
“The deepest parts of [data transformation] are totally unknown to us. No soundings have been able to reach them. What goes on in those distant depths? What [data and transformations] inhabit, or could inhabit, those regions […]? What is the constitution of these […]? It’s almost beyond conjecture.” A slightly altered version of an excerpt of Jules Verne’s 20,000 Leagues under the Sea, Chapter II.
Database developers may formulate a thought similar to the one above when designing or modifying database applications that derive data by applying queries or, in general, transformations to source data. Indeed, using declarative languages such as SQL to specify queries, developers often face the problem that they cannot properly inspect or debug their query or transformation code. All they see is the tip of the iceberg once the result data is computed. If it does not comply with the developers’ expectation, they usually perform one or more tedious and mostly manual analyze-fix-test cycles until the expected result occurs. The goal of Nautilus is to support developers in this process by providing a suite of algorithms and tools to accompany the process.
The high-level architecture of Nautilus depicted below shows the main components that support each phase of the test-analyze-fix development cycle. Users interact with Nautilus via a graphical user interface (GUI). The current implementation of Nautilus is in form of an Eclipse plugin. In the following, we briefly discuss the goal of each component within the test-analyze-fix cycle.
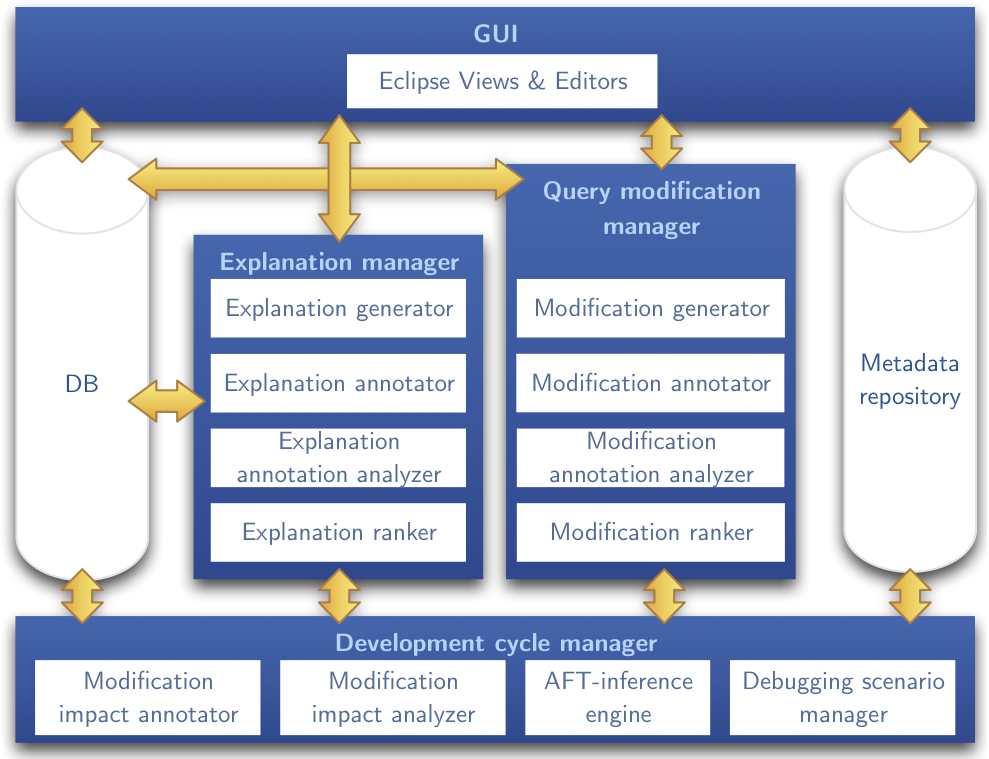
Analyze (Explanation Manager)
New: watch the Nautilus Analyzer in action in the following video: Nautilus Analyzer video
Given a data transformation, Nautilus allows developers to analyze what is going on below the surface, and thus serves as a debugging tool for queries or data transformation processes. To this end, Nautilus generates so called explanations (explanation generator). Intuitively, explanations describe why result data of a transformation exists (related to data lineage/data provenance), or why expected data may be missing. Explanations are computed based on the data transformation itself as well as on the actual instance data.
