



IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
Volume 38, number 12, pages 2402 – 2415, December 2016
Abstract. Data clustering has received a lot of attention and numerous methods, algorithms and software packages are available. Among these techniques, parametric finite-mixture models play a central role due to their interesting mathematical properties and to the existence of maximum-likelihood estimators based on expectation-maximization (EM). In this paper we propose a new mixture model that associates a weight with each observed point. We introduce the weighted-data Gaussian mixture (WD-GMM) and we derive two EM algorithms. The first one considers a fixed weight for each observation (FWD-EM). The second one treats each weight as a random variable following a gamma distribution (WD-EM). We propose a model selection method based on a minimum message length criterion, provide a weight initialization strategy, and validate the proposed algorithms by comparing them with several state of the art parametric and non-parametric clustering techniques. We also demonstrate the effectiveness and robustness of the proposed clustering technique in the presence of heterogeneous data, namely audio-visual scene analysis.
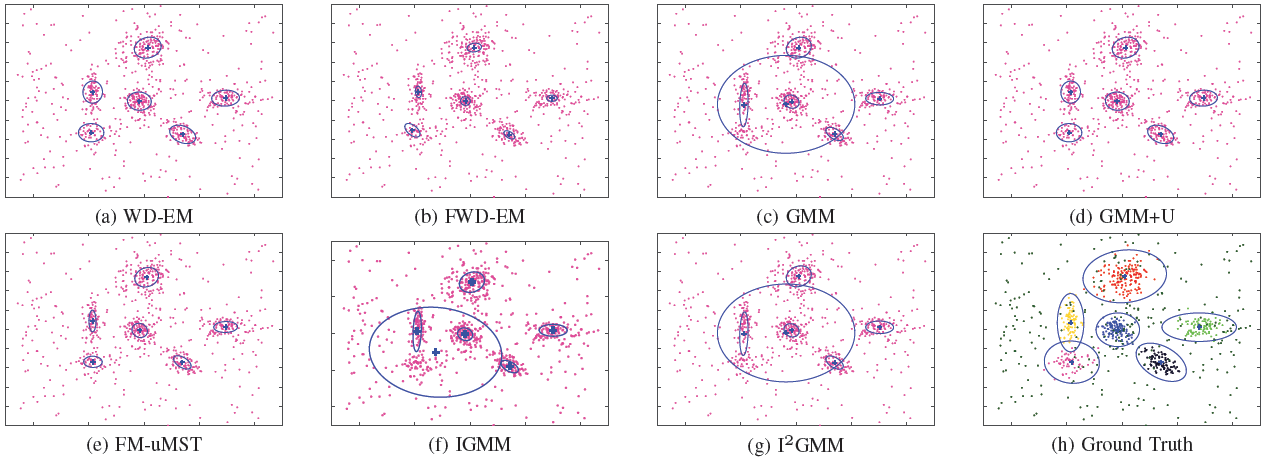
Clustering results obtained with various mixture models and in the presence of 50% of outliers. The proposed algorithms (WD-EM and FWD-EM) are compared with the standard Gaussian mixture model (GMM), with a mixture of GMM and a uniform distribution (GMM+U), with the finite mixture of unrestricted multivariate skew t-distribution (FM-uMST), infinite GMM (IGMM) and infinite mixtures of IGMM (I2GMM).
BibTeX
@article{gebru2015algorithms,
author={Gebru, I.D. and Alameda-Pineda, X. and Forbes, F. and Horaud, R.},
journal={IEEE Transactions on Pattern Analysis and Machine Intelligence},
title={{EM} Algorithms for Weighted-Data Clustering with Application to Audio-Visual Scene Analysis},
VOLUME = {38},
NUMBER = {12},
PAGES = {2402 - 2415},
YEAR = {2016},
MONTH = Dec,
doi={10.1109/TPAMI.2016.2522425},
}
Code and Dataset
We used AVTrack-1 dataset for Audio-Visual scene analysis. The dataset can be found HERE. A Matlab package containing the proposed EM algorithms can be downloaded from HERE. The package contains code for WD-EM with model selection, WD-EM without model selection and FWD-EM. The code files are self-contained.
Videos
|
Moving Speakers (MS) |
|
|
Two persons that move around while they are always facing the cameras and microphones. The persons take speech turns but there is a short overlap between the two auditory signals. |
|
|
Cocktail Party (CP) |
|
|
Three persons engaged in an informal dialog. The persons wander around and turn their heads towards the active speaker; occasionally two persons speak simultaneously. Moreover the speakers do not always face the camera, hence face and lip detection/localization are unreliable. |
|
|
Fake Speaker (FS) |
|
|
Two persons facing the camera and the microphones. While the person onto the right emits speech signals (counting from “one” to “ten”) the person onto the left performs fake lip, facial, and head movements as he would speak. |
|
Related Publications
[A] Gebru, I. D., Ba, S., Evangelidis, G., & Horaud, R., “Audio-Visual Speech-Turn Detection and Tracking”. LVA/ICA 2015. Webpage
[B] Gebru, I. D., Ba, S., Evangelidis, G., & Horaud, R., “Tracking the Active Speaker Based on a Joint Audio-Visual Observation Model”. ICCV 2015. Webpage
[C] Gebru, I. D., Alameda-Pineda, X., Horaud, R., & Forbes, F., “Audio-visual speaker localization via weighted clustering”. MLSP 2014. Webpage
[D] Gebru, I.D., Ba, S., X. Li, & Horaud, R. “Audio-Visual Speaker Diarization Based on Spatiotemporal Bayesian Fusion”. TPAMI Dec 2016. Webpage
Acknowledgements
This research has received funding from the EU-FP7 STREP project EARS (#609465) and ERC Advanced Grant VHIA (#340113).