



by Xiaoyu Lin, Laurent Girin and Xavier Alameda-Pineda
Introduction
Multi-object tracking (MOT), or multi-target tracking, is a fundamental and very general pattern recognition task. Given an input time-series, the aim of MOT is to recover the trajectories of an unknown number of sources, that might appear and disappear at any point in time. There are four main challenges associated to MOT, namely: (i) extracting source observations (also called detections) at every time frame, (ii) modeling the dynamics of the sources’ movements, (iii) associating observations to sources consistently over time, and (iv) accounting for birth and death of source trajectories.
In computer vision, the tracking-by-detection paradigm has become extremely popular in the recent years. In this context, more and more powerful detection algorithms brought a significant increase of performance. Including motion information also improves the tracking performance. Among the tracking approaches based on motion models, the linear dynamical model (i.e., constant object velocity) is the most commonly used. Further, it makes sense to combine the detection and tracking models together.
While a linear dynamical model is suitable in case of high sampling rate and reasonable object velocity, challenging tracking scenarios with low sampling rate, moving camera, high object velocity, rapid changes of direction, and occlusions are still difficult to tackle with such simple models, thus leading to numerous tracking errors such as false negatives and identity switches. The powerful sequential modeling capabilities of RNNs can help to design more accurate motion models, provided we have enough annotated data to train them. Since obtaining annotations in the MOT framework is a very tedious and resource-consuming task, it is worth investigating the training of complex motion/MOT models in an unsupervised manner, i.e., without human-annotated data.
