Context
Passwords are widely used for user authentication and, despite their weaknesses, will likely remain in use in the foreseeable future. As operational security is a subject that is gaining momentum among the public, passwords are getting somewhat stronger. Rainbow tables or brute force based attacks are less and less useful, because both the passwords are improving, and the hashing functions have evolved. But, as complex passwords are harder to remember, we can assume that more and more people use more predictible passwords. Containing personal information, about hobbies, family, etc. We can use tools such as WordHound (https://bitbucket.org/mattinfosec/wordhound) to gather such probable passwords by crawling the always enriching social media. What is needed today is a tool to exploit such data for password cracking. PRINCE was recently released by the Hashcat team with that goal (https://github.com/jsteube/princeprocessor). OMEN+ is a password guesser based on several publications. The algorithm was devised by the Privatics team and the Ruhr University Bochum. It works much like PRINCE, while being quite different fundamentally. It uses Markov models to output password candidates in order of decreasing probability, thus providing faster results.
Goals
The goal of the OMEN+ project is to develop a Markov model based tool to analyze the structure of leaked passwords. This tool is able to use personal information to influence the Markov model in order to better fit to a specific target. The tool should be usable on regular desktop machines, so that penetration testers, system administrators, and government agencies can use it. It should be reliable, and easily extensible.
Participants involved
- Inria Privatics team
- Claude Castelluccia
- Pierre Rouveyrol
- Ruhr-Universität Bochum
- Markus Dürmuth
- Previous Participants
- Abdelberi Chaabane (Inria)
- Daniele Perito (Inria)
- Fabian Angelstorf (RUB)
Results
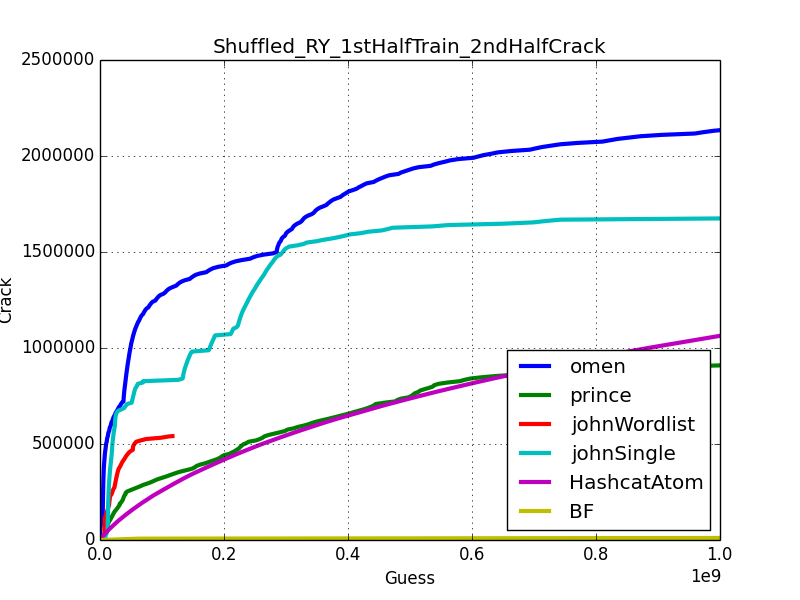
Despite lacking enough personal information to use Omen+ as intended, we can get an idea of how it compares to other tools using large cleartext wordlists. We used Rockyou. Doublons were removed and the list was shuffled then split in two equal parts. We then tried to guess passwords from the second part while using the first part as training set.
We used Matt Weir’s tool Checkpass2 : https://github.com/lakiw/Password_Research_Tools And the following
Commands :
- ./john -wordlist=./rockyou1.txt -rules=single -stdout | python2 checkpass2.py -t rockyou2.txt -m 1000000000 > john_ry1VSry2.result
- ./princeprocessor/src/pp5_10.bin rockyou1.txt | python2 checkpass2.py -t rockyou2.txt -m 1000000000 > prince_ry1VSry2.result
- ./omen+ -min 5 -max 10 rockyou1.txt | python2 checkpass2.py -t rockyou2.txt -m 1000000000 > omen_ry1VSry2.result