spatiotemporal attention mechanism implemented with 3D ConvNets. This novel approach achieves state-of-the-art results on both Toyota Smarthome and other benchmark datasets, demonstrating superior robustness and accuracy in recognizing complex, real-world activities. Toyota Smarthome redefines activity recognition benchmarks, offering a scientifically challenging and authentic testbed to bridge the gap between theoretical models and real-world applications.
Multi-object tracking. This computer vision task involves tracking people or objects across video while maintaining consistent IDs. Applications include surveillance, automated behavior analysis or autonomous driving.Tracking-by-detection methods use bounding boxes to detect objects in each frame and associate them with those from previous frames, based on cues like position, appearance and motion. The resulting matches form tracklets over consecutive frames. Segmentation mask-based methods, on the other hand, generate masks to cover objects and track them across video frames. Trained on large datasets, these methods aim to capture the semantics of image patches, making them more generic. We explore using a temporally propagated segmentation mask as an association cue to assess its effectiveness. We propose a novel tracking-by-detection method that combines mask propagation and bounding boxes to improve the association between tracklets and detections. The mask propagation is managed according to the tracklet lifespan, while the mask is used in a controlled manner to enhance tracking performance.![]()
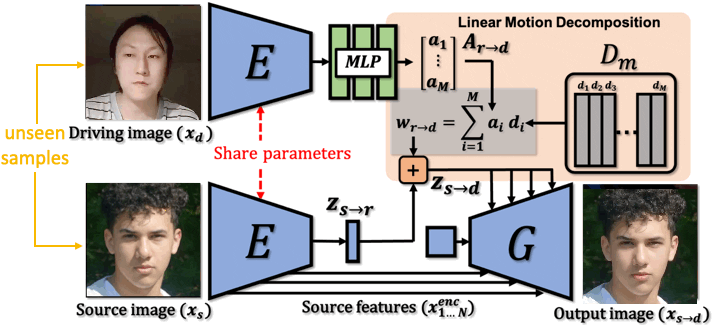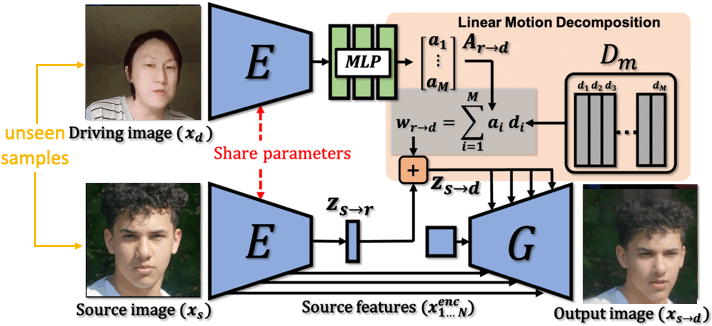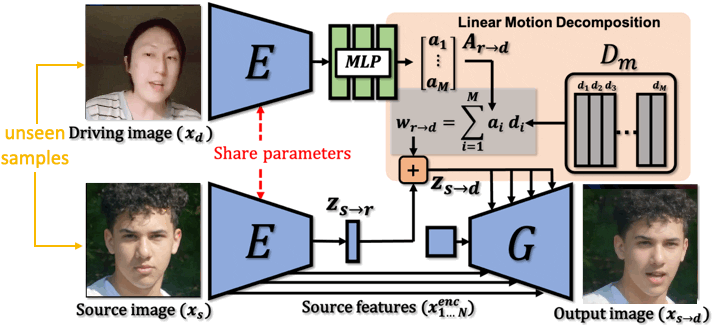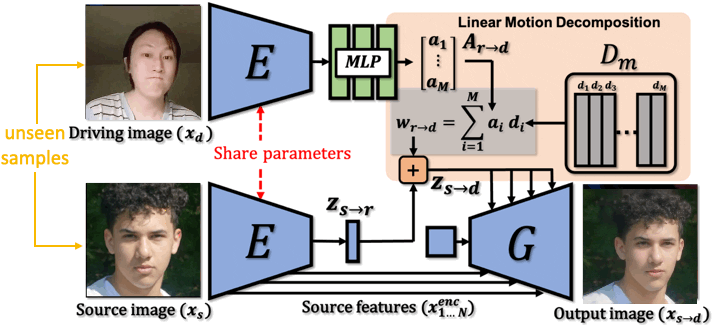
Video generation. We aim to apply data generation models in two domains of application, namely data augmentation and data anonymization. Deep generative models such as Generative Adversarial Networks and Diffusion Models have witnessed remarkable success, catapulting general video generation to being able to synthesize photorealistic videos directly from text description. Generating videos from a single image, i.e., image animation, has also gained significant attention due to real-world applications including filmmaking, digital humans, and art creation. We focus on talking head generation that aims at animating facial images, placing emphasis on generation of realistic appearance and motion. While video-driven talking head generation has become highly realistic, animation driven by audio-speech is more challenging, as it entails the animation of a face image by synchronizing the audio-speech to lip motion, as well as head pose and facial expression, as such facial behavior is crucial in human communication. Generated videos provide a promising solution to the unsatiability of deep neural networks in their need for training data. Generated data is easier to obtain, it is inexhaustible, pre-annotated, and less expensive. In addition, synthetic data has the potential to avoid ethical and privacy concerns, as well as practical issues related to security. Synthetic data brings to the fore unique opportunities, allowing for the surgical injection of training data in scenarios where collecting real data may be impractical or impossible, such as talking dogs or faces that do not exist.