



Contents
Online Localization and Tracking of Multiple Moving Speakers in Reverberant Environments
Xiaofei Li*, Yutong Ban*, Laurent Girin, Xavier Alameda-Pineda and Radu Horaud
IEEE Journal of Selected Topics in Signal Processing, 2019, 13 (1), pp.88-103.
| pdf from arXiv | IEEEXplore | code | dataset
Abstract. We address the problem of online localization and tracking of multiple moving speakers in reverberant environments. The paper has the following contributions. We use the direct-path relative transfer function (DP-RTF), an interchannel feature that encodes acoustic information robust against reverberation, and we propose an online algorithm well suited for estimating DP-RTFs associated with moving audio sources. Another crucial ingredient of the proposed method is its ability to properly assign DP-RTFs to audio-source directions. Towards this goal, we adopt a maximum-likelihood formulation and we propose to use the exponentiated gradient (EG) to efficiently update source-direction estimates starting from their currently available values. The problem of multiple speaker tracking is computationally intractable because the number of possible associations between observed source directions and physical speakers grows exponentially with time. We adopt a Bayesian framework and we propose a variational approximation of the posterior filtering distribution associated with multiple speaker tracking, as well as an efficient variational expectation maximization (VEM) solver. The proposed online localization and tracking method is thoroughly evaluated using two datasets that contain recordings performed in real environments.
Example results
Scenario: two speakers are simultaneously and continuously speaking.
Localization spatial spectrum

The proposed localization results |
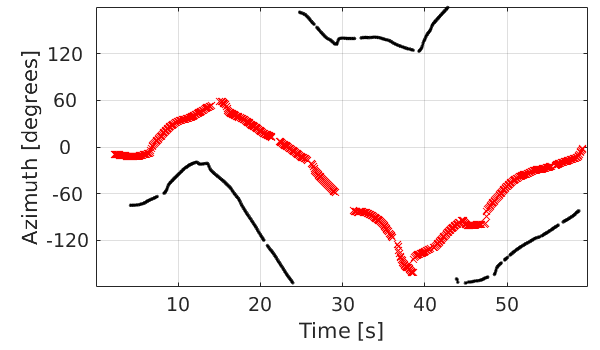
The proposed tracking results |
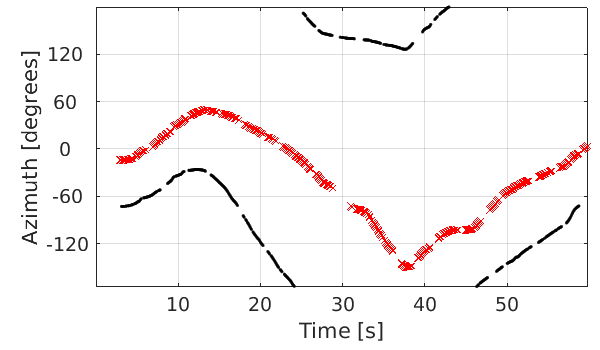
Ground truth trajectories |
(*Different colors represent different speakers)
Kinovis-MST dataset
Scenario: three speakers are moving and chatting freely.
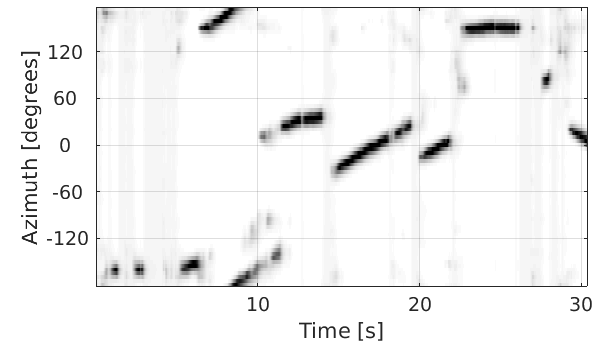
The proposed localization results |
The proposed tracking results |
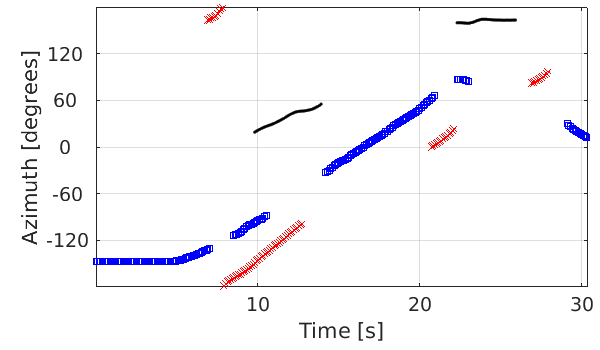
Ground truth trajectories |
Kinovis-MST dataset
|
|
The Kinovis acoustic multiple speaker tracking dataset(Kinovis-MST) was recorded in the Kinovis multiple-camera laboratory at INRIA Grenoble. The room size is 10.19 m × 9.87 m × 5.6 m, with T 60 ≈ 0.53 s. A v5 NAO robot with four microphones was used. Four quasi-planar microphones are located on the top of the robot head. The speakers were moving around the robot with a speaker-to-robot distance ranging between 1.5 m and 3.5 m. A motion capture system was used to obtain ground-truth trajectories of the moving participants and the location of the robot. Ten sequences were recorded with up to three participants, for a total length of about 357 s. The robot’s head has built-in fans located nearby the microphones, hence the recordings contain a notable amount of stationary and spatially correlated noise with an SNR of approximatively 2.7 dB. The participants behave naturally, i.e. they take speech turns in a natural multi-party dialogue. When one participant is silent, he/she manually hides the infrared marker located on his head to make it invisible to the motion capture system. This provides ground-truth speech activity information for each participant. This dataset and the associated annotations allow the users to test the audio source localization and tracking algorithms when the number of active speakers varies over time. |
Acknowledgments: This work is funded by the European Union ERC Advanced Grant VHIA #340113 (X. Li, Y. Ban, X. Alameda-Pineda, and R. Horaud).