
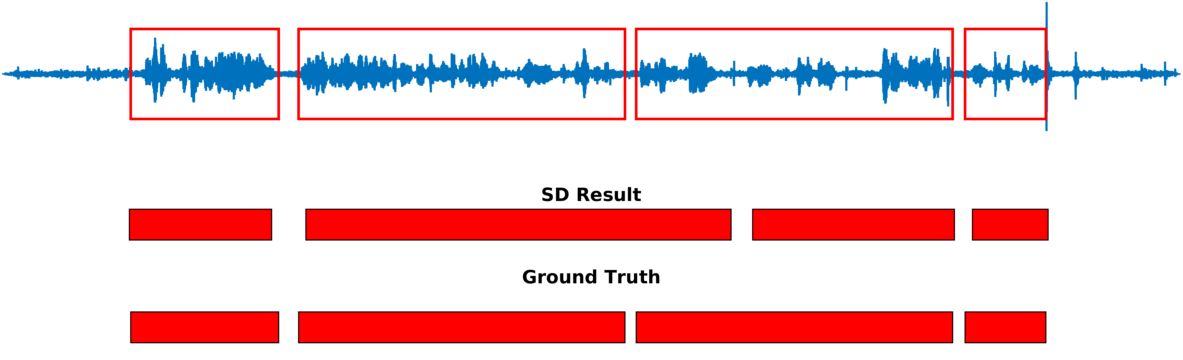
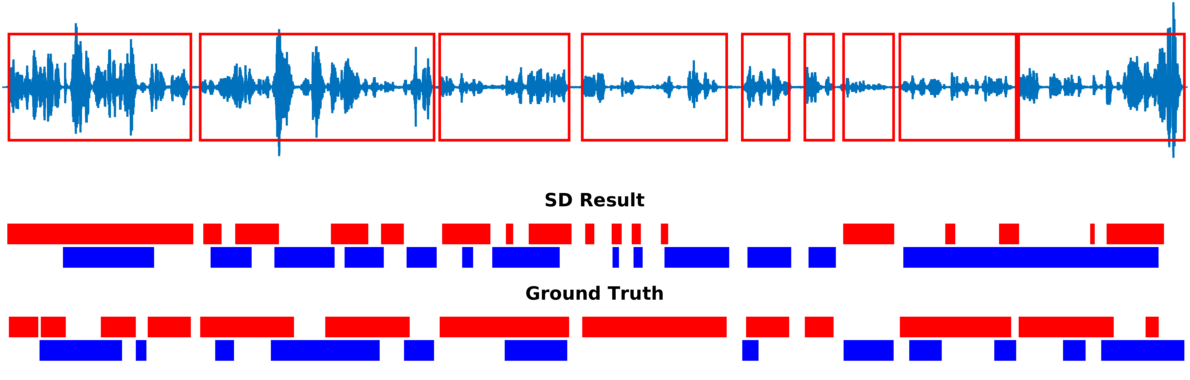
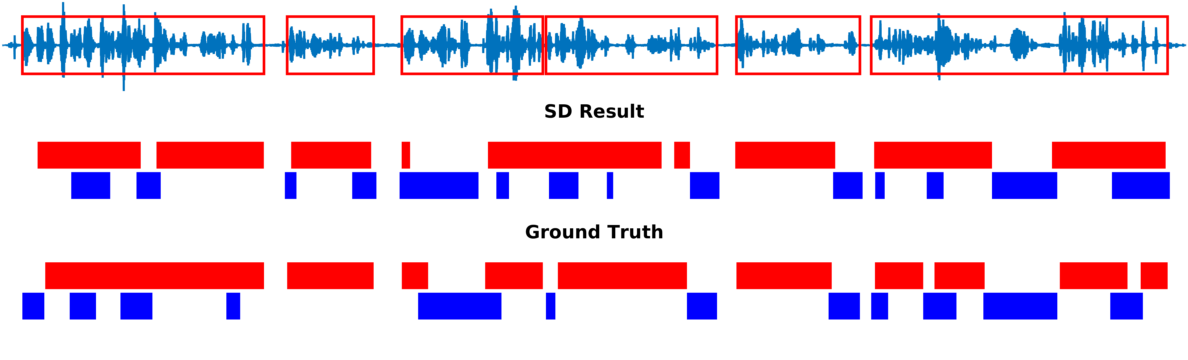
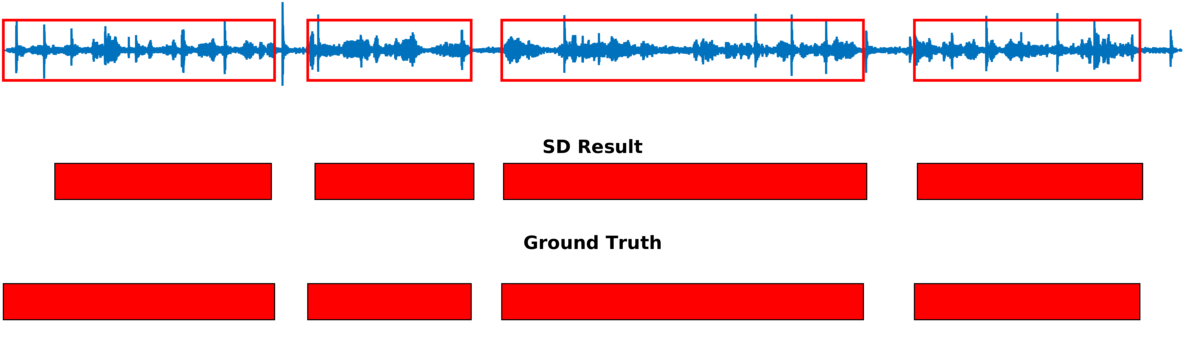
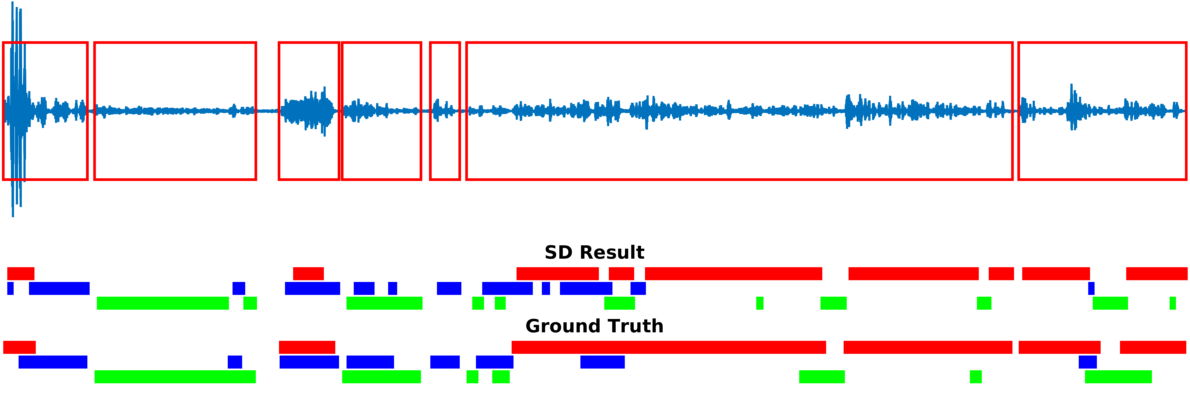
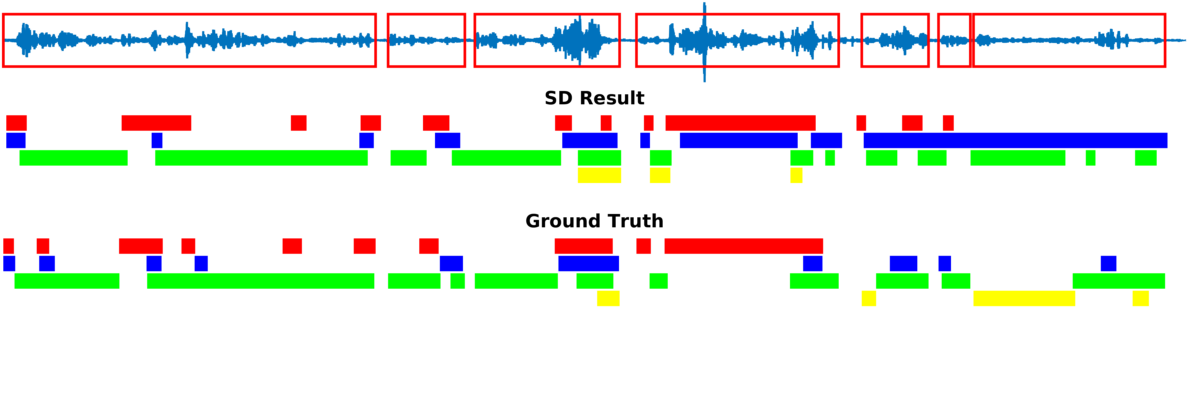
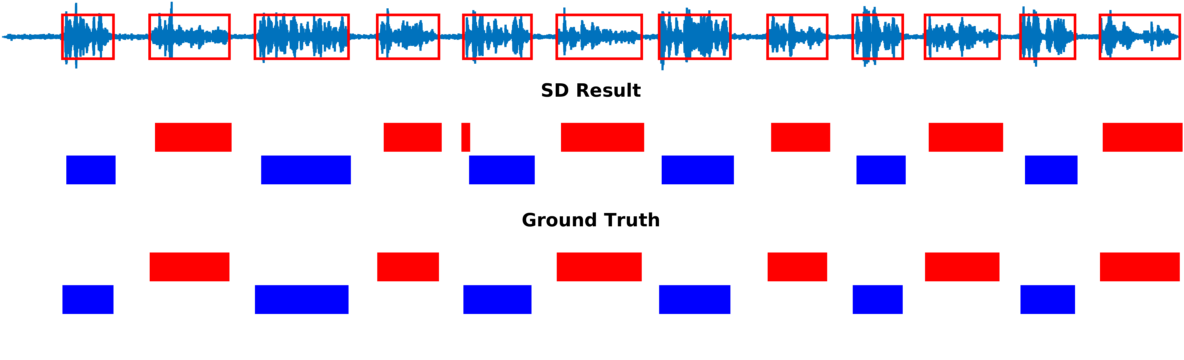
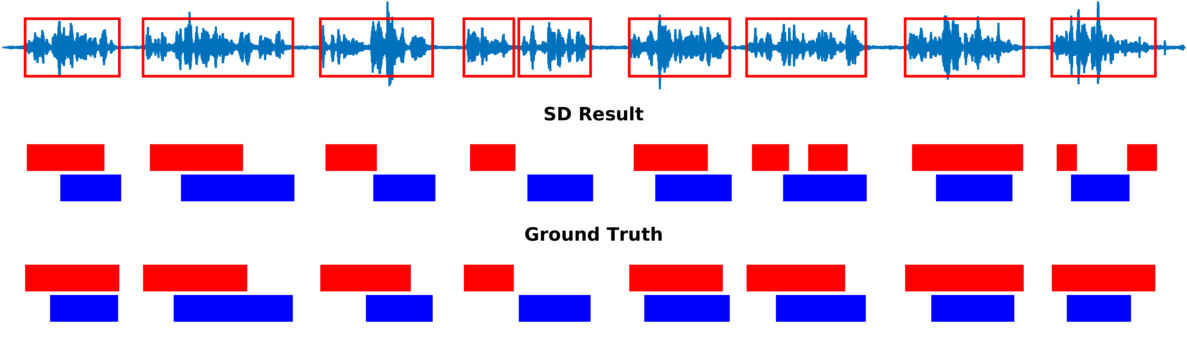
Speaker diarization consists of assigning speech signals to speakers engaged in dialog. We proposed audio-visual spatiotemporal diarization model that tracks multiple persons and assigns acoustic signals to each person (please visit our research page for more details). Below are some of our results on AVDIAR dataset. The digit displayed on top of a person head represents the “person identity” as maintained by a visual tracker. The probability that a person speaks is shown as a heat map overlaid on the person’s face. The hot colors represent the most probable speaker. The figures on the right show:
- the raw audio signal delivered by the left microphone and the speech activity region is marked with red rectangles.
- SD Result: speaker diarization result illustrated with a color diagram: each color corresponds to the speaking activity of a different person.
- Ground Truth: annotated ground-truth diarization.
| Seq01-1P-S0M1 | |
 |
|
| Seq20-2P-S1M1 | |
 |
|
| Seq21-2P-S1M1 | |
 |
|
| Seq22-1P-S0M1 | |
 |
|
| Seq27-3P-S2M1 | |
 |
|
| Seq32-4P-S1M1 | |
 |
|
| Seq37-2P-S0M0 | |
 |
|
| Seq40-2P-S1M0 | |
 |
|
| Seq44-2P-S2M0 | |
 |
|