
Notre Recherche
La quantité d’information disponible dans le web aujourd’hui, et le rythme auquel l’information est créée est un fardeau pour la majorité des utilisateurs, surtout les « cerveau-d’œuvre » dont le travail au quotidien est de digérer et transformer l’information. Le but de notre recherche est d’aider les utilisateurs à découvrir de nouveaux contenus pertinents dans le web . Un des moyens les plus puissants, aujourd’hui, pour aider les utilisateurs à découvrir de nouveaux contenus, est le partage d’information entre membres de communautés en ligne. Dans le cas de ce qu’on appelle les communautés d’endroit (des gens qui vivent, travaillent, ou étudient au même endroit), les gens ont souvent des intérêts communs, mais soit ils ne sont pas connectés, soit ils n’arrivent pas à s’engager activement à soumettre et relayer l’information. Afin de résoudre ce problème, nous avons développé WeBrowse, un système de découverte de contenu, basé sur le crowdsourcing passif, particulièrement adapté pour les communautés d’endroit.
![]()
Comment ça marche
WeBrowse se base sur l’observation passive des visites vers des pages du Web, comme indication de l’intérêt que portent les utilisateurs vers ces pages. Intuitivement, plus une page est visitée, plus elle est susceptible de susciter l’intérêt. Notre approche est donc de se baser sur les visites web collectives d’une communauté afin d’automatiquement inférer des contenus pertinents à promouvoir aux utilisateurs de la communauté.
Pour implémenter le crowdsourcing passif, nous devons être en position d’observer l’agrégat des clicks web de la communauté. Heureusement, dans la majorité des communautés d’endroit qui nous intéressent, les utilisateurs se connectent à l’Internet en utilisant le même réseau (réseau d’université, réseau d’entreprise, ou un point de collecte dans une zone résidentielle). WeBrowse (i) observe les pacquets de traffic web qui traversent un lien sur le réseau, (ii) extrait passivement les logs http (des flux enregistrant les headers des requêtes HTTP), et (iii) détecte et décide, en ligne, la liste de pages à monter aux utilisateurs
![]()
Collected data
WeBrowse lit le trafic HTTP (la partie non chiffrée du Web) qui traverse le lien qui connecte le réseau Inria Paris à l’Internet, et extrait :
- L’URLqui pointe vers la resource Web demandée
- Le champs “referrer” qui pointe vers la dernière page visitée
- Le champs “User-Agent” indiquant le navigateur utilisé
- Unaddresse IP anonymisée afin de distinguer les utilisateurs différents
Nous conservons les données anonymisées sur un serveur sécurisé à Inria de Paris. L’accès à ces données est reservé aux chercheurs dont la liste se trouve in contacts.
![]()
Protection de la vie privée
Nous comprenons que WeBrowse pourrait apprendre des informations sensibles sur les utilisateurs du réseau Inria Paris. Nous prenons donc les mesures nécessaires pour protéger la vie privée des utilisateurs:
- Toutes les adresses IP sont anonymisées au moment de la lecture. On ajoute une valeur numérique à l’adresse et on applique une fonction de hash. Après application de la fonction de hash, il est impossible d’inférer l’adresse IP originale.
- Nous éliminons les paramètres des URLs. Certaines URLs contiennent des paramètres qui peuvent servir à véhiculer des informations, des fois sur les préférences des utilisateurs. Par exemple, www.example.com?preference=rouge. Nous éliminons ces parameters.
- Nous appliquons la K-Anononymité. WeBrowse montre seulement des pages visitées par plusieurs utilisateurs. Cela garantit qu’il est impossible d’inférer quel utilisateur en particulier a visité un contenu promu sur le site de WeBrowse.
- Filtrage par blacklisting. Nous maintenant une liste d’URLs et de domaines qui sont inappropriés. Les utilisateurs peuvent nous suggérer des URLs ou des noms de domaine à bannir de WeBrowse.
![]()
Comment ne pas participer à l’expérimentation ?
Comme tout système à base de crowdsourcing, plus on a des utilisateurs qui contribuent à WeBrowse, la meilleure est la qualité des contenus de WeBrowse. Cependant, si vous préférez ne pas participer, vous pouvez le faire.
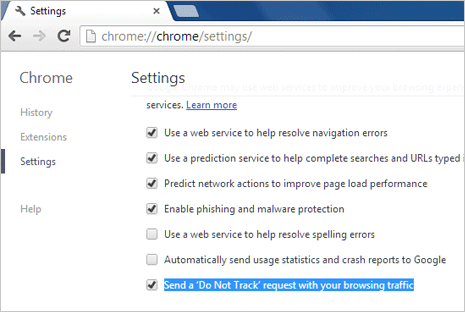
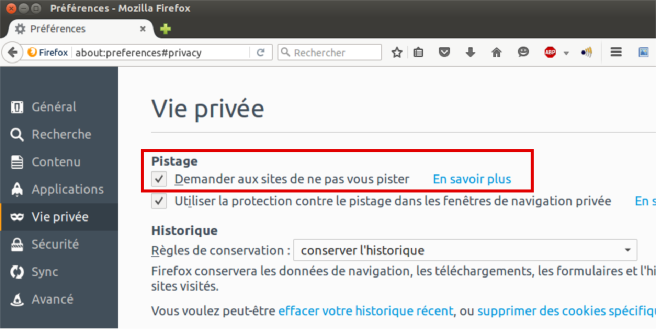
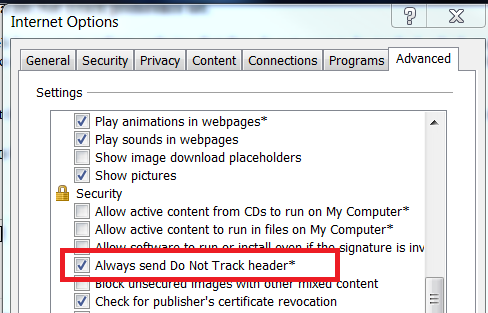
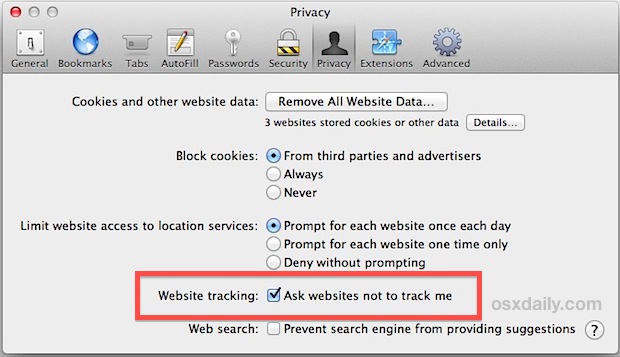
Pour cela, il suffit juste d’activer le bouton « Do Not Track » ou « Demander aux sites de ne pas vous pister » sur votre navigateur, et WeBrowse ignorera tout votre trafic.
Chrome
Firefox
Internet Explorer
Safari
![]()
Contacts
- Giuseppe Scavo PhD candidate, Inria, Nokia Bell Labs, France
- Zied Ben Houidi Researcher, Nokia Bell Labs, France
- Prof. Renata Teixeira, Inria, France
Pour nous contacter, envoyez un courriel à Renata.