Currently, Nautilus allows developers to analyze SQL queries by asking the question of why some data was produced (why-provenance) and why some data a developer expected is not in the result of a query (why-not provenance). The explanations Nautilus produces using the Artemis algorithm [2,3], explain missing data in terms of the source data (instance-based explanations), but we also support explanations that consist of data transformation operators (query-based explanations), and we will soon support explanations that combine both (hybrid explanations).
When returning explanations to a user, these are ranked so that, intuitively, the most interesting explanations are displayed first (explanation ranker). The developer can then mark explanations as relevant and irrelevant (explanation annotator) and based on these annotations, Nautilus infers further annotations to avoid computing and displaying unnecessary explanations to the developer, or to improve ranking (explanation annotation analyzer).
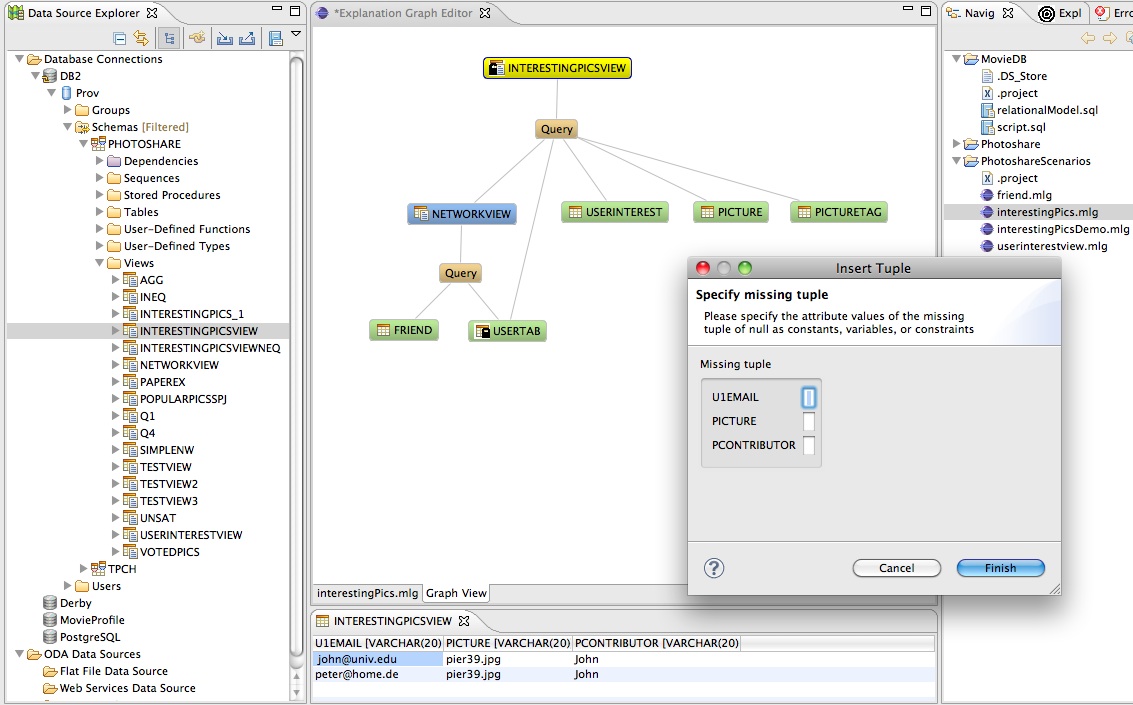 |
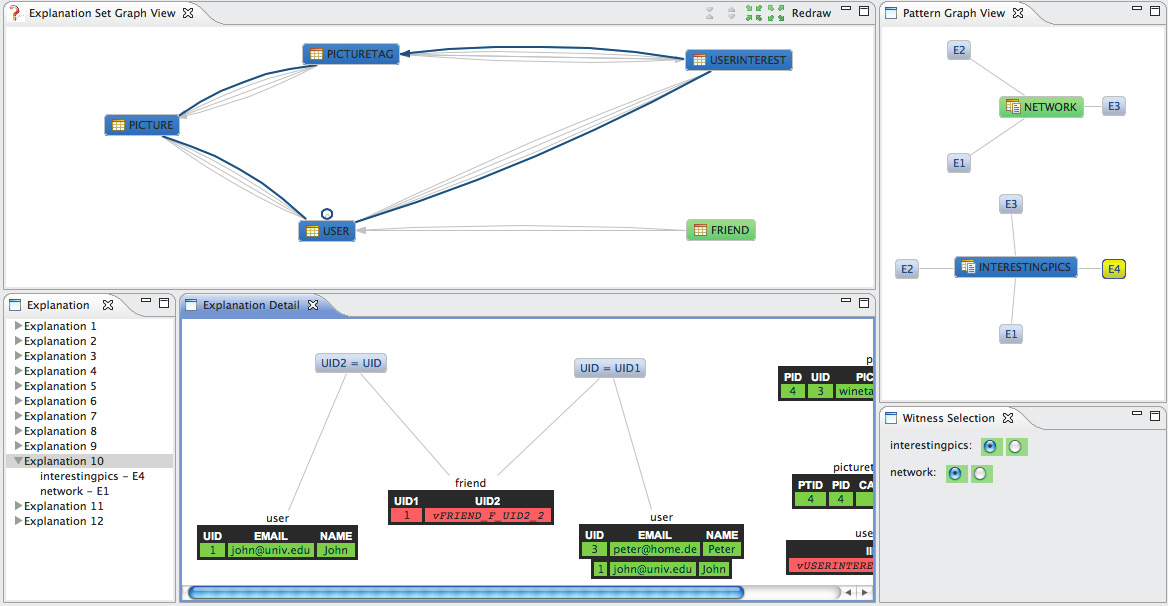 |
| Input configuration (click image for larger version): what queries and missing tuples should be explained by instance-based explanations? | Explanation navigator (click image for larger version): through different views, navigate through the set of returned instance-based explanations. |
Fix (Query Modification Manager)
Explanations allow developers to better understand the queries and transformations they formulate. But Nautilus will go even further as we plan to generate sensible suggestions to repair the analyzed transformations, thus supporting the fixing phase of the previously manual analyze-fix-test cycle.
The computation of query modifications (modification generator) is based on explanation and their annotations, as determined during the analysis phase. Given a set of explanations and annotations, many modifications are in principal possible, but some make more sense than others. For instance, correcting a join into an outer join is more likely to be correct than replacing a join by a cross product. Based on such heuristics, Nautilus ranks query modifications (modification ranker) before displaying them to the user. Similarly to explanations, a developer can review and annotate query modifications (modification annotator). Based on these annotations, further knowledge is inferred (modification annotation analyzer).
Test (Development Cycle Manager)
Based on suggested modifications, the developer devises a new query that becomes the new version of the data transformation. However, it is possible that further errors in the query remain, or that the last modification was in fact not a correct one. Therefore, Nautilus has to keep track of changes that occur during the development cycle and needs to notify the user of the impact his query modifications have (modification impact analyzer). The developer can then decide whether the observed impact is acceptable or not (modification impact annotator).
Based on annotations a developer provides during the development process, the initially stated problem, the debugging scenario may change over time (debugging scenario manager). Also, as a developer follows the analysis-fix-test process, new global knowledge may be acquired by Nautilus that influences different components (AFT-inference engine).