In this paper, we present an unsupervised probabilistic model and associated estimation algorithm for multi-object tracking (MOT) based on a dynamical variational autoencoder (DVAE), called DVAE-UMOT. The DVAE is a latent-variable deep generative model that can be seen as an extension of the variational autoencoder for the modeling of temporal sequences. It is included in DVAE-UMOT to model the objects’ dynamics, after being pre-trained on an unlabeled synthetic dataset of single-object trajectories. Then the distributions and parameters of DVAE-UMOT are estimated on each multi-object sequence to track using the principles of variational inference: Definition of an approximate posterior distribution of the latent variables and maximization of the corresponding evidence lower bound of the data likehood function. DVAE-UMOT is shown experimentally to compete well with and even surpass the performance of two state-of-the-art probabilistic MOT models. Code and data are publicly available.
Model overview
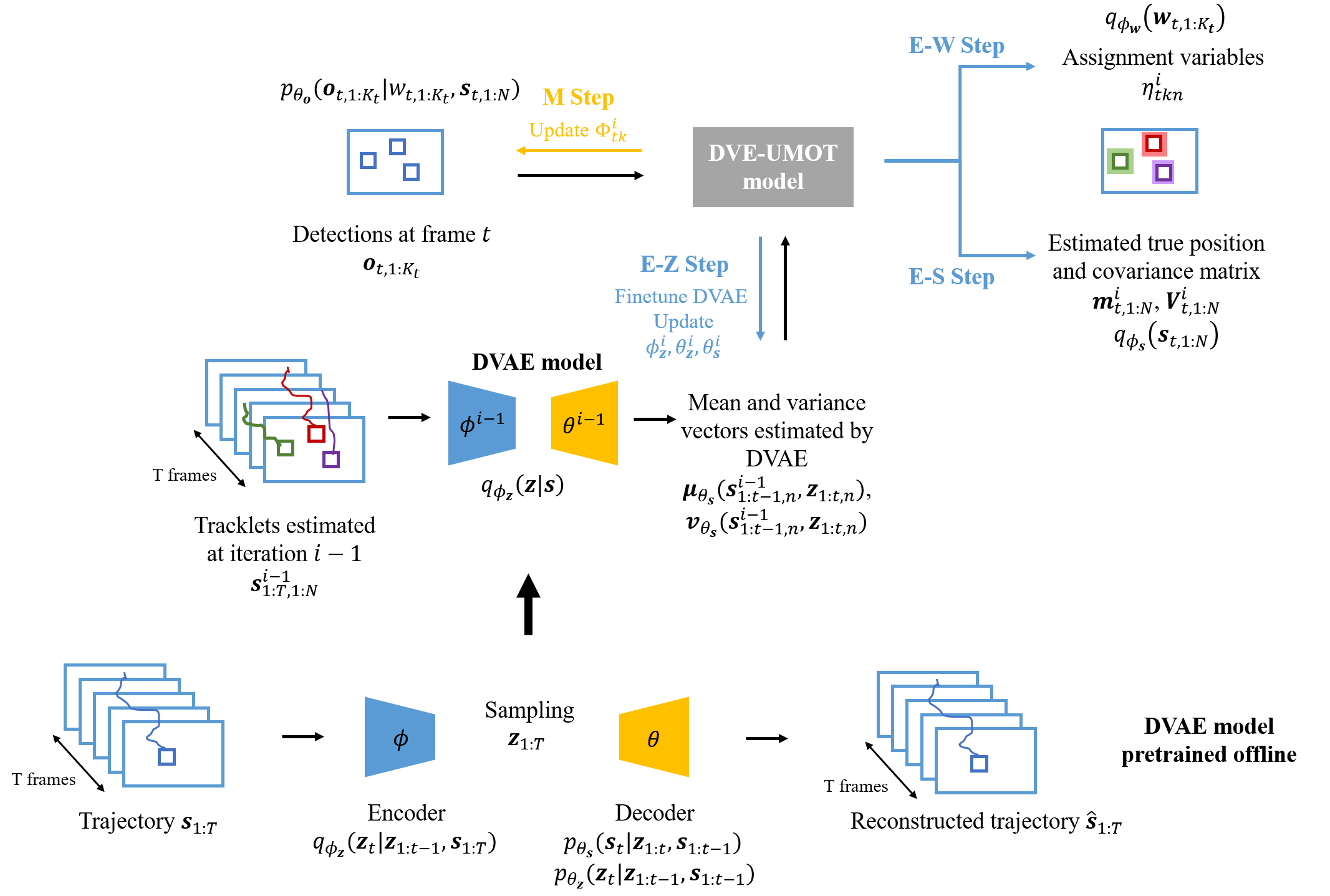
DVAE-UMOT model overview
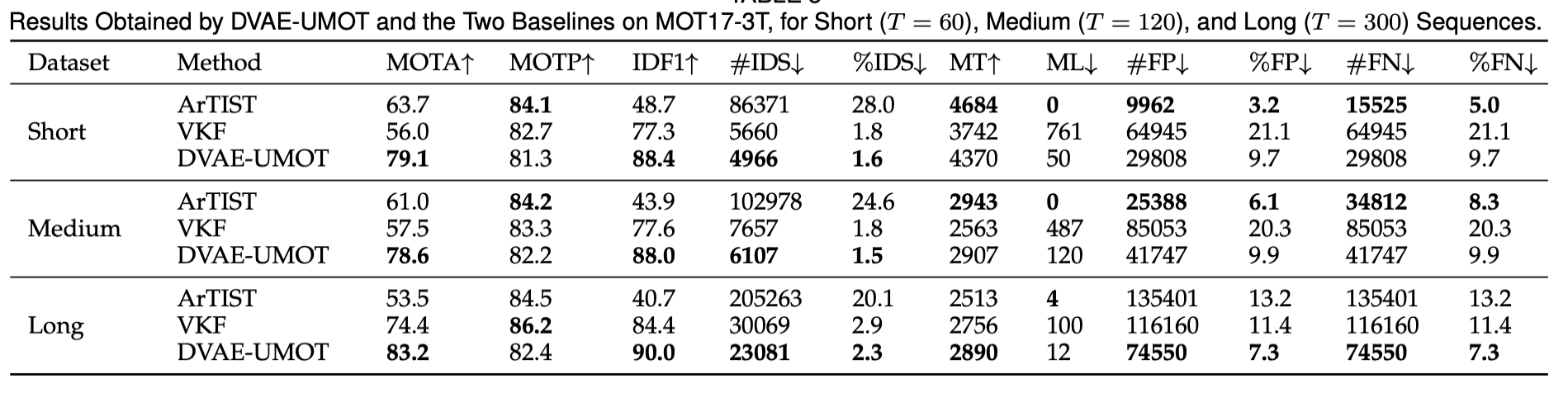
Model Evaluation
We evaluated our method on a dataset derived from the publicly available multi-object-tracking dataset MOT17, which is called MOT17-3T. This dataset contains three sub dataset, with three different sequence lengths: 60, 120 and 300 frames respectively. Each sample in the dataset contains three tracking targets. And the SDP detection which is provided by the MOT17 dataset is used.
Tracking Examples
![]()
![]()
![]()