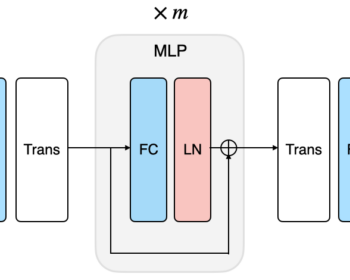
Speech Modeling with a Hierarchical Transformer Dynamical VAE

by Xiaoyu Lin, Xiaoyu Bie, Simon Leglaive, Laurent Girin, and Xavier Alameda-Pineda IEEE International Conference on Acoustics, Speech and Signal Processing 2023 [paper][code] Abstract: The dynamical variational autoencoders (DVAEs) are a family of latent-variable deep generative models that extends the VAE to model a sequence of observed data and a…