Current team members
- Melanie Herschel (team lead, Associate Professor, U Paris Sud)
- Nicole Bidoit (Full Professor, U Paris Sud)
- Katerina Tzompanaki (PhD student, U Paris Sud)
- Alexandre Constantin (Engineer, CNRS)
Former members
- Tim Belhomme (Research staff member 2011, U Tübingen)
- Abhishek Choudhari (Summer intern 2012, INRIA)
- Hanno Eichelberger (Engineer, U Tübingen)
- Mathilde Verrier (Summer intern 2013, U Paris Sud)
Publications
- Immutably Answering Why-Not Questions for Equivalent Conjunctive Queries (to appear)
Nicole Bidoit, Melanie Herschel, Katerina Tzompanaki
USENIX Workshop on the Theory and Practice of Provenance (TAPP), Cologne, Germany, 2014. - Query-Based Why-Not Provenance with NedExplain
Nicole Bidoit, Melanie Herschel, Katerina Tzompanaki
International Conference on Extending Database Technology (EDBT), Athens, Greece, 2014. - Wondering Why Data are Missing from Query Results? Ask Conseil Why-Not (also available: long version)
Melanie Herschel
Proceedings of the International Conference on Information and Knowledge Management (CIKM), San Francisco, USA, 2013. - Answering Why-Not Questions
Nicole Bidoit, Melanie Herschel, Katerina Tzompanaki
Bases de Données Avancées (BDA), Nantes, France, 2013. - The Nautilus Analyzer – Understanding and Debugging Data Transformations
Melanie Herschel, Hanno Eichelberger
Proceedings of the International Conference on Information and Knowledge Management (CIKM), Maui, USA, 2012. - Transformation Lifecycle Management with Nautilus (also available: slides)
Melanie Herschel, Torsten Grust
Proceedings of the International Workshop on Quality in Databases (QDB), collocated with VLDB, Seattle, USA, 2011. - Explaining Missing Answers to SPJUA Queries (also available: slides)
Melanie Herschel, Mauricio A. Hernández
Proceedings of the VLDB Endowment, Volume 3, September 2010. - Artemis: A System for Analyzing Missing Answers (also available: poster)
Melanie Herschel, Mauricio A. Hernández, Wang Chiew Tan
Proceedings of the VLDB Endowment, Volume 2, August 2009.
Talks
Invited Talks
- Why-Not Data Provenance
Université Paris Dauphine, 22. November 2013 - The Nautilus Query Analyzer
UC San Diego, 23. May 2013 - Le pourquoi du comment de données… et pourquoi.
Journée du LRI, 26. Jun. 2012 - TLM – Transformation Lifecycle Management (Slides)
- Technical University Dresden, 30. May 2011
- Leo Seminar, INRIA Saclay, 28. March 2011
- Transformation Lifecycle Management mit Nautilus (Slides in German)
IBM Böblingen, 17. Feb. 2011 - Query Analysis with Nautilus (Movie*)
- Max-Planck-Institute for Biological Cybernetics, Tübingen, 25. Nov. 2009
- DIMA Kolloquium, Technical University Berlin, 23. Nov. 2009
Conference talks
- Query-Based Why-Not Provenance with NedExplain
Katerina Tzompanaki at EDBT 2014. - Wondering why data are missing from query results? Ask Conseil Why-Not
Melanie Herschel at CIKM 2013. - Answering Why-Not Questions
Katerina Tzompanaki at BDA 2013. - Transformation Lifecycle Management with Nautilus (slides)
Tim Belhomme at the QDB Workshop in conjunction with VLDB 2011. - Explaining Missing Answers to SPJU Queries (slides)
Melanie Herschel at VLDB 2010.
*Movies are QuickTime exports of the presentation slides and include the original slide animations. When viewed with the QuickTime Player, viewers can advance through the slideshow by clicking the mouse or pressing Play (in the QuickTime controls), or by pressing the Space bar on the keyboard.
![]() Research on Nautilus is supported by the Baden-Württemberg Stiftung
Research on Nautilus is supported by the Baden-Württemberg Stiftung